
Dynatrace automatically detects all deployed applications that are monitored by OneAgent. It does so by analyzing the running processes, identifying which application each process supports, and subsequently mapping the processes to what we call a “process group” (one process group represents one application). It then automatically detects all microservices that are part of an application through a rich combination of domain knowledge and broad technology support.
Owing to this, Dynatrace can detect anything from Spring Boot-based REST services to business processes in IBM’s enterprise ESB. This works so fantastically well that we’ve integrated with ServiceNow to automatically populate its CMDB and literally put IT operations in autopilot mode.
Additional context levels up automatic service detection
Despite what some of our customers might think, Dynatrace isn’t relying on magic to do this, and there are circumstances where service detection lacks context, usually due to one of these cases:
- Missing information about a microservice because the technology doesn’t support it—for example, Node.js and Golang don’t have a formal concept of a context root.
- Missing information about the microservice because it wasn’t provided by the development team—for example, while Java has a formal concept of a web application ID, it isn’t always provided.
- Unavailable information about third-party microservices—for example, when you call a third-party web request, you can’t know its application ID or context root.
- Misuse of metadata by the development team, for example, adding the build date to the web application ID.
- Lack of full support by Dynatrace.
All these cases are about missing or incorrect information that would be required for high-precision service detection. Consequently, we’ve now released a service detection API that’ll enable you to supplement or correct the available information and, therefore, improve out-of-the-box detection by Dynatrace.
Use the service detection API to provide more context
While Dynatrace supports many kinds of microservices, the first iteration of this API is specifically about web requests and its derivations. There are currently four different types of service that you can configure via the new API. The first two are:
- Fully monitored web request services
These are web request services detected in a process or process group that is fully monitored via our OneAgent. Examples include a Java web Application or a Web Site deployed on Nginx. Dynatrace has full insight into its properties. - Fully monitored web services
Some web applications expose multiple services via REST or SOAP APIs. Dynatrace detects this based on its rich technology support for web service frameworks.
In the cases above, Dynatrace gathers a lot of information about the microservices, which the API allows you to supplement and adjust.
Additionally, Dynatrace detects third-party and external microservices. These are called opaque services in Dynatrace, because we know which processes they are hosted by but can’t see inside them. There are two flavors:
- Opaque or external web request services
These are either third-party web applications, applications currently not monitored by OneAgent, or applications based on currently unsupported technologies. - Opaque or external web services
Similarly, these are either third-party or unmonitored REST or SOAP web services that Dynatrace identifies via the technology stack used.
As these are not directly monitored by our OneAgent, we have less information. You can use the new API to provide the missing information and enhance service detection.
How to use the new API
The service detection API enables you to tell Dynatrace more about your services and thus improve how they are detected. Let’s look at some concrete examples:
- Separate services for “public network services” based on subdomains
- Separate services for “public network services” based on URL
- Separate services for “unmonitored hosts ” based on hostname or IP range
- Separate fully monitored web request services based on URL or imposed context root
Separate services for “public network services” based on subdomains
This was requested several times by customers and in our Product Ideas forum.
Currently, you can tell Dynatrace to monitor web requests to a particular domain as its own service. However, customers wanted the ability to have two separate services for domains, like support.dynatrace.com and blog.dynatrace.com. These represent different endpoints for different services and shouldn’t be combined.
To do this, you can now tell Dynatrace to include the full domain for all web requests to a domain, such as dynatrace.com. You create an OPAQUE_AND_EXTERNAL_WEB_REQUEST detection rule, by posting the following JSON API call to the endpoint api/config/v1/service/detectionRules/OPAQUE_AND_EXTERNAL_WEB_REQUEST.
{
"name": "Dynatrace.com",
"type": "OPAQUE_AND_EXTERNAL_WEB_REQUEST",
"description": "",
"enabled": true,
"conditions": [
{
"attributeType": "TOP_LEVEL_DOMAIN",
"compareOperations": [
{
"type": "ENDS_WITH",
"negate": false,
"ignoreCase": "true",
"values": [
"dynatrace.com"
]
}
]
}
],
"publicDomainName": {
"copyFromHostName": true
},
"port": {
"doNotUseForServiceId": true
}
}
This tells Dynatrace to use the full hostname of the web request instead of just dynatrace.com whenever it sees a third-party request to dynatrace.com. Earlier, you would get a single entry for service Requests to public networks. Based on the JSON call above, the rule now results in two services, one for support.dynatrace.com and one for blog.dynatrace.com.
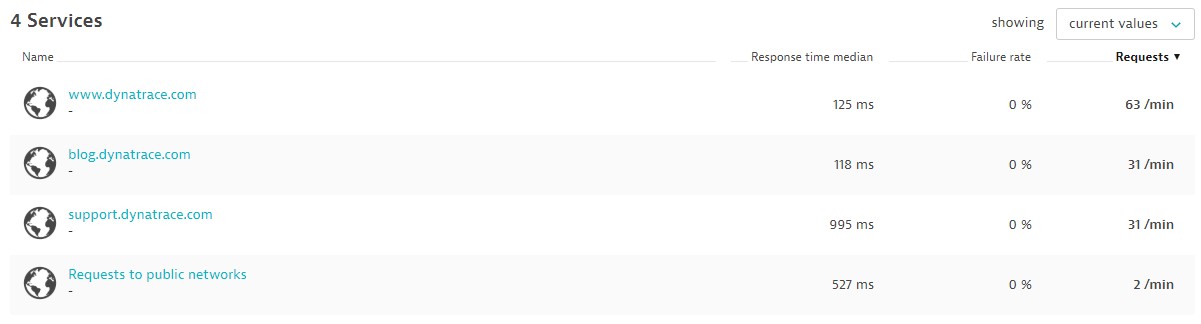
Another way to look at this feature is that you’re able to tell Dynatrace that there are different services behind the different subdomains of dynatrace.com.
Separate services for “public network services” based on URL
This was requested several times by customers and in our Product Ideas forum. (This service rule is a version of the one above where you have different services for different paths of a third-party web request, for example, www.dynatrace.com/support and www.dynatrace.com/blog).
A typical web server has a concept called the context root for separate services based on URL. This is exactly what you can now tell Dynatrace to do. The JSON API call, in this case, would be:
{
"name": "Dynatrace.com",
"type": "OPAQUE_AND_EXTERNAL_WEB_REQUEST",
"description": "",
"enabled": true,
"conditions": [
{
"attributeType": "TOP_LEVEL_DOMAIN",
"compareOperations": [
{
"type": "ENDS_WITH",
"negate" : false,
"ignoreCase" : "true",
"values" : [ "dynatrace.com"]
}
]
}
],
"contextRoot" : {
"segmentsToCopyFromUrlPath" : 1
},
"port": {
"doNotUseForServiceId": true
}
}
Dynatrace superimposes the context root upon the original data which doesn’t supply the proper context to Dynatrace. The result is that you get multiple services that look like this:

Now you might want to get more sophisticated and combine the two features above. This requires more than one rule because simply superimposing the context root will not work.
In the JSON API calls below, you tell Dynatrace that the same application, Dynatrace Blog, sits behind blog.dynatrace.com as well as dynatrace.com/blog. Consequently, Dynatrace detects a single service called Dynatrace Blog.
Rule 1:
{
"name": "blog.dynatrace.com",
"type" : "OPAQUE_AND_EXTERNAL_WEB_REQUEST",
"description": "",
"enabled": true,
"conditions": [
{
"attributeType": "URL_HOST_NAME",
"compareOperations": [
{
"type": "STRING_EQUALS",
"negate" : false,
"ignoreCase" : "true",
"values" : [ "blog.dynatrace.com"]
}
]
}
],
"applicationId" : {
"valueOverride" : "Dynatrace Blog"
},
"port": {
"doNotUseForServiceId": true
}
}
Rule 2:
{
"name": "Dynatrace.com/blog",
"type" : "OPAQUE_AND_EXTERNAL_WEB_REQUEST",
"description": "",
"enabled": true,
"conditions": [
{
"attributeType": "TOP_LEVEL_DOMAIN",
"compareOperations": [
{
"type": "ENDS_WITH",
"negate" : false,
"ignoreCase" : "true",
"values" : [ "dynatrace.com"]
}
]
}, {
"attributeType" : "URL_PATH",
"compareOperations": [
{
"type": "STARTS_WITH",
"negate" : false,
"ignoreCase" : "true",
"values" : [ "blog/"]
}
]
}
],
"applicationId" : {
"valueOverride" : "Dynatrace Blog"
},
"port": {
"doNotUseForServiceId": true
}
}
Separate services for “unmonitored hosts” based on hostname or IP range
You can tell Dynatrace more about services to unmonitored hosts just as you can add information about requests to third-party domains. This works in exactly the same fashion, and you can even check against the IP addresses that you call. This enables you to create a single service that runs on multiple unmonitored hosts.
The rule in the sample API call below tells Dynatrace that a service called Single Sign On is behind all requests to the defined IP range. If you monitored the Single Sign On service directly, Dynatrace would likely discover this automatically; in the case you do not, however, you have to tell Dynatrace about the cluster. Dynatrace still retains information about the multiple IPs in the detected service and tracks the performance of those different IPs separately as service instances.
This allows you to have:
- One service for multiple hosts and/or IP ranges.
- Multiple services based on subdomains of the hostname.
- Multiple services based on the superimposed context root.
{
"name": "Single Sign On",
"type" : "OPAQUE_AND_EXTERNAL_WEB_REQUEST",
"description": "",
"enabled": true,
"conditions": [
{
"attributeType": "IP",
"compareOperations": [
{
"type": "IP_IN_RANGE",
"negate" : false,
"ignoreCase" : "true",
"lower" : "172.10.10.1",
"upper" : "172.10.10.19"
}
]
}
],
"applicationId" : {
"valueOverride" : "Single Sign On"
},
"publicDomainName" : {
"valueOverride" : "login.dynatrace.com"
},
"port": {
"doNotUseForServiceId": true
}
}
Separate fully monitored web request services based on URL or superimposed context root
Some technologies Dynatrace monitors do not support the notion of a context root. In such cases, we typically detect a single service per process group.
The detection rule allows you to impose a context root in the same fashion as described above already. The only difference here is that now we have a fully monitored web request. For the most part, this doesn’t change the rule, but there are a few things that are different when you look at the details of the API call:
{
"name": "Dynatrace Blog",
"type": "FULL_WEB_REQUEST",
"description": "",
"enabled": true,
"conditions": [
{
"attributeType": "URL_PATH",
"compareOperations": [
{
"type": "STARTS_WITH",
"negate" : false,
"ignoreCase" : "true",
"values" : [ "blog/"]
}
]
}
],
"contextRoot" : {
"segmentsToCopyFromUrlPath" : 1
},
"port": {
"doNotUseForServiceId": true
}
}
Here you have asked Dynatrace to superimpose the context root whenever it sees a URL that begins with blog/.
Service detection rule API replaces service merging functionality for better support of dynamic environments
In the four cases described above, you tell Dynatrace more about your services and thus improve how we detect them.
Apart from these functional requests, there are also several cases where service detection is spot on but the incoming data is either volatile or not specific enough. Examples range from Apache HTTP clusters in AWS that don’t have a proper virtual host to web application IDs containing the build date.
Dynatrace originally provided a service merging functionality to cover these cases. This turned out to be useful but had the distinct disadvantage of not working properly in dynamic environments and also proved hard to maintain.
As a result, we’ve decided to deprecate the service merging functionality in favor of the new service detection rules.
It’s easy to apply the new service detection rules
You can use service detection rules to cover the use cases below easily and flexibly while also tackling dynamic environments. Additionally, the rules can be easily exported and imported from one environment to another.
Use cases include but are not limited to:
- Web Application IDs that contain version or build date
You can define a rule that removes the build date/ID from the web application ID, greatly aiding stable service detection. - Server names that are not properly defined in the underlying deployment
This occurs most often with Apache HTTP or Nginx in AWS environments. You can use this feature to define a stable web server name and thus, a stable cluster service containing all instances. - Misuse of context root in the deployed application
Some technologies like Node.js don’t have a context root concept; others just haven’t defined it properly. You can superimpose the context root, leading to separate services for each of your applications instead of a single service containing multiple applications. - Incorrect use of port information
In Node.js applications, the port is often used in a dynamic fashion and needs to be ignored for service detection.
All these cases can be remedied by transformation rules, for example, you can define a transformation rule on the application ID to remove version numbers or build dates. Please check API help for details.
What’s next?
Further enhancements are planned, and you can already see them foreshadowed in the API. At the moment, only web request rules are enabled. In the next version, web service rules will become fully functional.
This will address two main areas:
- On the one hand, a web service is a web request itself. As such, you can use the existing rules to manipulate application ID, context root, and server name for web services in the same fashion as you would for web requests. On the other hand, not everything that Dynatrace detects as a web service really is one.
- Some frameworks like Apache Jersey or Spring REST controllers have a double life. They can be used to define REST-based web services, which is our default assumption, or they can be used to conveniently map URLs to some code in your application. In such a case, Dynatrace detects too many web services, which is not particularly helpful. This can be remedied by a rule that tells Dynatrace to detect web services of a certain framework and conditions as a web request instead of a web service.
Is your use case not covered?
We welcome your feedback. Are your use cases covered? Do you have others? Please let us know.
Please keep in mind that Dynatrace strives to detect your environment automatically, thus configuration is always a second or last resort. We will not build a fully generic, regex-based detection mechanism. In order for Dynatrace and Davis®, our AI engine, to deliver the best possible value, it’s important for us to understand your use case fully. This also ensures that you get the best product possible with the least amount of configuration necessary.




Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum