
Logs now complete the observability picture alongside traces and metrics in the Dynatrace Grail™ data lakehouse. By following best practices for setting up buckets with security context in Grail, the appropriate log data is now always at the fingertips of the right teams.
Grail: Enterprise-ready data lakehouse
Grail, the Dynatrace causational data lakehouse, was explicitly designed for observability and security data, with artificial intelligence integrated into its foundation. We’ve further enhanced its capabilities to meet the high standards of large enterprises by incorporating record-level permission policies.
To fully utilize Grail features, it’s recommended that you incorporate its unique buckets and security policies at the beginning of your observability journey. Utilizing built-in mechanisms and customizing organization-specific policies maximizes the benefits of Grail capabilities.
Custom data buckets for faster queries, increased control, and custom retention periods
The first layer in the Grail data model consists of buckets and tables (and views for entities, which is outside this blog post’s scope).
Tables are a physical data model, essentially the type of observability data that you can store. Buckets are similar to folders, a physical storage location.
There is a default bucket for each table. Here is the list of tables and corresponding default buckets in Grail.
| Table name | Default bucket |
| logs | default_logs |
| events | default_events |
| metrics | default_metrics |
| bizevents | default_bizevents |
| dt.system.events | dt_system_events |
| spans | default_spans |
The default buckets let you ingest data immediately, but you can also create additional custom buckets to make the most of Grail.
Address specific use cases with custom buckets
It’s logical to segregate high-volume data into its own bucket. This allows the data to be frequently queried and used separately from other scenarios.
For example, a separate bucket could be used for detailed logs from Dynatrace Synthetic nodes. Debug-level logs, which also generate high volumes and have a shorter lifespan or value period than other logs, could similarly benefit from dedicated storage. Keeping these logs separate decreases the data volume for other troubleshooting logs. This improves query speeds and reduces related costs for all other teams and apps.
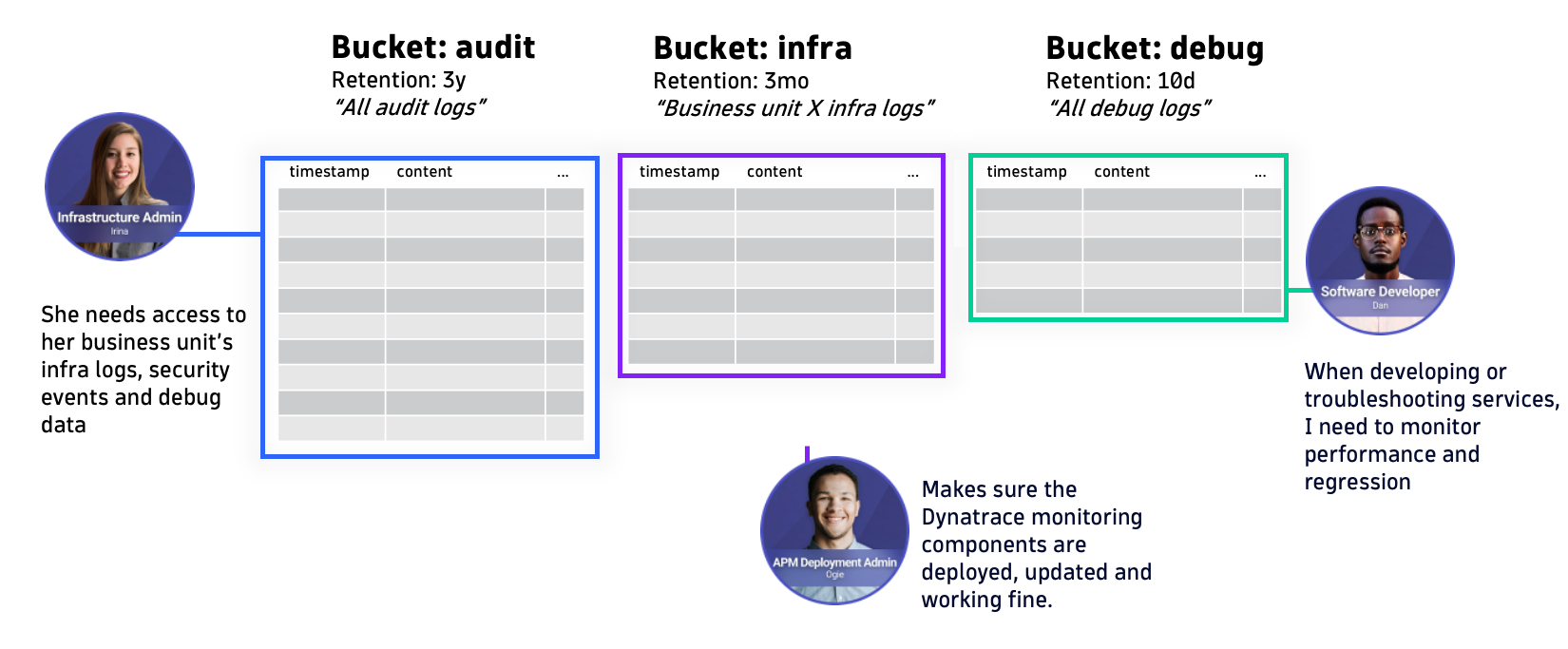
Address organizational structure with custom buckets
Depending on your organization’s structure, you may find it beneficial to keep logs used by specific business units or departments in separate buckets. This approach makes queries faster for individual units, as they only query relevant logs, and it ensures distinct access separation.
Suppose a single Grail environment is central storage for pre-production and production systems. In that case, the use of separate buckets makes it easier to distinguish different stages, keeping production data separate from development or staging data.
Adopting this level of data segmentation helps to maximize Grail’s performance potential. If your typical queries only target a specific use case, business unit, or production stage, ensuring they don’t include unrelated buckets helps maintain efficiency and relevance.
Custom buckets unlock different retention periods.
Segmenting your data into multiple buckets also puts you in control of the data retention period. The simplicity of storing data in Grail is reflected in its retention policies; you choose how long to store each portion of your data, and you never have to think about managing archives or retrieving archived data. Coupled with the transparent pricing of GiB/day, you can set up buckets to exactly match your business needs.
While the built-in default_logs bucket has a retention period of 35 days, you have more options to choose from. Use Grail’s public bucket management API to create new buckets for which you can select data retention periods of 1 day to 10 years , or use the new Storage Management app to that with just a few clicks.
In conjunction with the previous example of keeping high-volume and short-lived logs separate, you might also need to keep your application data longer. For example, transaction data and user-profile logs might need to be retained for 12 or 18 months.
Use buckets to query only the log data you need
Whether looking for a “needle in a haystack” or reporting on data stored in Grail, you can start an advanced query with DQL by fetching data from one of the tables. At this point, you should familiarize yourself with the blog post Tailored access management, Part 2: Onboard users to Grail and AppEngine, which covers access to Grail tables and buckets.
Now, let’s take a look at a query example that puts this all into use.
fetch logs
| filter loglevel=="ERROR"In this example, we query a certain table (logs) and filter the results by a field (loglevel) with a certain value (ERROR). Note that with such a query, you fetch logs from all the buckets the end-user can access.

Although this initially only includes the default bucket, you might also include other buckets (if these are available to the user). As you bring in more data and users to Grail, relying just on the default buckets is not the optimal setup.
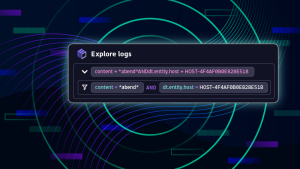
This is where filtering on custom buckets comes in. This allows you to query data from a specific bucket.
fetch logs
| filter dt.system.bucket=="prod_infra_logs" and loglevel=="ERROR"This example now includes an additional filter that restricts data retrieval from a certain bucket (prod_infra_logs).
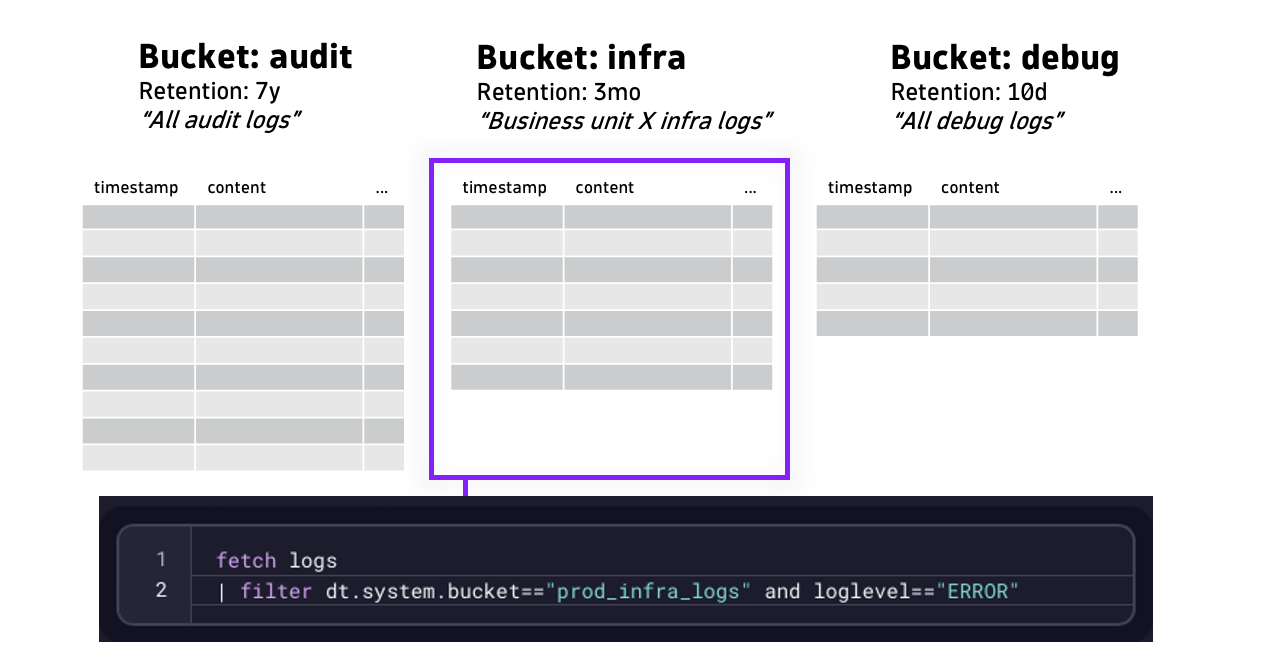
Using buckets to query only the data you need significantly speeds up queries and reduces query costs.
Buckets for data with high-security requirements
Buckets can also be used for managing high-level access control of data.
You can store access control logs or payment provider events in separate buckets to grant only limited SecOps or business administrators access to these logs.

Grail and AppEngine’s new policy-based access management provides a way to do this with buckets. For example, by adding a WHERE clause to the policy statement, you can define a specific bucket (=) or a range of buckets (STARTSWITH). In this example, the policy grants access to all buckets that have names starting with prod_infra_.
ALLOW storage:buckets:read WHERE storage:bucket-name STARTSWITH "prod_infra_";However, creating access policies solely on the bucket and table level is not scalable in a enterprise landscape, as one Dynatrace tenant can have a limited number of custom buckets. Instead, access control based on specific attributes like host groups or team assignments can be achieved using different policies that are based on supported attributes or security context.
Record-level permissions and security context
As covered in the previously linked blog post about access management, Dynatrace Grail brings a new architecture to permissions management. The new approach that uses security policies provides you with new dynamic controls for user authorization.
As using custom buckets opened up a basic approach to access where users could get access to a whole bucket, record-level permissions allow you to take a fine-grained approach.
This means that whenever you run a DQL query to fetch data from Grail, your policy-based access rights are evaluated, and records without defined access are filtered out.
This means your teams’ permissions are not constrained by data management decisions on a bucket level. Let’s say it makes sense to consolidate all short-living app debug logs to a bucket that has a short retention period. With record-level permissions, you can now ensure multiple app owners can see only their data in that bucket.
Another example would be a business unit admin who needs to have access to departmental data across buckets.
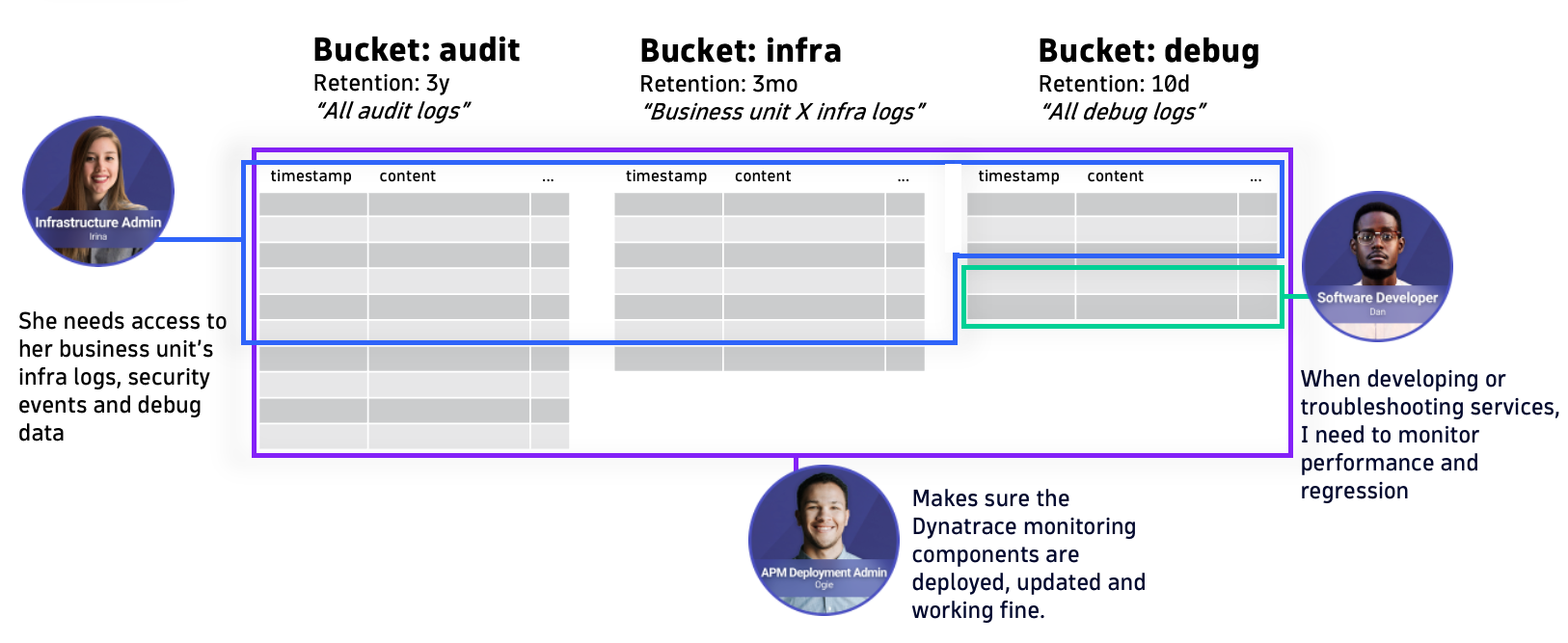
Permissions based on DQL fields and security context
To implement this in the Log Management and Analytics context, you can create policies with additional clauses that provide access.
ALLOW storage:logs:read
WHERE storage:k8s.namespace.name="abc"
AND storage:dt.host_group.id STARTSWITH "org1-";In this example, the policy allows access to logs that have a certain Kubernetes namespace (abc) and originate from a host group whose name must start with a specific string (org1-).
The list of standard table fields used in security policies provides flexibility for defining individual policies.
| DQL fields | Mainly used with |
| event.kind | events, bizevents |
| event.type | events, bizevents |
| event.provider | events, bizevents |
| k8s.namespace.name | events, bizevents, logs, metrics, spans |
| k8s.cluster.name | events, bizevents, logs, metrics, spans |
| host.name | events, bizevents, logs, metrics, spans |
| dt.host_group.id | events, bizevents, logs, metrics, spans |
| metric.key | metrics |
| service.name | events, bizevents, logs, metrics, spans |
| log.source | logs |
| dt.security_context | events, bizevents, system, logs, metrics, spans, entities |
| gcp.project.id | events, bizevents, logs, metrics |
| aws.account.id | events, bizevents, logs, metrics |
| azure.subscription | events, bizevents, logs, metrics |
| azure.resource.group | events, bizevents, logs, metrics |
When you look at the list of DQL fields, you’ll notice one reserved field, dt.security_context.
You can assign a value to dt.security_context during data ingest for use in a security policy, which is not covered by the list of previous DQL fields. You can explicitly set a value for dt.security_context for some logs, or take the value of an existing field.
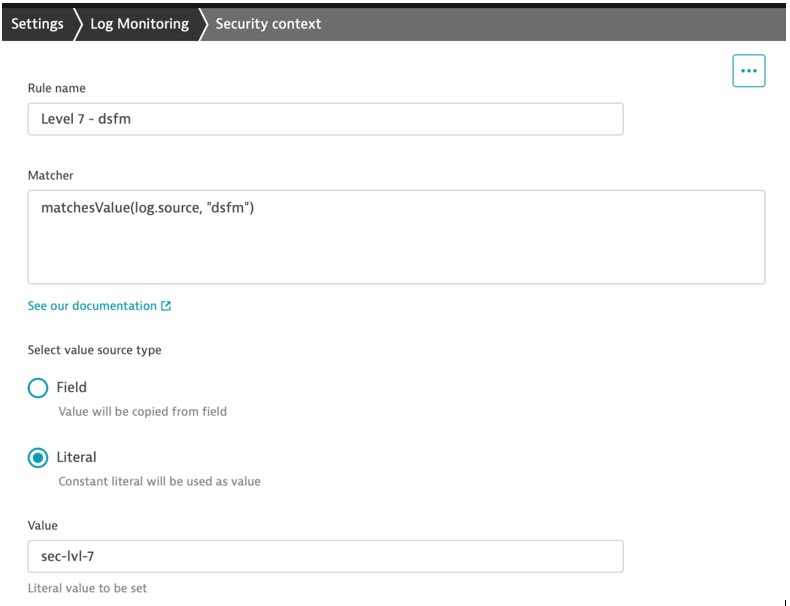
In this example, logs from a particular source (dsfm) are enriched with a literal value for dt.security_context (sec-lvl-7) during log ingest. A policy with a specific clause can provide access to only logs with this security context. Security context rule management is available via settings In the Dynatrace web UI and API.
This approach to granular record-level permissions opens up the flexibility needed in enterprise environments. You can craft policies based on existing fields like Kubernetes cluster or namespace, a host or a host group, a service name, or a log source. Or you can use security context for any other use cases, like granting access based on an AWS account, a GCP project, an Azure subscription, a username, or a team name.
Take the first step now
Many organizations have found immediate value in working with logs in Grail. Starting from optimizing their business and opening revenue streams based on data in logs to unlocking real-time insights from observability data and eliminating hours of manual work per process, as the Bank of Montreal did recently. Utilizing the core aspects of Grail, like buckets and permissions, sets organizations on the path to success.
Next steps
- Start a Dynatrace free trial and explore Log Management and Analytics powered by Grail
- Read our documentation explaining buckets, permissions in Grail, security context for logs, and IAM
- Record-level permissions for Grail are generally available with Dynatrace version 1.277. Custom buckets, in addition to bucket and table permissions, are available with Dynatrace version 1.265.
- Use Storage Management app to create and manage custom Grail buckets and unlock custom retention times for your data since Dynatrace version 1.281.
Special thanks to Dominik Punz and Christian Kiesewetter for contributing to this blog post.
Video demo
Watch this 7-minute video to see how you can use custom data buckets to separate use cases, data retention, and access permissions in Dynatrace.



Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum