
|
Johannes Bräuer Guide for Cloud Foundry |
Jürgen Etzlstorfer Guide for OpenShift |
| Part 1: Fearless Monolith to Microservices Migration – A guided journey | |
| Part 2: Set up TicketMonster on Cloud Foundry | Part 2: Set up TicketMonster on OpenShift |
| Part 3: Drop TicketMonster’s legacy User Interface | Part 3: Drop TicketMonster’s legacy User Interface |
| Part 4: How to identify your first Microservice? | |
| Part 5: The Microservice and its Domain Model | |
| Part 6: Release the Microservice | Part 6: Release the Microservice |


In the previous two blog posts, we have successfully decoupled the user interface from our monolithic application TicketMonster. Besides, the monolith became thinner in the sense of a code base without legacy UI code and this version has been deployed using canary release approaches. However, at this stage of our journey, it is now time to get a good understanding of the business logic behind TicketMonster to fearlessly break out certain pieces of the monolith.
A blog post with great input for this step has been published by Andi Grabner, who summarized his experience about breaking any type of monolith in his 8-step recipe. Andi’s “recipe” allows you to do continuous experimentation with Dynatrace, without changing a single line of code or impacting end users! By following the 8-step recipe, this blog post will examine TicketMonster from the viewpoint of identifying possible microservice candidates.
Understand the Monolith
According to Andi (and what we have learned from practice), there are a couple of things we don’t know about our monoliths:
- Who is depending on us and how are they depending on us?
- Whom are we depending on and how are we depending on them?
- What happens within our monolith code base when it gets called?
Service Dependencies, Behavior & Usage
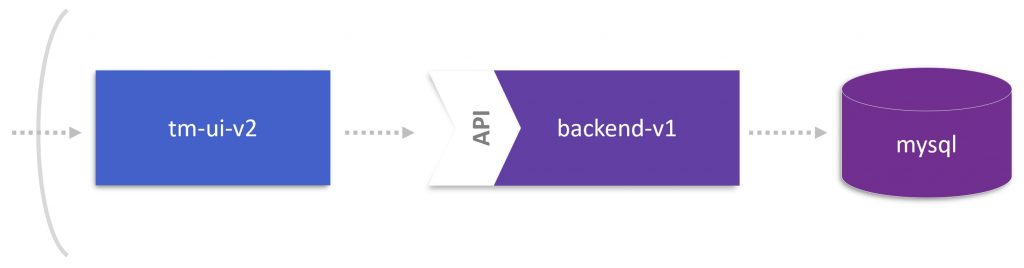
To address the above-mentioned questions, let’s use Dynatrace, which detects service dependencies automatically and traces requests through the source code. If you followed our journey from the first blog onwards, TicketMonster should either run on Cloud Foundry or OpenShift. After installing the Dynatrace OneAgent on the platform where the monolith lives, you will immediately get dependency information about who is depending on us (1 application), where are we running (1 Apache Web Server), and whom are we calling (4 services), as shown below.
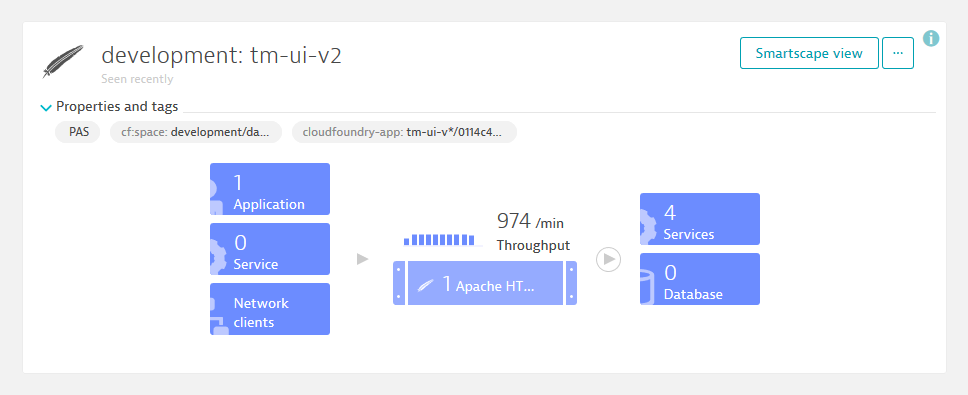
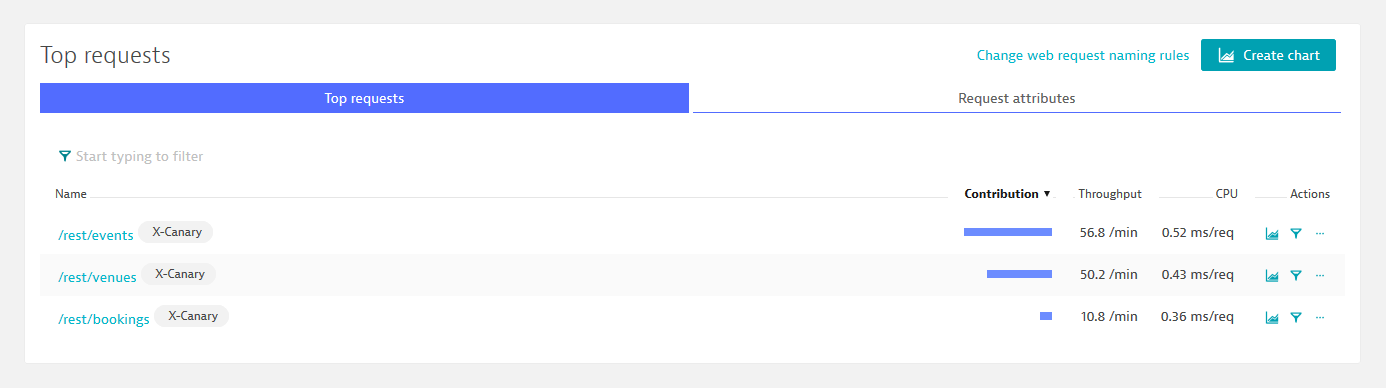
In addition to resolving dependency information, Dynatrace captures every single transaction end-to-end, identifies application endpoints (whether REST endpoints, web services, or queues), and shows throughput as well as resource consumption per request. This information is displayed in the screenshot above and allows us to make better decisions on which endpoints we first want to consider for a microservice candidate. If we want, for instance, to minimize risk, we might choose those entry points with the lowest throughput. On the other hand, we would focus on heavy CPU consumers if we want take load off the monolith.
Service Flows
“I’m wondering, the user interface tm-ui-v2 of TicketMonster is calling four services? Are these already microservices?” A careful reader may raise these concerns since we have introduced the monolith as single service in Set up TicketMonster on Cloud Foundry/OpenShift. At the introduction, we tried to keep complexity low by letting TicketMonster appear as a single service. Nevertheless, the monolithic application (backend-v1) contains already four independent services, as shown by the ServiceFlow provided by Dynatrace.
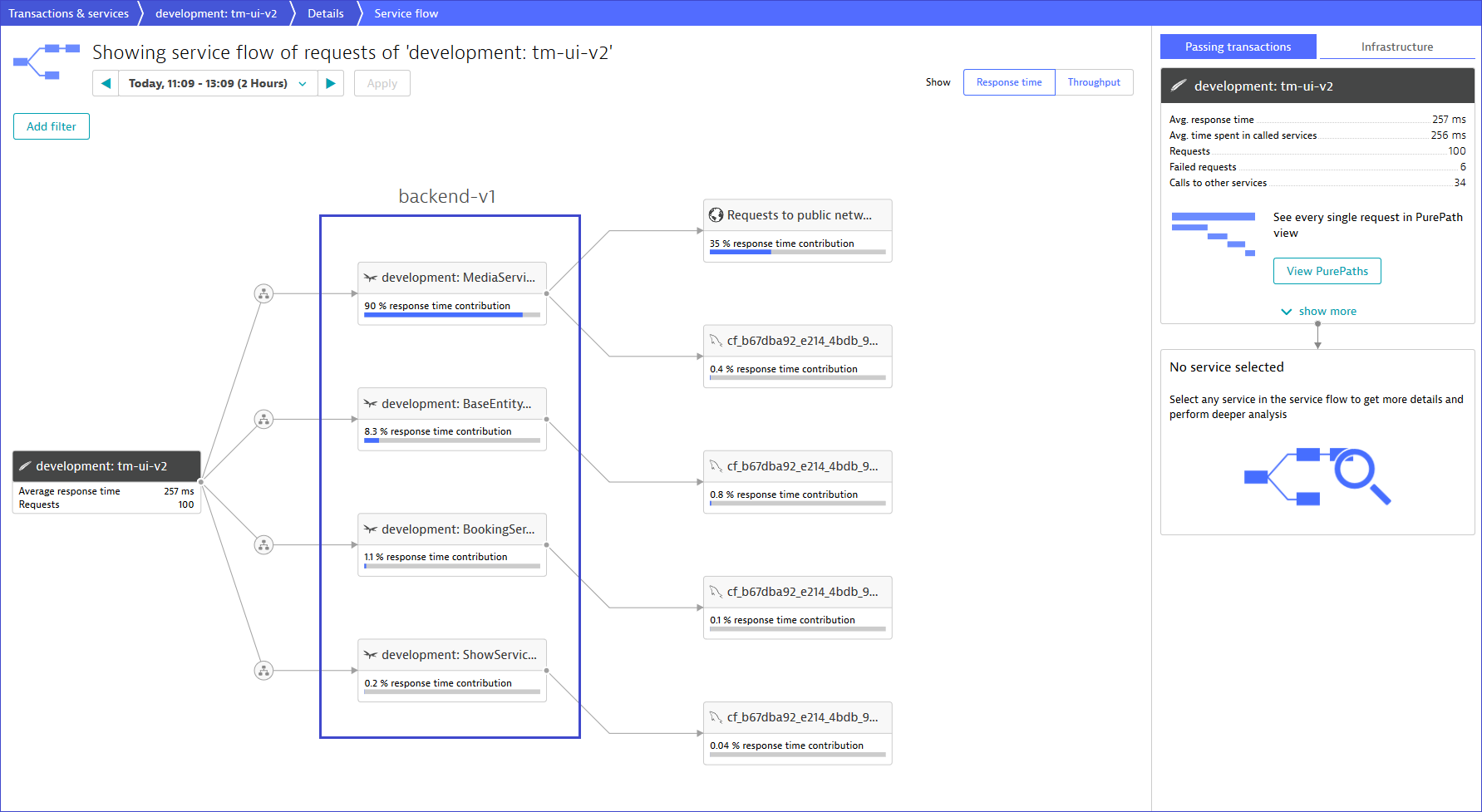
