
|
Johannes Bräuer Guide for Cloud Foundry |
Jürgen Etzlstorfer Guide for OpenShift |
| Part 1: Fearless Monolith to Microservices Migration – A guided journey | |
| Part 2: Set up TicketMonster on Cloud Foundry | Part 2: Set up TicketMonster on OpenShift |
| Part 3: Drop TicketMonster’s legacy User interface | Part 3: Drop TicketMonster’s legacy User Interface |
| Part 4: How to identify your first Microservice? | |
| Part 5: The Microservice and its Domain Model | |
| Part 6: Release the Microservice | Part 6: Release the Microservice |


Part 6: Release of the OrdersService
While in the two previous blog articles we have (i) verified the decision of our first microservice candidate – the OrdersService – with the help of Dynatrace and (ii) identified the domain model for it. In this article, we want to continue our journey of breaking up our monolithic TicketMonster and release this first microservice on our OpenShift platform. Therefore, we apply the strangler pattern to wrap the microservice around the monolith and then reroute traffic to it via feature toggles to allow for a quick release and also a fast rollback in case of errors.
The material used in this blog post can be again found on our GitHub repository, in fact these sub-projects are needed:
Retrospective and current Goal
As an interested reader we are sure you followed the storyline of our journey from the very beginning. However, we want to quickly reiterate what happened so far. Part I was setting the ground for the whole journey and introduced the showcase of the monolithic TicketMonster application. Part II already was technical and guided you to setup TicketMonster on OpenShift, our target platform. In Part III we extracted the User Interface from the TicketMonster application and created its own service for it. Part IV and Part V dealt with the concepts of identifying a microservice and its domain model.
The initial situation for this current article is were we left off in Part III: we have deployed the backend-v1 for which we already got rid off the UI from the monolith and we have deployed it’s own tm-ui-v2 as the UI frontend in front of it (see blue box below):
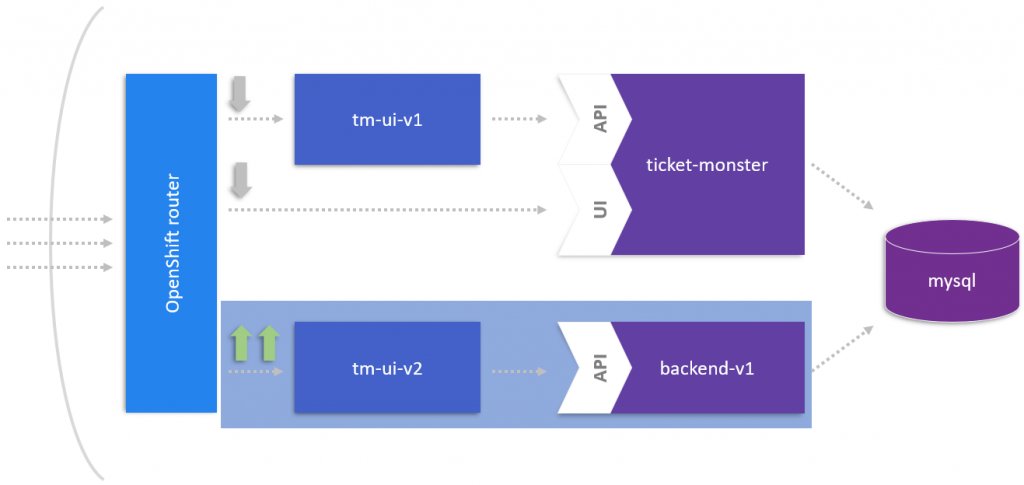
The goal for this article is to extract a microservice from our backend with its own datastore, which has been both identified in Part IV and Part V.
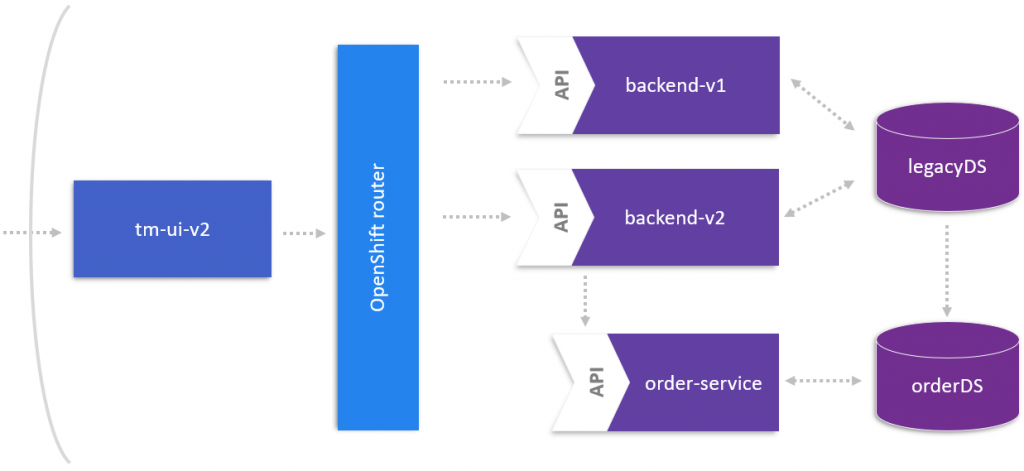
For this, we will need a new version of the backend, i.e., backend-v2, which incorporates the concept of feature flags to control the data flow to the newly introduced microservice. With the two backends in place, we can now either load balance the traffic between backend-v1 and backend-v2 or we can decide to completely move traffic to the new backend-v2, since we want to finally release the orders service which takes requests only from backend-v2. Furthermore, we introduce a new datastore orderDS for the new microservice as well as the database virtualization (discussed in Part V) to ease the burden of data management between two distinct datastores.
Strangling the OrdersService around our Monolith
Before launching the OrdersService as its own microservice we must take precaution on how to release it to the public by taking the follow considerations:
- How to send traffic to the new service in a controlled manner?
- How to be able to direct traffic to the new service as well as the old code path?
- How to instrument and monitor the impact of the new service?
- How to deploy this new functionality to certain user groups?
Addressing these concerns, Christian Posta recommends in his original series to incorporate the microservice into the monolith in a way that allows to send no traffic, synthetic traffic, and live traffic to the microservice.
The technical realization of this can be achieved by utilizing feature flags, which in our case is done by the Feature Flags 4 Java (FF4J) framework. Basically, the idea is to steer the data flow by switching feature toggles from outside of the application to allow to control when to release a specific feature without the need for a code change, but with toggling the feature flag.
Therefore, in backend-v2 we have to build in this functionality, by changing the createBooking method of the BookingService. We create the additional methods for taking synthetic traffic (i.e., sending the data through the OrdersService but not persisting it) and for live traffic for the OrdersService.
@POST
@Consumes(MediaType.APPLICATION_JSON)
public Response createBooking(BookingRequest bookingRequest) {
Response response = null;
if (ff.check("orders-internal")) {
response = createBookingInternal(bookingRequest);
}
if (ff.check("orders-service")) {
if (ff.check("orders-internal")) {
response = createSyntheticBookingOrdersService(bookingRequest);
}
else {
response = createBookingOrdersService(bookingRequest);
}
}
return response;
}
As already said, the full source code is available in the backend-v2 sub-project in our GitHub repository along with a more technical description how to add the needed dependencies for ff4j.
After deploying the backend-v2 service we will be able to access the ff4j web console with the ability to directly toggle the feature flags to enable either (i) the internal orders service from backend-v2 to be called (as shown in the screenshot below), (ii) sending synthetic traffic to the OrdersService by enabling both toggles, or (iii) calling of the new OrdersService by disabling the orders-internal and enabling the orders-service feature flag.
https://backend-v2.YOUR-SYSTEM-DOMAIN/ff4j-console

We have now accomplished a mechanism that provides flexibility in calling the new microservice, i.e., with this mechanism we can clearly distinguish between deployment and release of the microservice. This means, we can safely deploy the microservice to production without any traffic on it at all. Next, we hit it with some synthetic traffic to test its stability and behavior by enabling both feature toggles, and finally switch over to the orders-service without the orders-internal switch being enabled.
Controlling the data flow
As stated in the beginning, we have two different versions of our backend up and running in OpenShift, which are backend-v1 and backend-v2. The OpenShift routes mechanism lets us define how much traffic we want to send to each microservice. Since right now we have not released the backend-v2 yet, we want to use a canary release to send only a fraction of the traffic to the new backend to test its stability. We can set the amount of traffic for example to 10 % of the overall traffic by the following command:
oc set route-backends backend backend-v1=90 backend-v2=10
This means, we are sending 90 % of the traffic via our “backend” route to the already existing backend-v1 and 10 % of the traffic to the new backend-v2. In the figure below, we can see how the requests are distributed when introducing the backend-v2 around 13.46h.
Since we are not noticing any issues, we can increase the traffic to 25 % percent starting around 14.00h. Again, we gain more confidence in the service and increase the load over time, as we can see by the “steps” in the chart in the figure below.
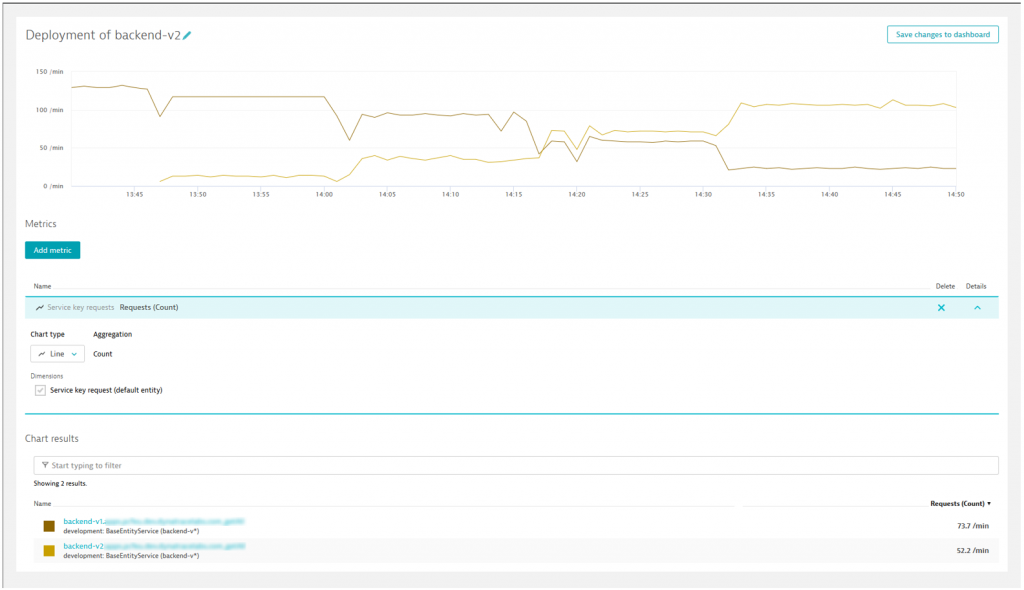
Once we are confident enough to send traffic only via the backend-v2 service (since we want to introduce the OrdersService) we can send the whole 100 % of traffic to the backend-v2 service.
oc set route-backends backend backend-v1=0 backend-v2=100
We can also verify that two different instances of the same service are up and running when looking into the Dynatrace transaction & services section. Dynatrace automatically detects all instances of a service and let us compare for example the number of processed requests and the response time of each instance as seen in the figure below.
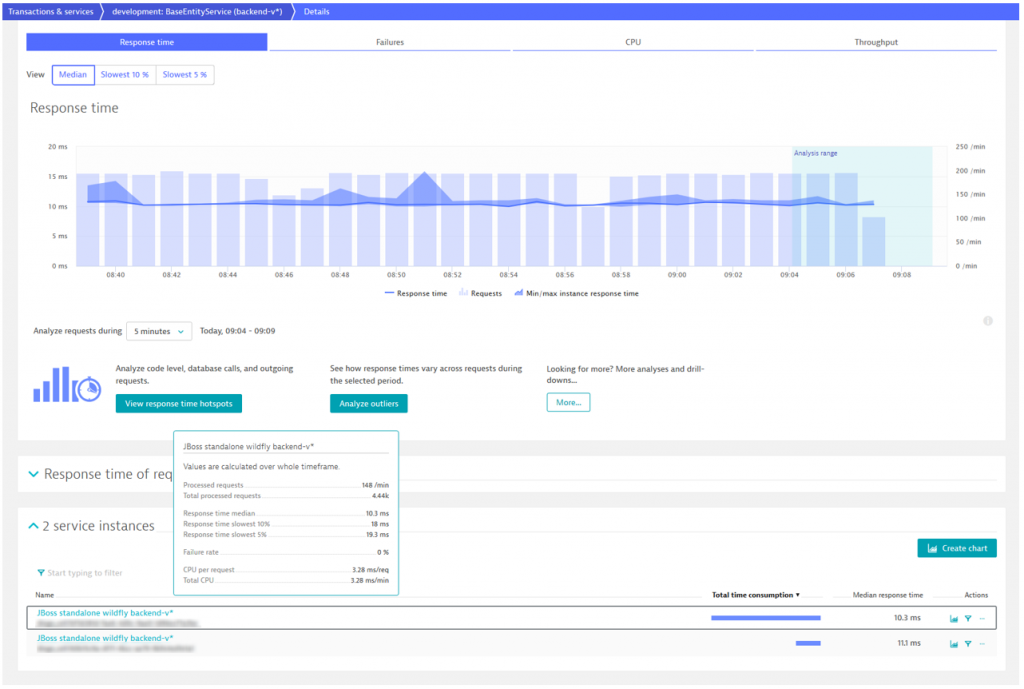
Release the microservice via the feature flag
Since we have confidently released backend-v2 to the public, it is now time to send traffic via the OrdersService instead of the internal code in the backend-v2 codebase. Therefore, we switch the feature flag in the ff4j web console to the orders-service and deactivate the orders-internal option.

Doing so will send all traffic from the BookingService to the OrdersService. However, as we can see also in the Dynatrace service flow screen, the BookingService is still part of the service flow, since in the BookingService itself the feature toggle mechanism is implemented.
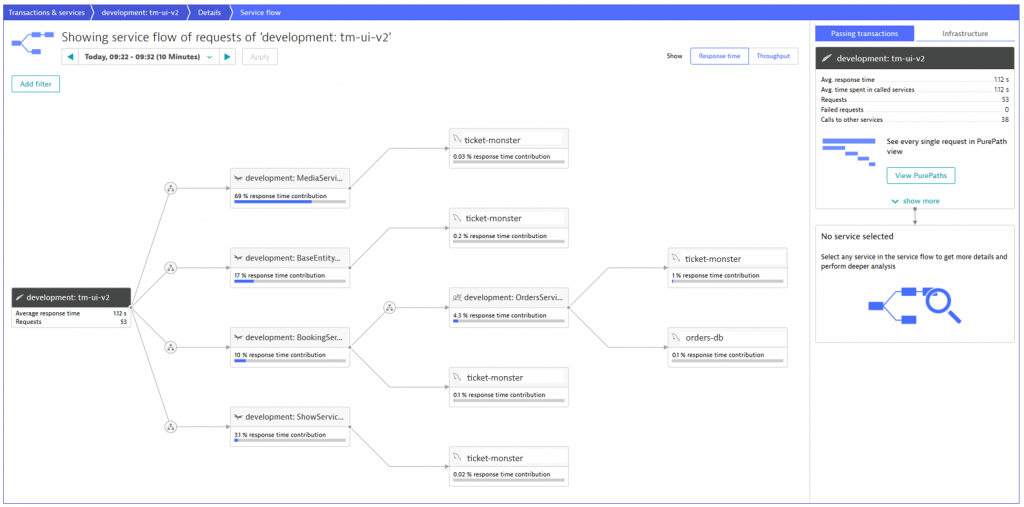
Let’s take a look closer look at the service flow above and verify which services are called in our application. Requests received by the frontend highly consume the MediaService, since a lot of media is provided by the TicketMonster and this component is responsible for delivering it. We can also verify how often the BookingService is called. Furthermore, we see that the BookingService has both calls to the OrdersService as well as the ticket-monster database. The reason is that before switching the feature toggle to the microservice, the BookingService was directly communicating with the ticket-monster database. When looking at the OrdersService, we see a data flow to both the ticket-monster and the orders databases. Again, the answer is quite easy: with the database virtualization we introduced in Part V, we defined that the OrdersService gets a union of all bookings from both databases. All in all, we see a clear and complete picture of the service flow in our application including the newly introduced microservice. Great, everything looks like expected and with Dynatrace we have a live validation on our actual environment!
Wrap up and Outlook
Let’s pause a minute and review what we have achieved so far. We have now extracted our first microservice and successfully released it in production. With the help of Dynatrace we were able to fearlessly break up the monolithic TicketMonster since we had full-visibility of our complete technology stack in real-time and could evaluate and verify the current situation. Furthermore, custom service detection allowed us to virtually extract a microservice to validate its behavior and justify the work we invested to extract it from and strangle it around the monolith.
What is left to do? First of all, we have introduced some technical debt by implemented the feature flag mechanism. However, there will come the point where we have to resolve this issue by removing the feature flag mechanism and call the OrdersService directly to prevent obsolete feature flags living in our application. Second, we will have to clearly separate the two datastores by removing the database virtualization. As it was handy for development and the introduction of the microservice it will become of a burden eventually, therefore we will have to clearly decouple the datastores.
What are the next steps? Well, this blog series introduced a lot of concepts, best practices and effective techniques for you to conquer your own monolith and break it up into microservices. Go ahead and take the challenge! If you do so, you can let us know (@jetzlstorfer) – all the best with your own journey!


Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum