
AI and LLM Observability
Monitor, optimize, and secure Generative AI applications, LLMs, and agentic workflows — improving performance, explainability, and compliance.


Integrate and observe
Integrate and observe every AI stack layer — from user applications to LLMs and infrastructure — with native support for top AI platforms.
User facing frontend/backend app with end-user feedback (thumbs up/down, text feedback)
Advanced metrics & analysis (guardrails, chain performance, prompt caching, model usage)
Agent to Agent communication, protocol, command execution, tool usage, handover
Model token usage/cost, stability, latency, invocation errors, latency, resource utilization
RAG pipeline: data retrieval performance, accuracy LLM input and outputs, semantic analysis
Compute, GPU, network, resource monitoring

A Fortune 500 American financial services mutual achieved end-to-end observability across multiple LLMs and the applications they power in a single platform, eliminating blind spots and driving significant cost savings.


End-to-end observability for Agentic AI, Generative AI, and LLMs
Reduce cost and improve performance of your Agentic, AI and LLM stack
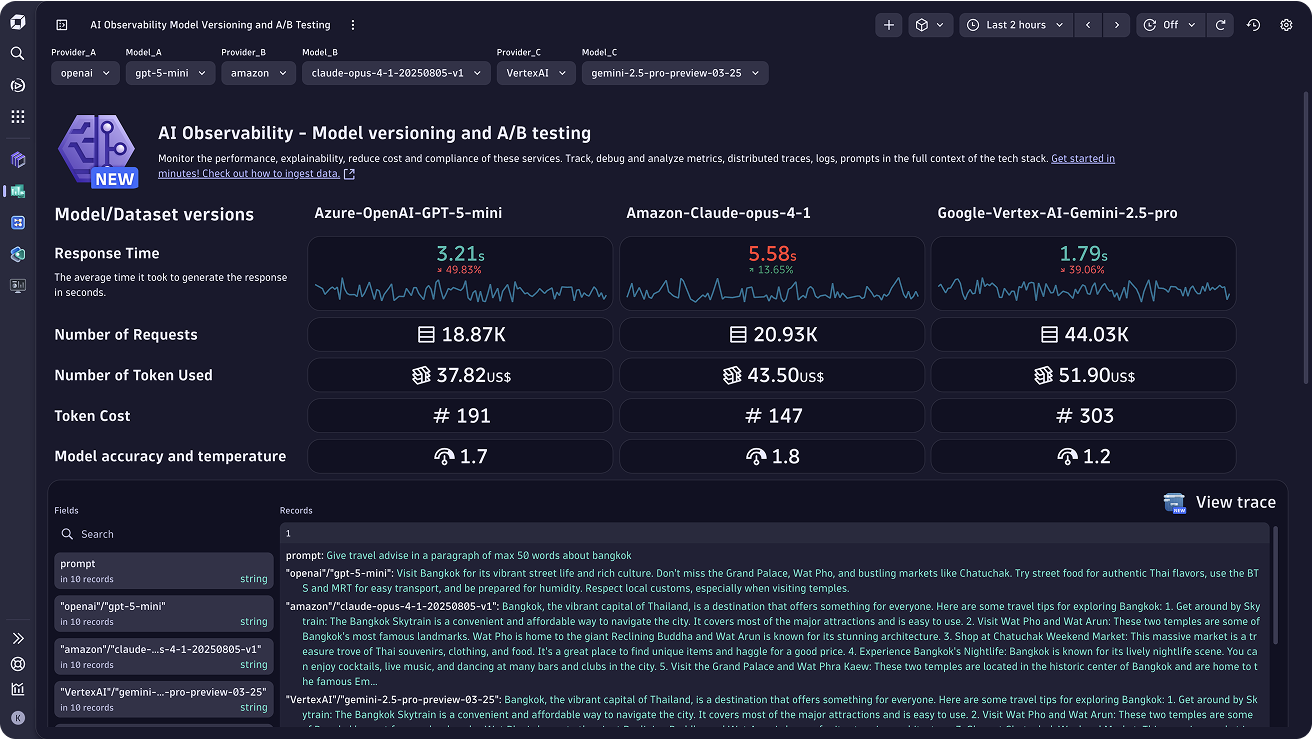
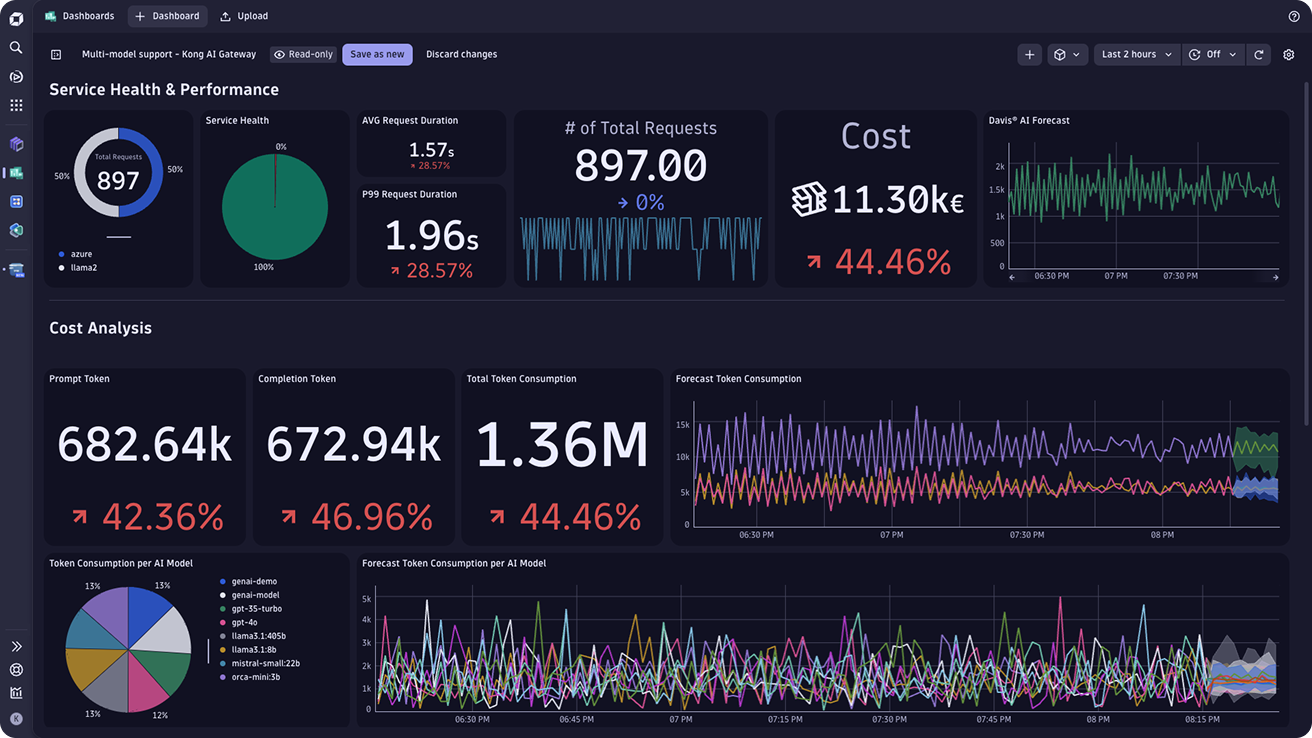
- Monitor operational metrics for Gen AI applications like token cost, request duration, problems, and problems with unified and customizable dashboards that drive proactive action
- Leverage Davis AI to detect changes in user behavior, predict cost increases, and proactively make changes to manage costs
- Reduce AI Agent and LLM response times and improve reliability by analyzing traces for the slowest requests and errors
- Compare different AI model performance with A/B testing insights to make informed decisions about which models to deploy in production.
Build trust, monitor guardrails of LLM input and output
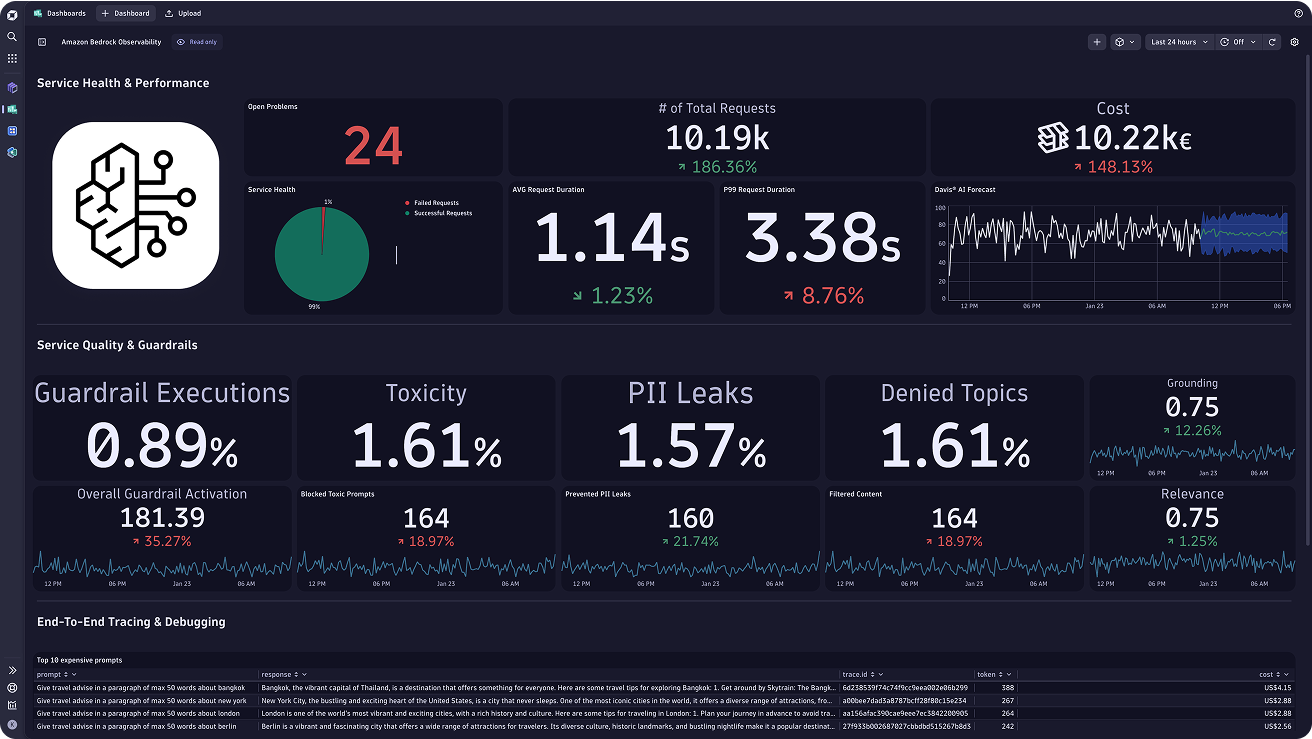
- Safeguard the quality of AI applications by monitoring and analyzing guardrail metrics to mitigate potential biases, errors, and misuse of AI systems
- Recognize model hallucinations, identify attempts at LLM misuse such as malicious prompt injection, prevent Personally Identifiable Information (PII) leakage, and detect toxic language
- Analyze the effectiveness of LLM guardrails and make necessary adjustments to ensure optimal user experience and safety
Explain, log and trace back your AI service outputs
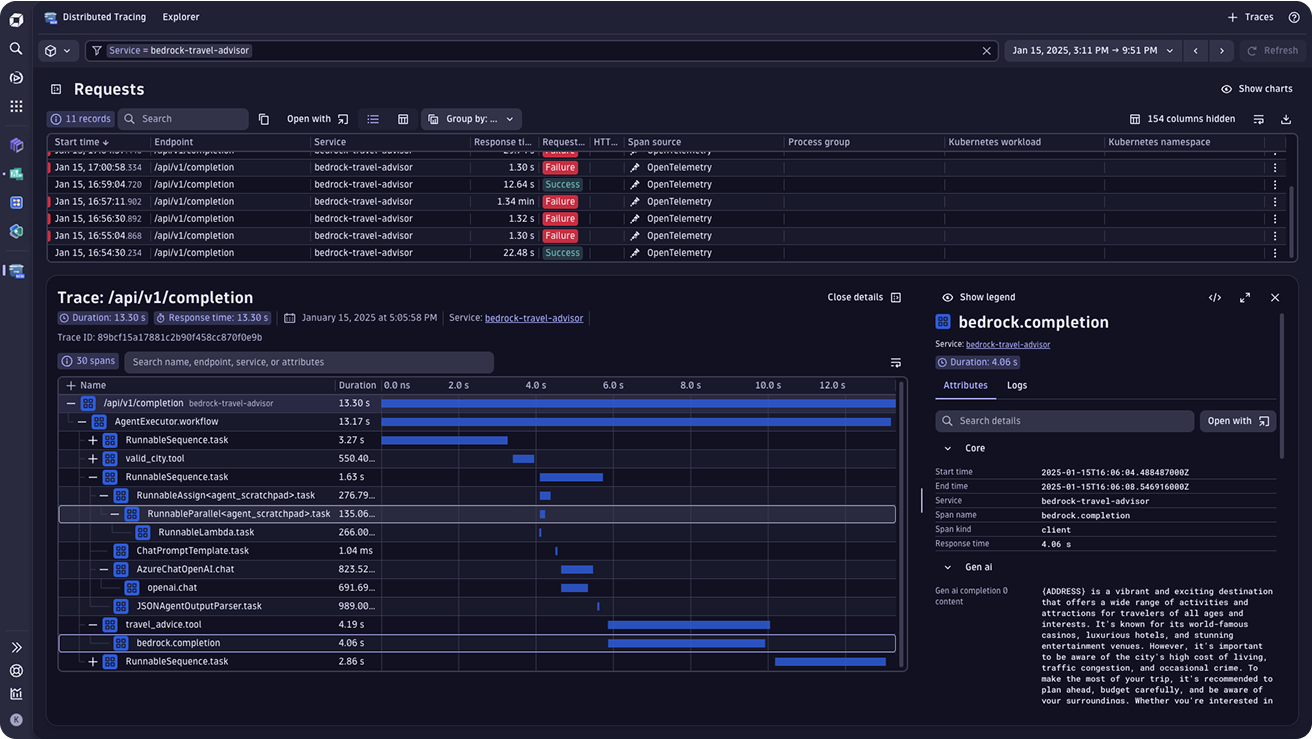
- Gain end-to-end visibility into the execution of each user request, with tracing, logs to cover the full application stack: frontend, backend, orchestrations, RAG, LLM and agentic layers
- Log, trace and map dependencies between your services, spanning across your architecture
- Leverage Davis AI to automatically pinpoint the root cause of errors and failures in the LLM chain and proactively accelerate resolution before impacting customers
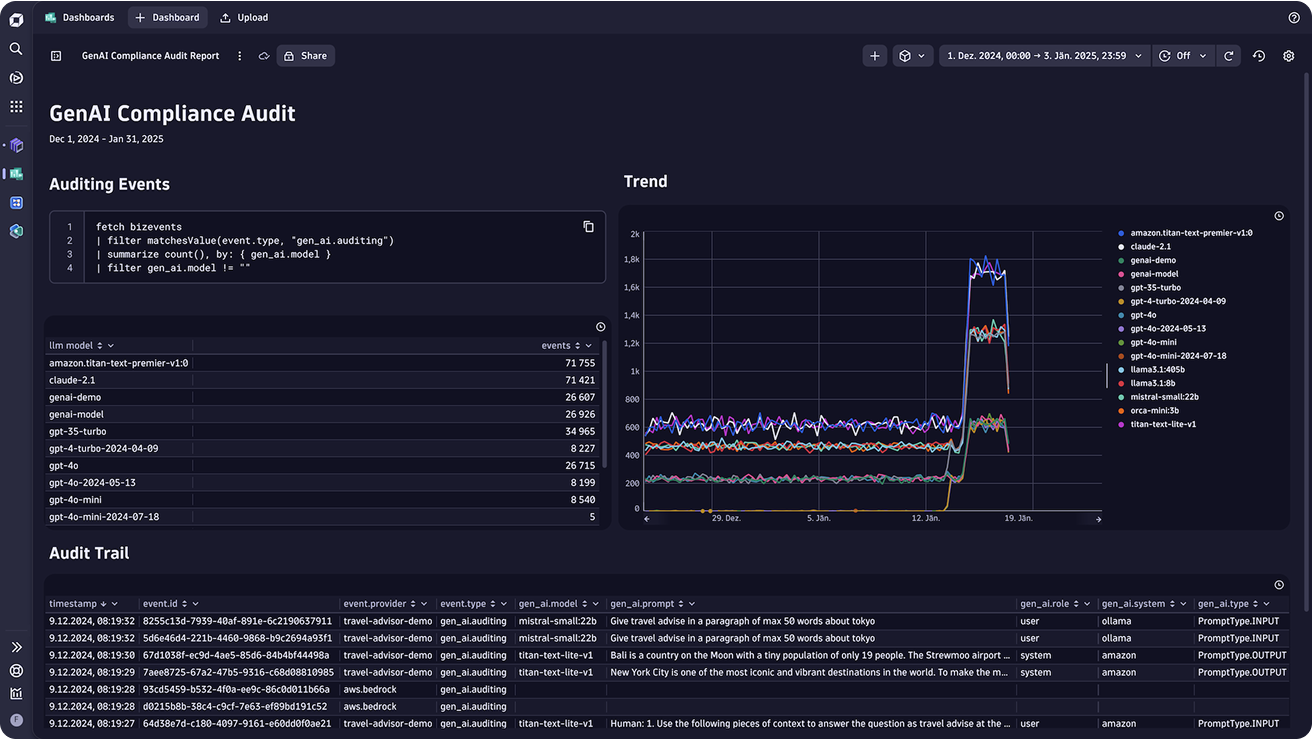
Reduce compliance risk and secure your GenAI applications
- Comprehensively and cost effectively document all inputs and outputs, maintaining full data lineage from prompt to response to build a clear audit trail to ensure compliance with regulatory standards
- Store up to 10 years all of your prompts
- Build dashboards to visualize the behavior and performance of AI systems to make their operation more transparent and prove compliance
- Support carbon-reduction initiatives by monitoring infrastructure data, including temperature, memory utilization, and process usage

Join the Dynatrace Partnership program