According to the above screenshot, backend-v1 of TicketMonster is composed of MediaService, BaseEntityService, BookingService, and ShowService. These are four REST services with their individual endpoints but, connected to the same database. Besides, they are all part of the same code base what hinders scalability of a particular service. In fact, we can see from the above picture, that MediaService takes most load in this selected time frame. Extracting this component out of the monolith would definitely make sense, as we could then scale it up or down depending on its needs but independently from the others.
Is MediaService a possible microservices we could extract from the monolith? Probably yes – but let’s go one step further and let’s explore another technique for identifying candidates and understanding how, or better, where we can fearlessly break the monolith.
Custom Service Entry Points
By continuing Andi’s approach to find appropriate candidates of methods, classes, or modules that can get extracted, at step 4 he recommends diving into the code that is executed when service endpoints are called. Even more important is the identification of the first method that gets called in the code. To accomplish this with Dynatrace, we can investigate the PurePaths that are automatically captured based on our REST endpoints executed in TicketMonster. To see a PurePath of a particular request, Andi opens a service, filters on the entry point method, and then tries to find the first method invocation that belongs to the customer code base.
In the case of TicketMonster, we can select one of the four services mentioned above. Let’s investigate, for instance, BookingService that deals with booking tickets what is a business-critical domain of TicketMonster. After selecting this service by a click on the component in the ServiceFlow, the View method hotspots brings us to the PurePaths. There we can filter, for example, on the endpoint /createBooking and search for a method invocation of our source code. The screenshot below shows the result of this step.
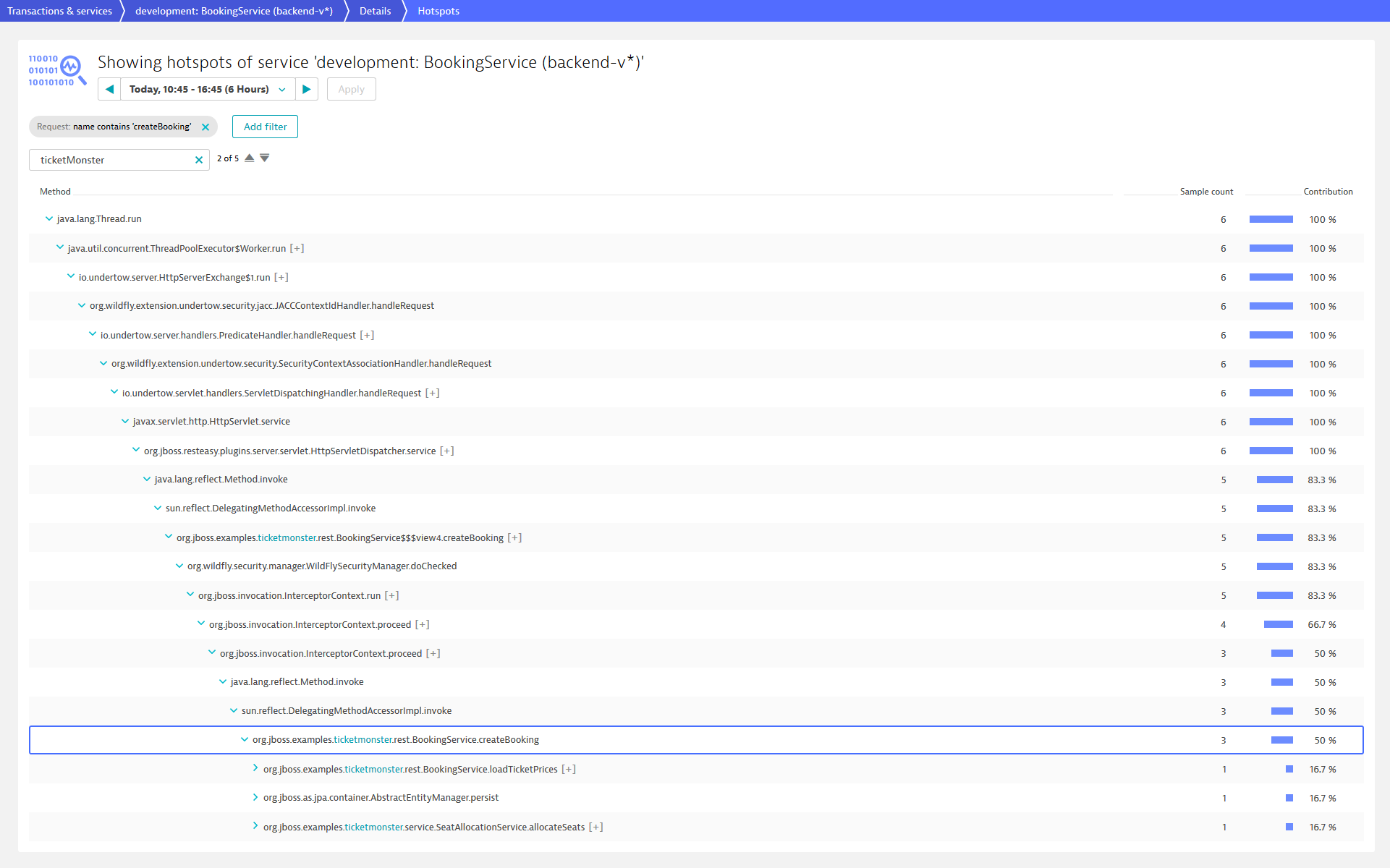
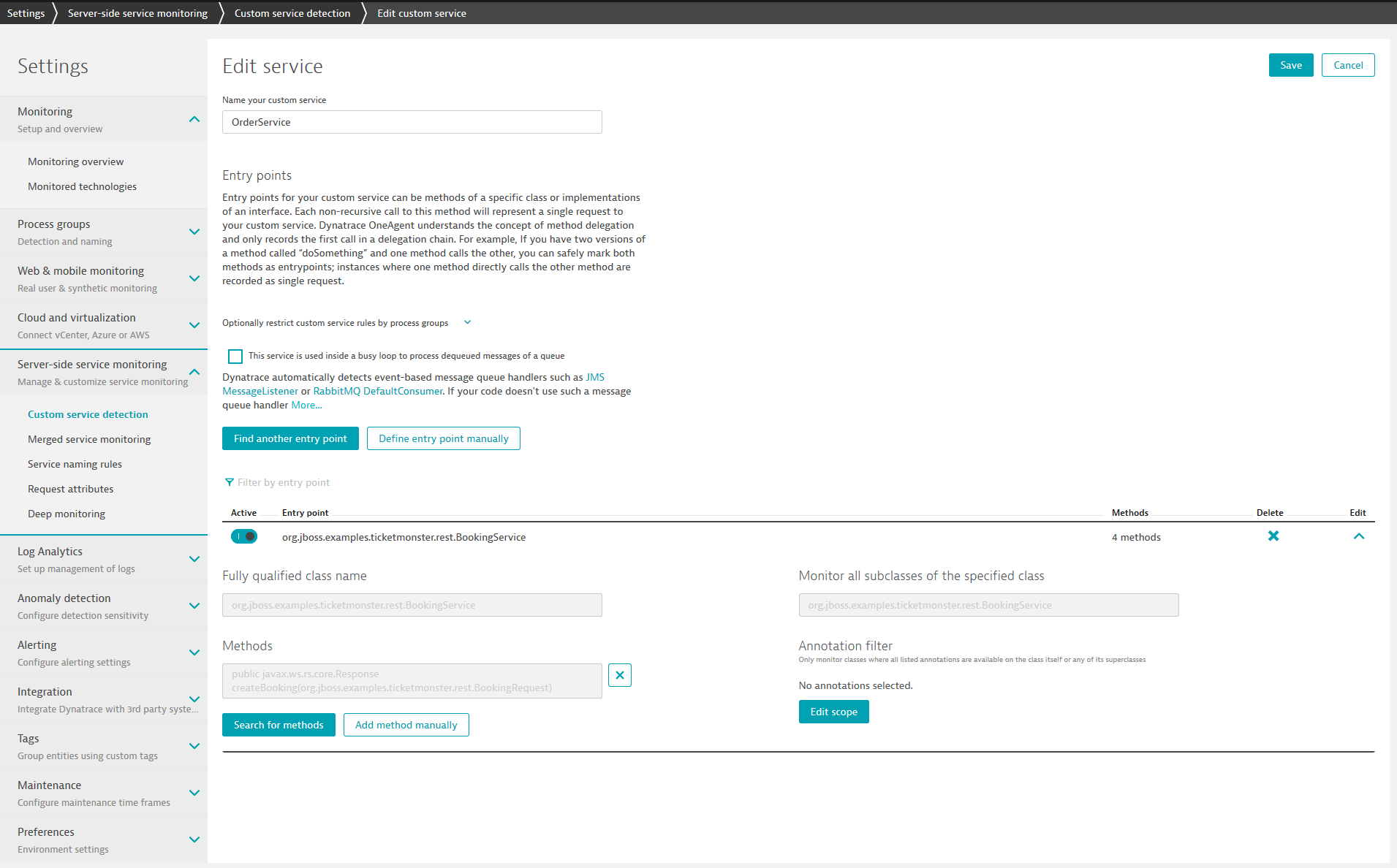
Given the class and method name, we can use the Dynatrace feature custom service detection to treat a certain method in our code base as an entry point of a “logical service”. In other words, this method call will be extracted from the BookingService and will appear as individual service instance. To create this detection rule, the settings page under Custom service detection provides the functionality Define Java service. This functionality asks for the process group (backend-v1), the class (BookingService), and finally the method (createBooking) we would like to encapsulate as single service.
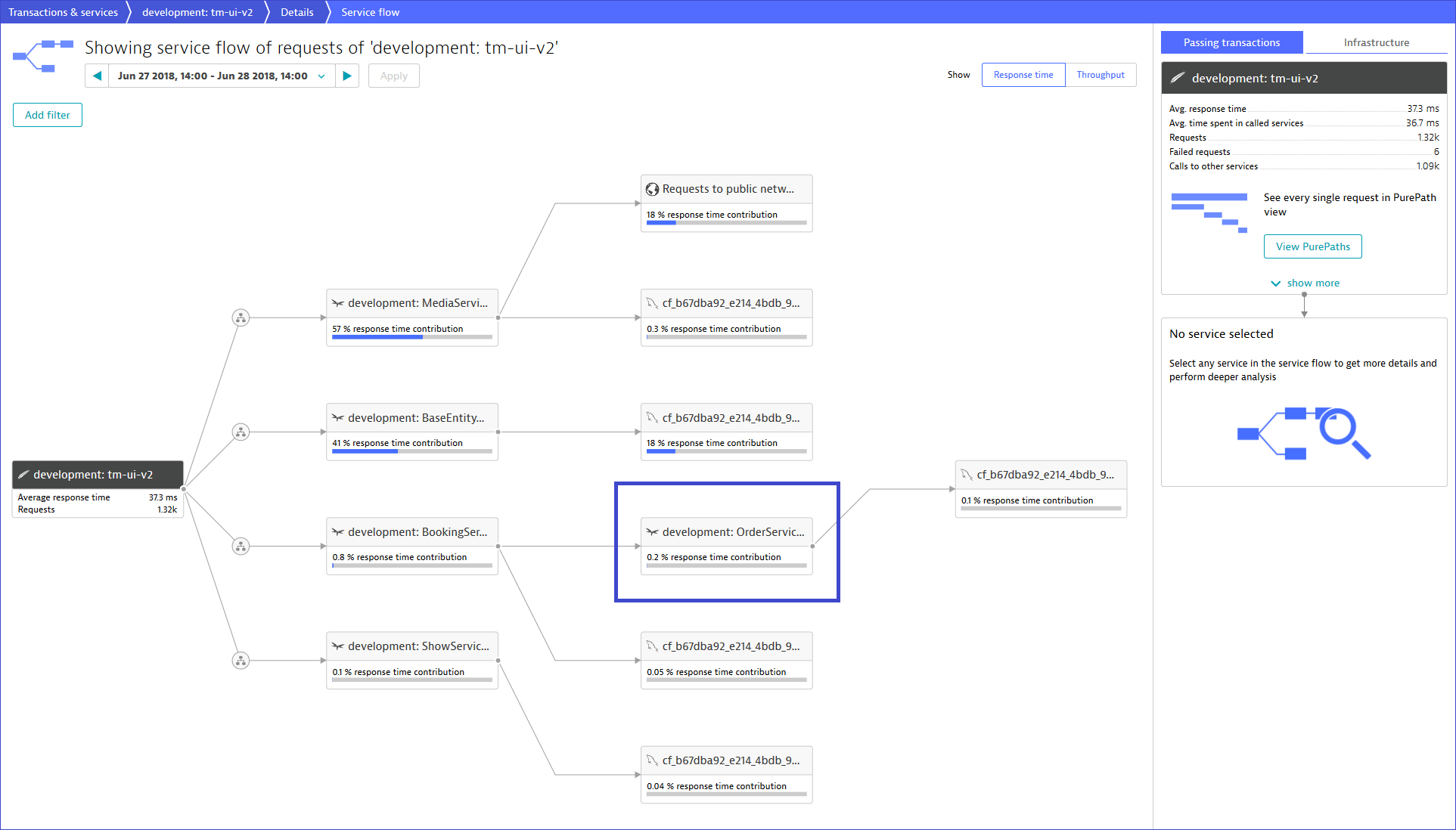
After putting the above custom service detection rule in place, booking a ticket on TicketMonster creates the service OrderService. This service exists “virtually” and captures traffic that consumes the createBooking method. At this point, it’s time to learn on whether breaking out this method is in fact a good idea or not. For that we can consider again the Dynatrace ServiceFlow, which breaks the BookingService into every single “virtual” service and shows us how these services are called, whom the call, how often, etc. Remember – so far, we have not changed any line of code. We basically simulated how our code would look like if it would be broken along certain methods in our monolithic code base.
First Microservice Candidates
At this point, we walked through the first six steps of Andi’s recipe that gave us better insights into service dependencies and how the inner code of TicketMonster works. In fact, we identified MediaService and our simulated OrderService as possible candidates for the first microservice extraction. Nevertheless, we should consider that the decision of the first microservice may also depend on other impact factors that do not manifest in data. Thus, it advisable to thing about following aspects from the viewpoints of different stakeholders:
- Business risk – Is the planned microservice a critical component and does it impact the business in case it fails (conduct a risk assessment)?
- Product roadmap – Which parts of the monolith need to be refactored anyways?
- Business strategy – What is the long-time business strategy of the monolith?
- Technology strategy – Do new technologies impact the further development of the monolith?
Outlook
The bottom line – identifying the first microservice strongly depends on know-how from domain experts, architects, and developers of the monolithic application. To support this group of decision makers, Dynatrace provides a clear picture of the application with valuable data insights and features simulating the introduction of a microservice. In the next blog post, we will focus on extracting the microservice OrderService. Therefore, we will perform step 7 & 8 of Andi’s recipe that concentrate on re-factoring and consciously monitoring the code base.


Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum