
The complexity of cloud-based or hybrid IT environments and application landscapes continues to grow. With Dynatrace being able to handle thousands of connected agents, services, containers, servers, and individual user tracking, synthetic monitoring measurements and ingesting external data monitoring becomes a breeze. When using Dynatrace Managed you get full control and responsibility for the Dynatrace Cluster itself. It’s easy to scale out such a cluster to support thousands of connected systems in one tenant, but also to host hundreds of individual tenants – each of them a separate monitoring environment.
If you’re a service provider that hosts “Dynatrace Services” to different organizations in your company, you’ll likely need to manage the creation and maintenance of these environments at some point. You might face challenges in automating operational tasks or keeping track of configuration standards imposed by corporate requirements, and depending how large your setup grows this could get a hurdle and calls for automation at scale.
My name is Reinhard Weber, and I’ve been managing a global setup of multiple Dynatrace Managed Clusters with over 5,000 individual Environments/Tenants in a hybrid deployment scenario.
This is probably a unique setup, but I’d like to share my approach and solutions on how I achieved autonomous environment management, kept an eye on a global deployment scale and growth, standardized and enforced settings and implemented a “Dynatrace configuration as code” principle for continuous integration and delivery.
How large is “large scale”?
You might have seen the movie “The Matrix” with Keanu Reeves in the late 90’s. One of my favorite scenes in this movie is when he finally realizes what the matrix really is, and he’s able to see through everything and just “know”. Well this is not the matrix, but I got somehow inspired:
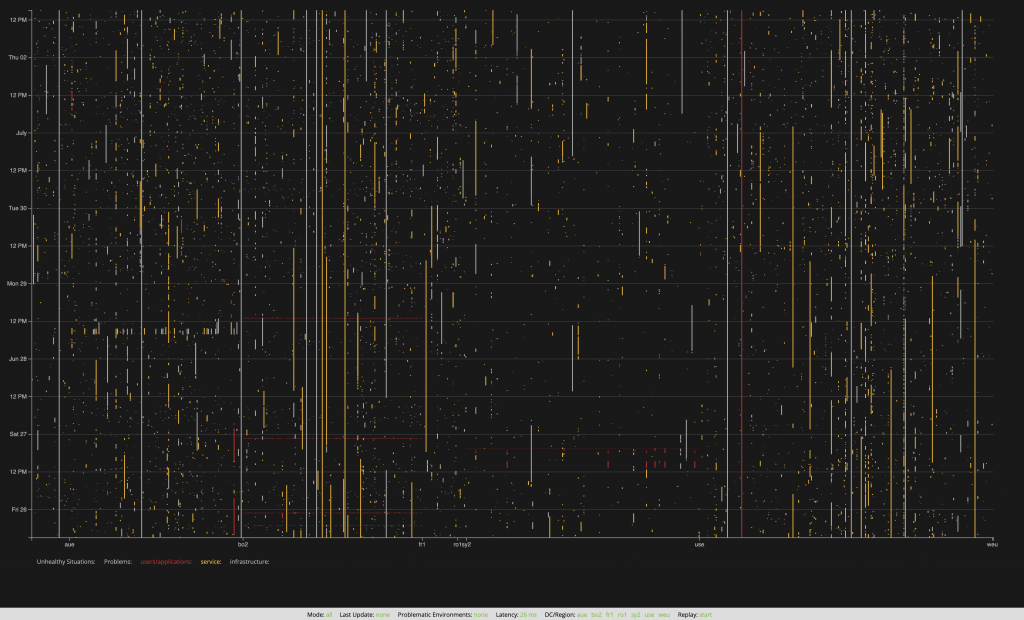
What you see in the above screenshot is a representation of almost thousand monitored environments and their problems within a week, detected by Dynatrace. Do you see some patterns in this image? This visualization is just one example of how I addressed the challenges of managing a very large Dynatrace setup.
Just like Keanu Reeves in the Matrix – we have to prepare before we’re able to see everything. There are some prerequisites, so I decided to cover them in a multiple part blog series. I’ll go through architectural concepts and examples, split into four separate posts:
- Part I: Autonomous Dynatrace roll-out
- Part II: Managing the Dynatrace API across multiple thousand environments
- Part III: Keep track of thousands of environments from 20.000 feet
- Part IV: Maintaining configuration as code and configuration management
Part I: Autonomous Dynatrace roll-out
When I started implementing Dynatrace it was clear that the roll-out wouldn’t be a “start small and grow over time” project. My task was to migrate from a several hundred tenant setup (monitored with Dynatrace’s AppMon) into two datacenters to the new Dynatrace Software Intelligence Platform.
Just as in many setups, this one was historically grown – a managed service provider’s installation of several hundred isolated tenants, each consisting of multiple VMware based hosts. Different monitoring tools were used; one for the server landscape, network layer, databases, dashboarding and Dynatrace’s AppMon for APM and User Experience Monitoring (UEM) needs.
With the projected growth, a different architecture – switching to cloud providers instead of self-hosting – and moving away from traditional tools was required. The first challenge was to “migrate and lift” around 12 thousand hosts into the new Dynatrace Software Intelligence Platform. It was clear right from the start, this would be a big migration.
A large migration
Not only would the Dynatrace setup be big, but the move had to happen with close to or no impact and downtime to the hundreds of services that were to be migrated in a relatively short timeframe.
Imagine yourself as a service provider, who has to align every change with the customer, you might establish a reasonably sized project team which comes up with a plan and a time schedule and then handles every customer one-by-one to make the switch over.
This was the initial (and traditional) thought, which I discarded quite early. It would not be doable in the timeframe imposed. And, I didn’t want to do it that way either – too much of a heavy process – I’m more the agile type of person who implements reliable automation instead of human processes.
So, there were a few challenges to address. Assuming that we have Dynatrace Managed Clusters set up and sized accordingly, how do we automate the creation of Dynatrace Tenants/Environments and how do we automatically download and deploy the OneAgent installers so that they connect to the right tenant?
Orchestration and autonomous Dynatrace setup
We had a system configuration management tool in place to manage the numerous hosts. In this case, Puppet was used and I wanted Puppet to handle the automatic creation of Dynatrace environments as well as the installation of the OneAgent for me. As this platform was still based on traditional Virtual Machines, I had to create my own “Dynatrace Managed Autonomous Operator”.
The key for that to work are the various Dynatrace APIs. But before we dive into that, here are the requirements for achieving our goal:
- When a new customer environment was provisioned, we wanted to automatically create a Dynatrace environment for the monitoring
- The Dynatrace environment should have a meaningful name to easily identify it by its URL:
Typically an environment URL in Dynatrace Managed would look like this:
https://your-cluster-host/e/74c2f784-3dff-4630-9c35-dfca5a3fbdb3
but I needed something more meaningful, like:
https://your-cluster-host/e/abc-p1 (where “abc” identifies a customer ID and “p1” tells me it’s a production environment) - Whenever Puppet detects OneAgent is not installed on a virtual machine, it determines which Dynatrace Environment it should connect to, downloads the latest agent and installs it.
- If new servers are added to a customer installation, these should automatically be added to the correct Dynatrace environment by installing the OneAgent.
Create the right user-groups in Dynatrace and also set the proper permissions for accessing the environment.
Sounds simple enough, and we basically only need three Dynatrace APIs and some scripting to achieve this:
- TenantManagement API available on a Dynatrace Managed Cluster
- User/Group Management API available on a Dynatrace Managed Cluster
- API Token Management API for individual Dynatrace Environments
The “Autonomous Dynatrace Setup” can be visualized in below diagram. Puppet executes the “Dynatrace setup” script periodically and performs these steps to ensure any existing or newly provisioned system is added to Dynatrace.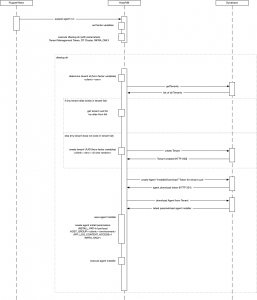
Challenge #1: Automate Dynatrace environment creation
To create environments (tenants) on a Dynatrace Cluster you need a Cluster API token. This token is very powerful, yet our Puppet script needs access to it, and it is imperative that it is well protected and stored.
We will need two endpoints of the cluster API
- Getting a list of all active environments
- Creating new environments
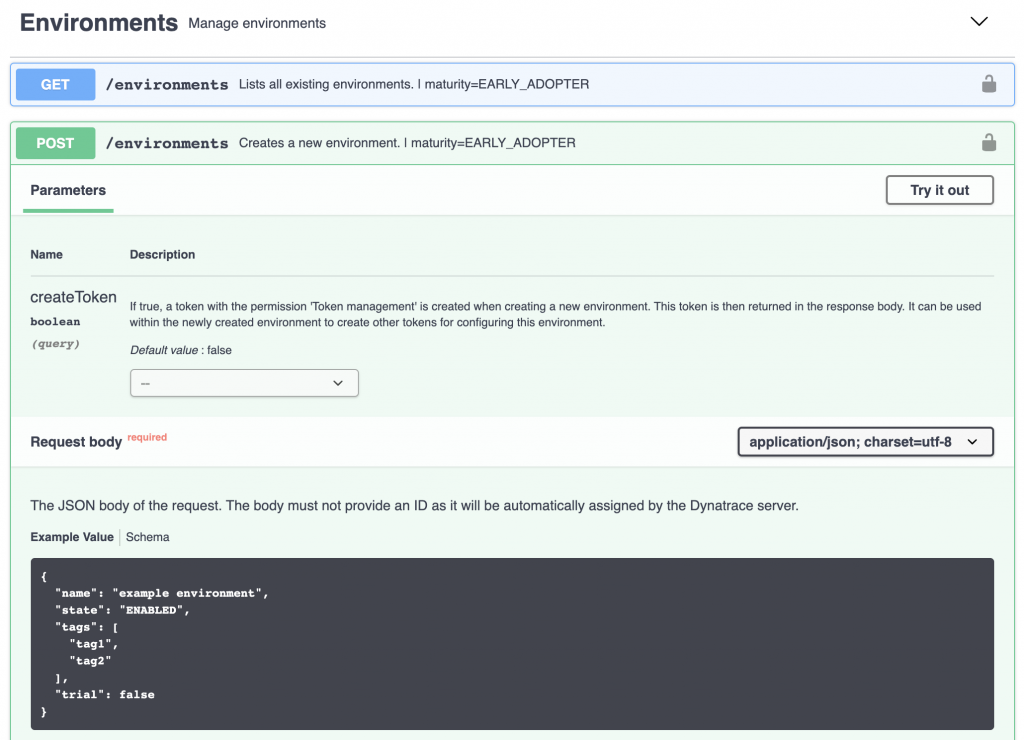
So, the logic in our script is simple: determine what the tenant/environment-name/id for this server would be (this information was derived from Puppet’s system information), then check via API call if the environment already exists. If not, POST a request with the relevant payload to create the environment.
Shortly after that POST, the environment is created and can be used, so we can prepare to fetch the OneAgent installer.
Challenge #2: Automate Dynatrace agent deployment
When you manually download the OneAgent from the Dynatrace UI, you get a parameterized installer script that makes sure that the agent connects to the right environment.
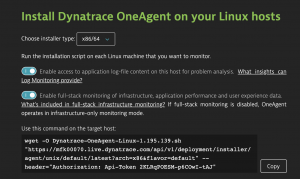
Fortunately, there is also an API to get an Installer Download. But before we can download the parameterized installer, we need to create a special API token with the right permission scope that allows us to do so.
You guessed it! There’s also a management API to create API tokens. So, we can use our Cluster Administrative token (the same we used for creating environments) to create a temporary environment token that will allow us to download the agent:
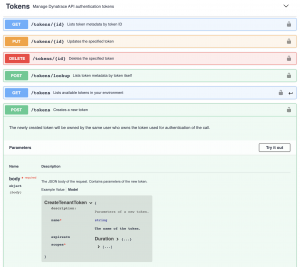
Once we have the download token created, we can use it to download the parameterized OneAgent installer from the Deployment API endpoint by providing the token in the request:
https://<host>/e/<tenantid>/api/v1/deployment/installer/agent/unix/default/latest?Api-Token=<apitoken>&arch=x86&flavor=default
After that, we only need to execute the OneAgent installer and soon the host will report data to the correct Dynatrace environment.
Let the Machines do the work
By wrapping these three steps into a script, that is executed by Puppet, we were able to hook up 12 thousand hosts to Dynatrace and create several hundred tenants without any human interaction. But more importantly, we don’t have to worry about any new servers or customer environments that are provisioned from now on.
Food for thought
Observability and monitoring are mandatory for any service provider. While you might get away with a manual setup approach in small environments you can’t do so for large installations. A large multi-tenant setup even makes things more complicated and calls to full automation. We have seen that the APIs of a Dynatrace Managed installation allow this complete autonomous setup.
For me this was only the first step! I also wanted to maintain this setup in an automated fashion using the Dynatrace APIs for integrations and configuration management. In part two of this series I will cover how I addressed the challenges of maintaining the APIs of a few thousand environments.




Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum