
In Andi's recent blog, he notes that validating deployment is at best semi-automated. Learn how to auto-validate with Concourse, Dynatrace, and Pitometer.
In my colleague Andi Grabner’s recent blog on Automated Deployment and Architectural Validation, he notes that, based on a recent ACM survey, validating deployment still seems to be a semi-automated task for most software delivery teams. And, with the length of manual work directly contributes to the overall Commit Cycle Time, this to me shows room for automation and improvements!
I speak about automation quite often.
My most recent talks were around the concepts of using “shift-left” techniques to support build validation at the SpringOnePlatform, the North American Cloud Foundry Summit, and in a joint Pivotal webinar. These discussions, and some recent work with my colleagues around Pitometer, offered a welcome opportunity to talk more about my passion for Concourse and some new discoveries and practice improvements.
My four favorite things about Concourse
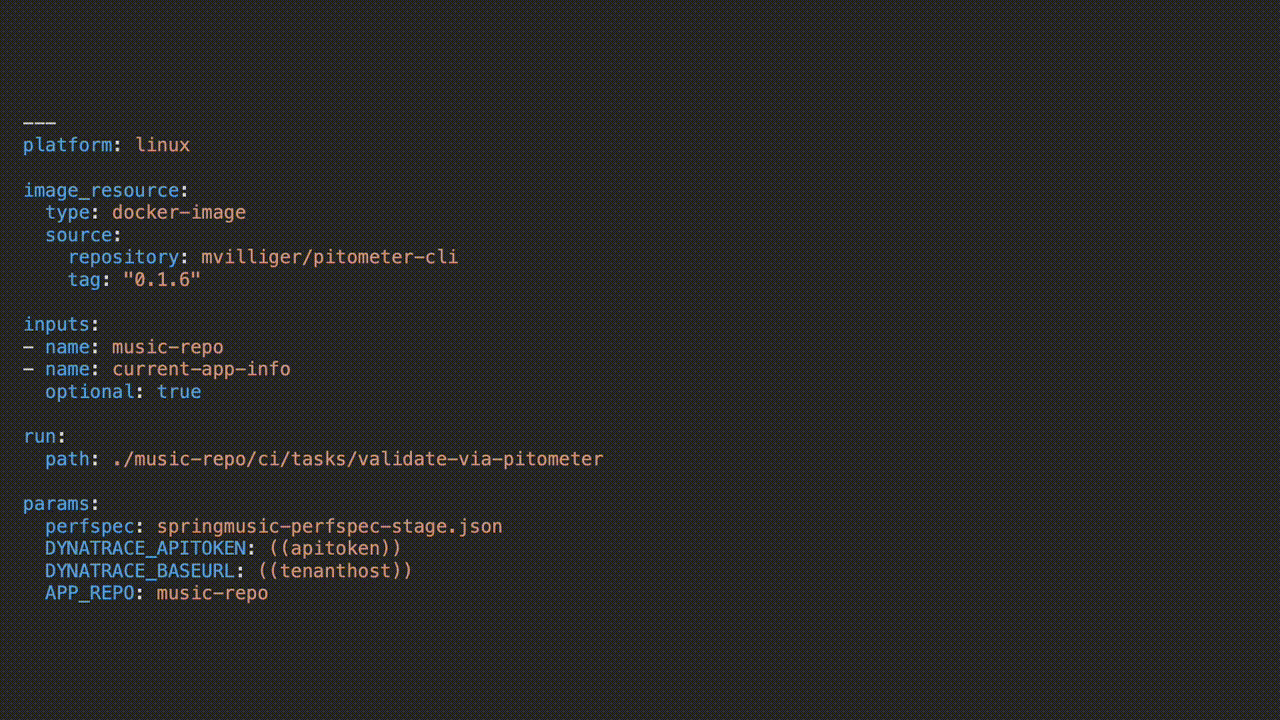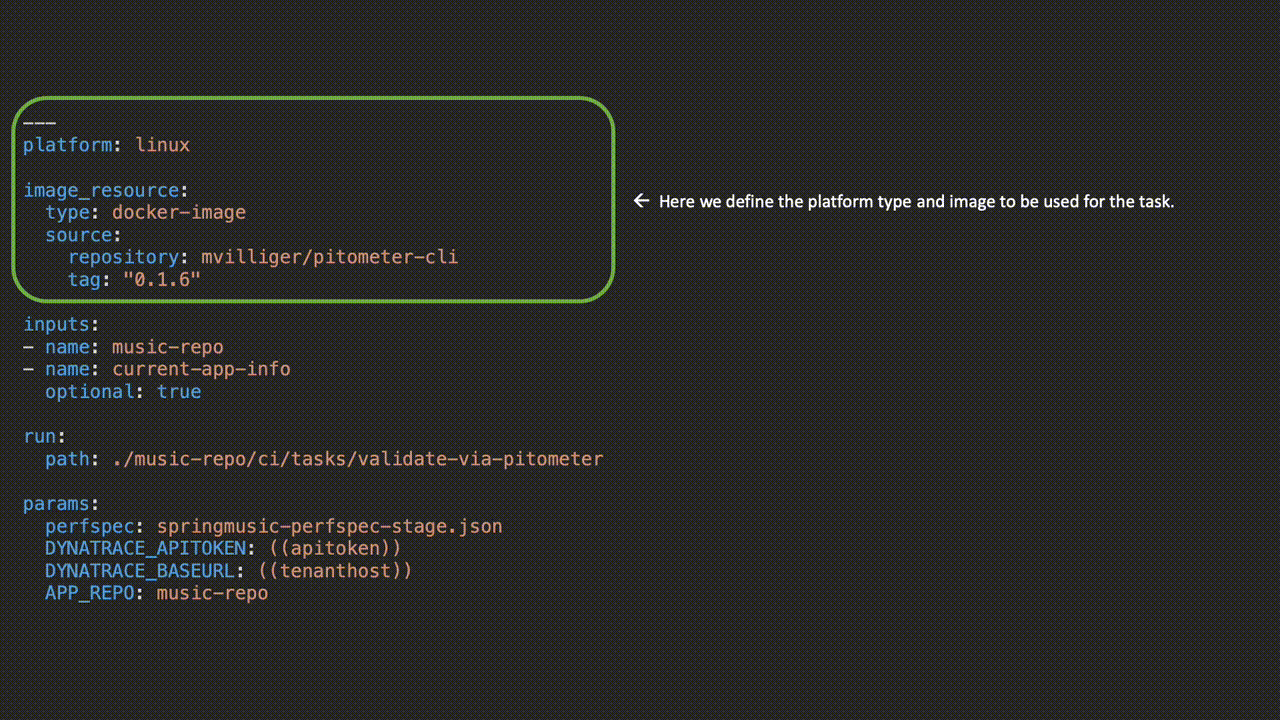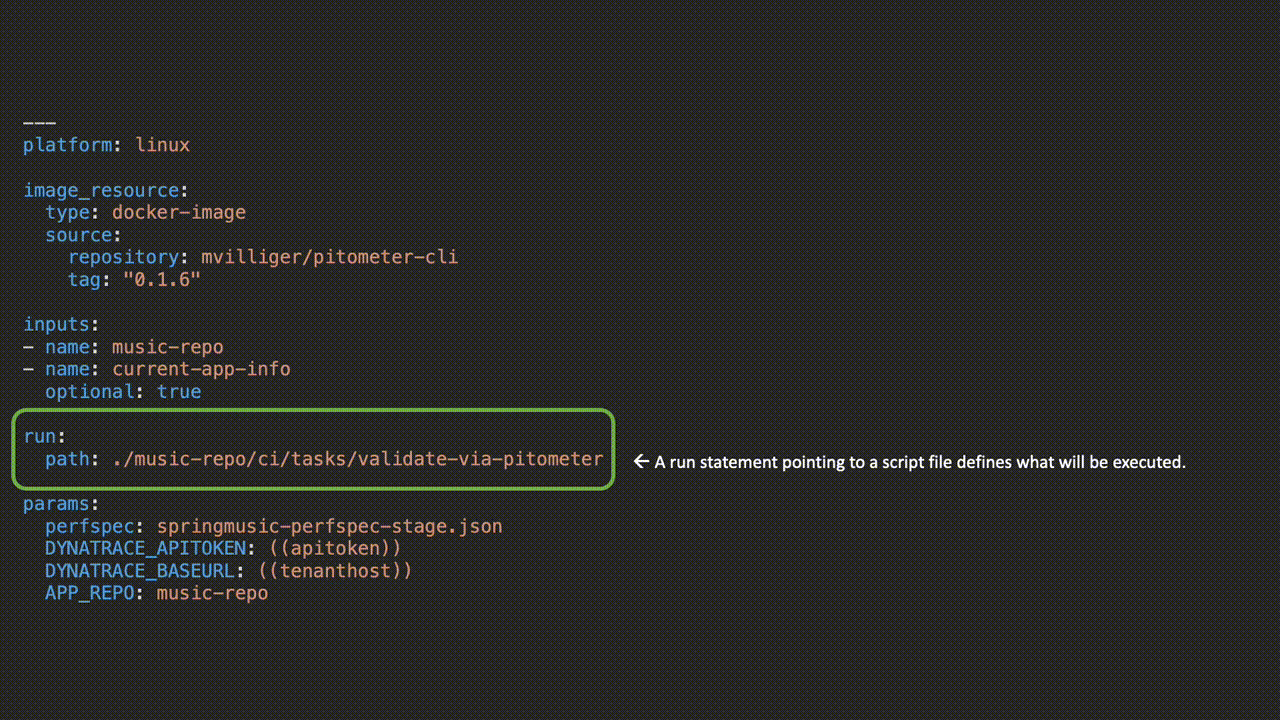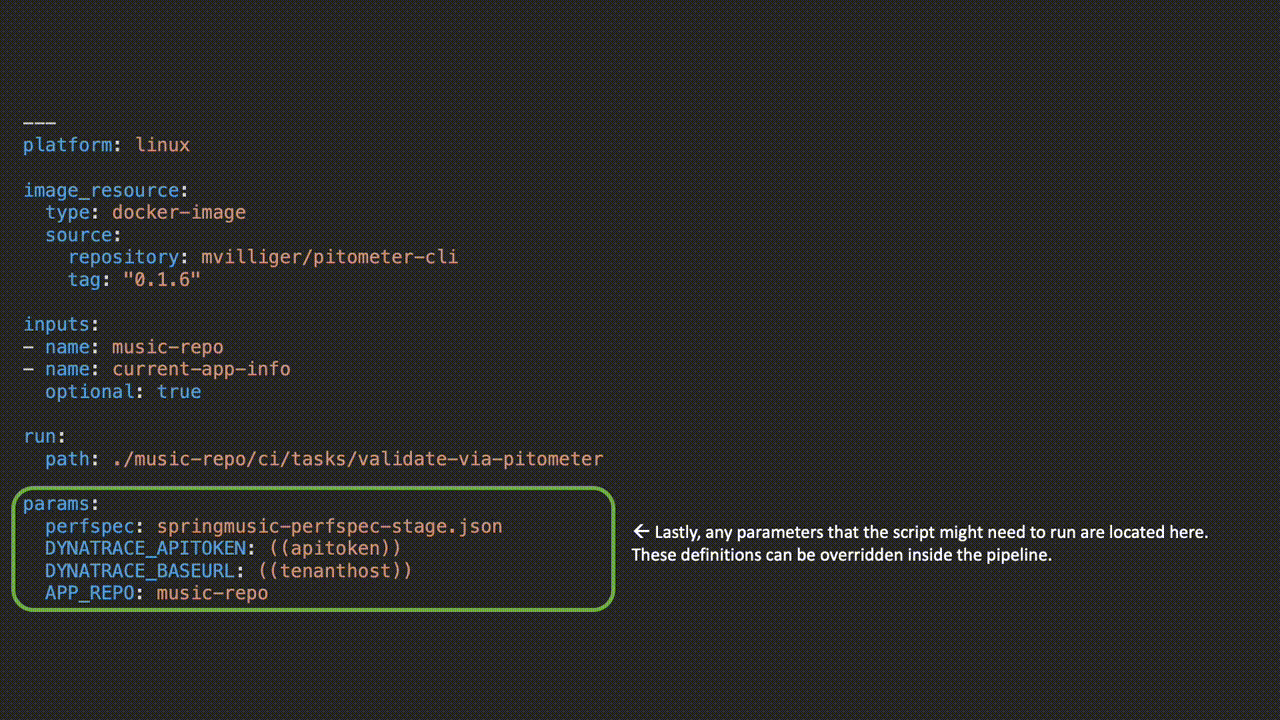
The folks at Pivotal who are responsible for Concourse describe it quite succinctly as an open-source continuous thing-doer. Going a bit deeper, I found four things particularly valuable.
- All of the steps of the pipeline are executed in a completely idempotent container created specifically to execute that task. This makes for consistent, repeatable builds. In the same way, you don’t want car wax residing in nooks and crannies of your car, you don’t want left-over residual files from previous builds in the environment that can cause additional troubleshooting time in build failures or inconsistent results.
- “All configuration and pipeline” definition itself is designed to live in source control. Not only does this makes it easy to version control and track changes to both the pipeline and configuration, but it also makes it trivial to re-deploy the pipeline if the built environment is lost to an outage.
- Concourse’s strong abstraction makes it nearly incidental to build integrations and define custom task steps. Rather than providing a complex plug-in architecture, Concourse simply provides an integration mechanism to check for changes, fetch bits, or push bits to some outside location.
- Custom tasks are as equally easy as Concourse handles the wiring, and task developers define the inputs and outputs – everything within is up to the developer.
In addition, Concourse also has a nice web-UI to visualize pipeline flow and status (see below).

Let’s take a deeper look at a real example pipeline
While not intended to be a step-by-step tutorial around building a Concourse pipeline, below is an example pipeline that unit tests, builds, and deploys a sample Java application to Cloud Foundry.
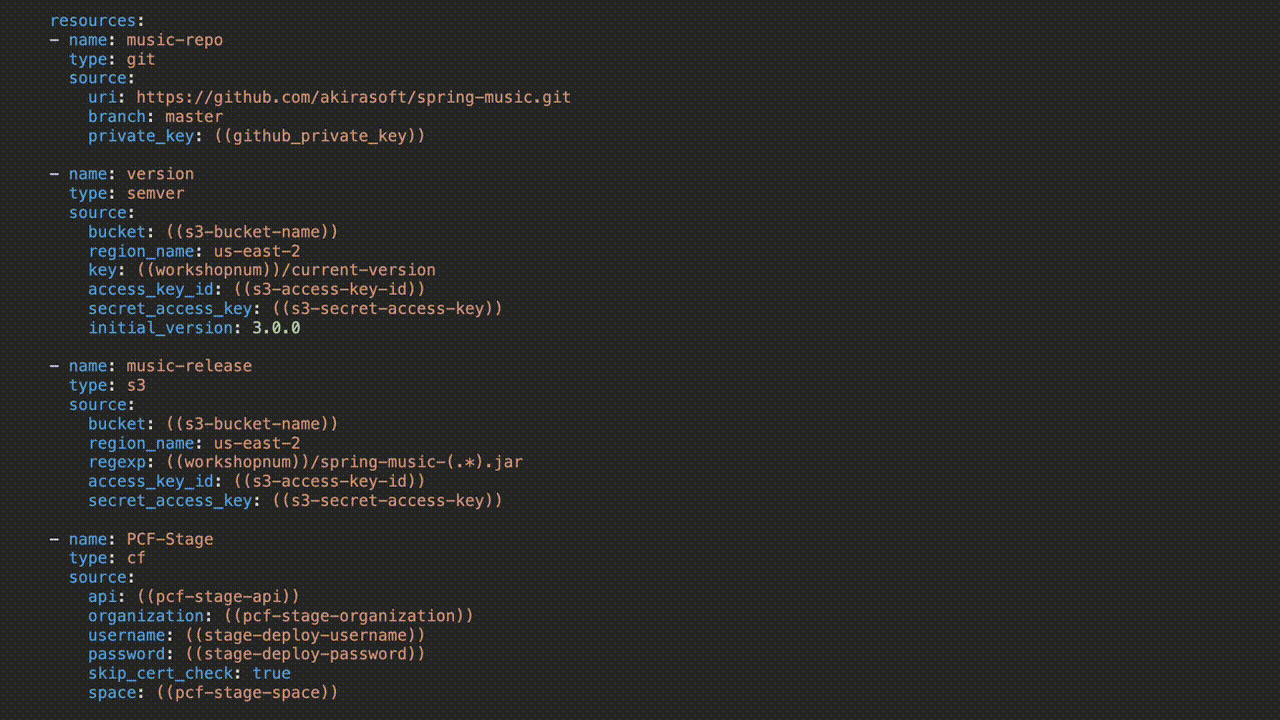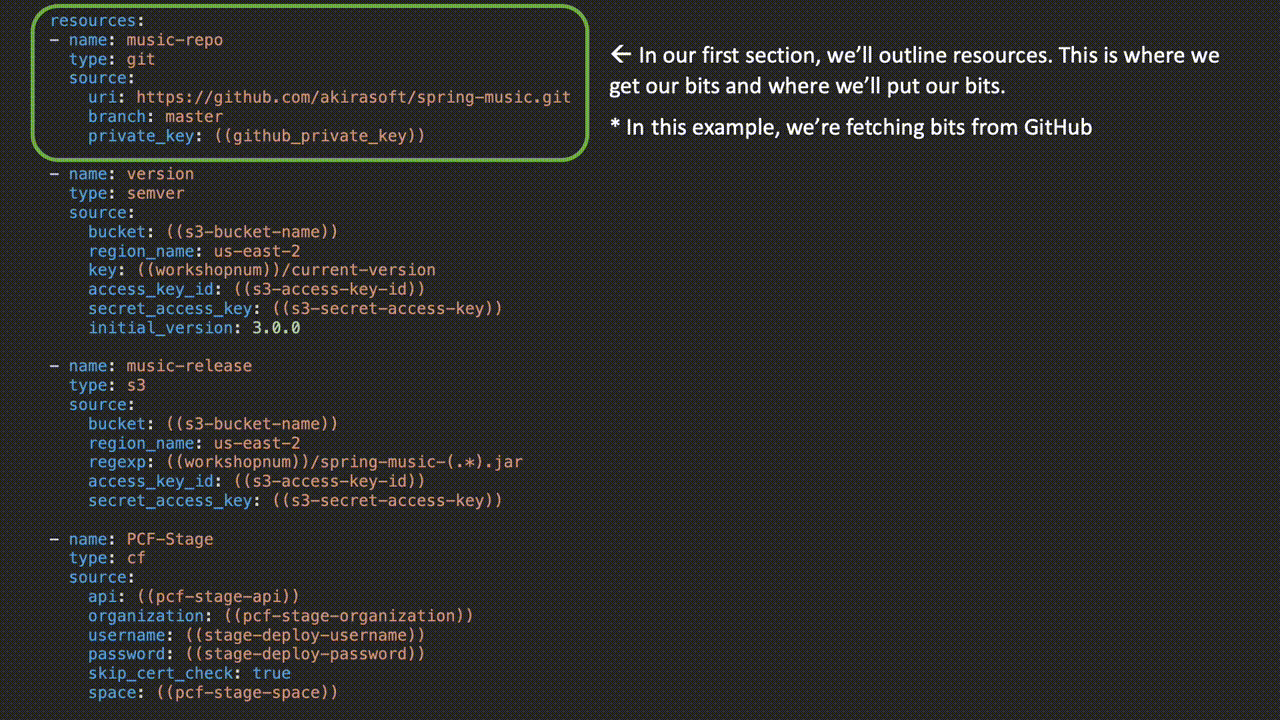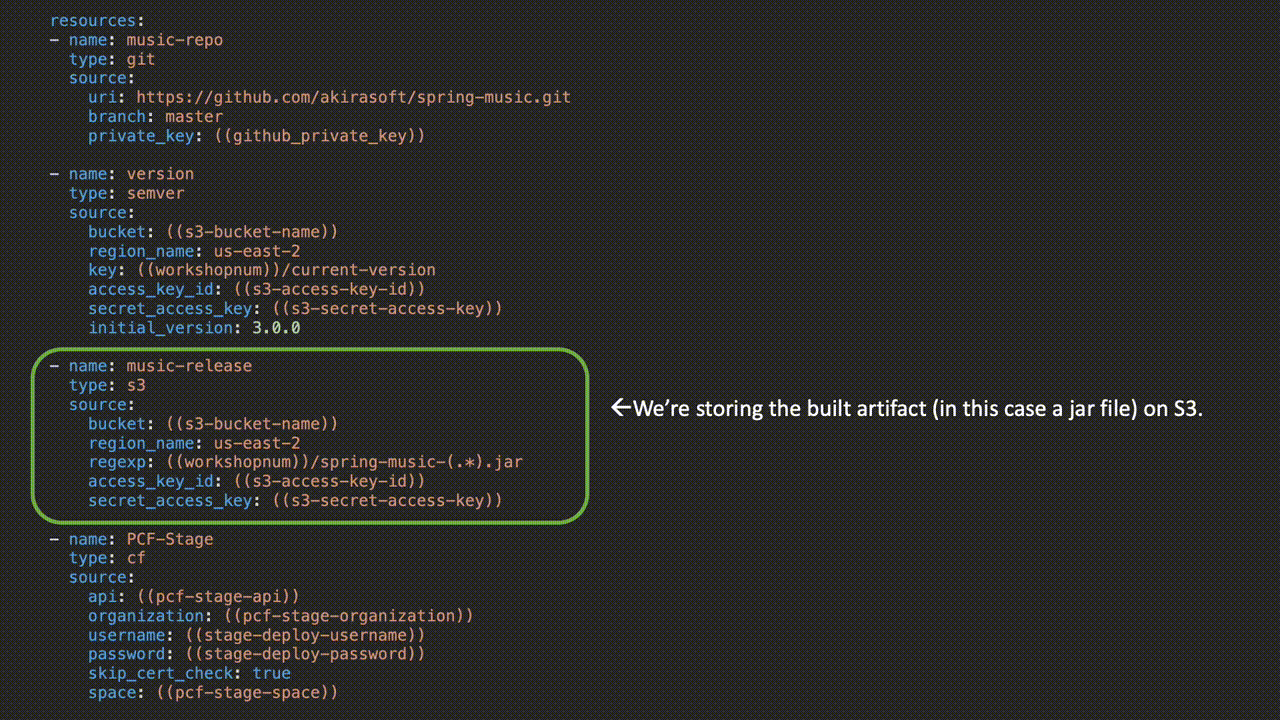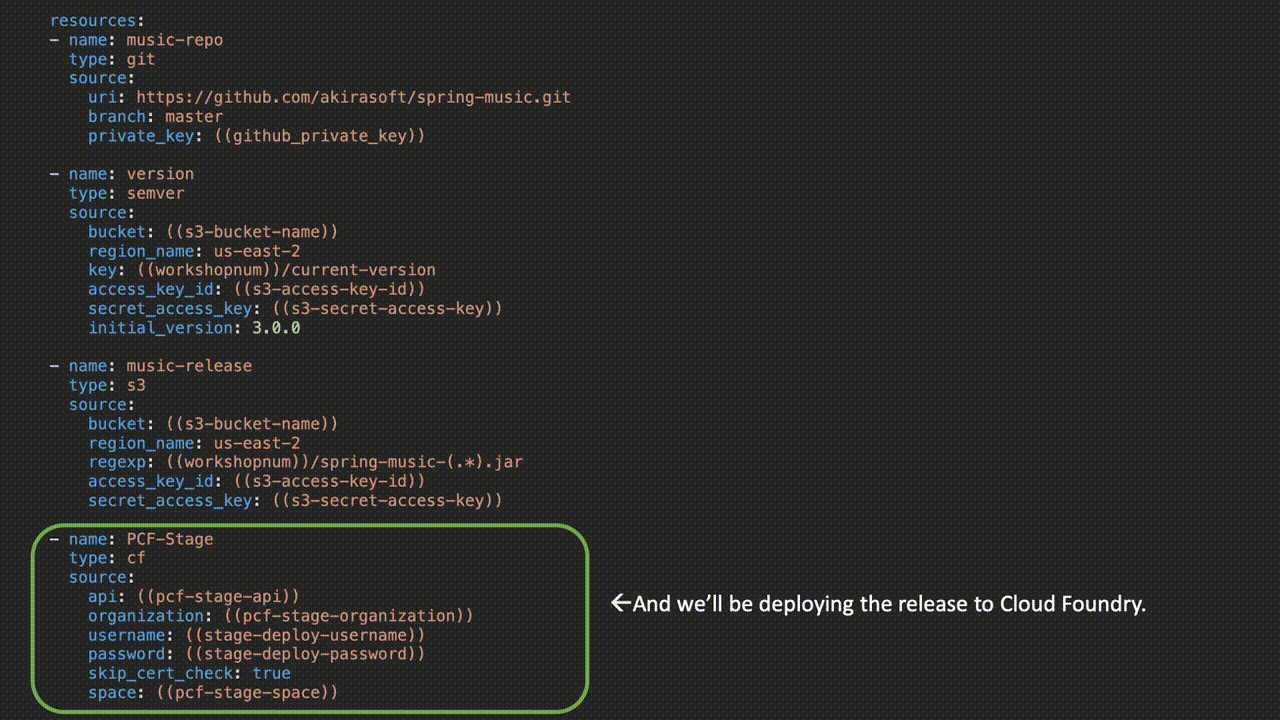 Here, we have the actual jobs where the work is happening:
Here, we have the actual jobs where the work is happening:
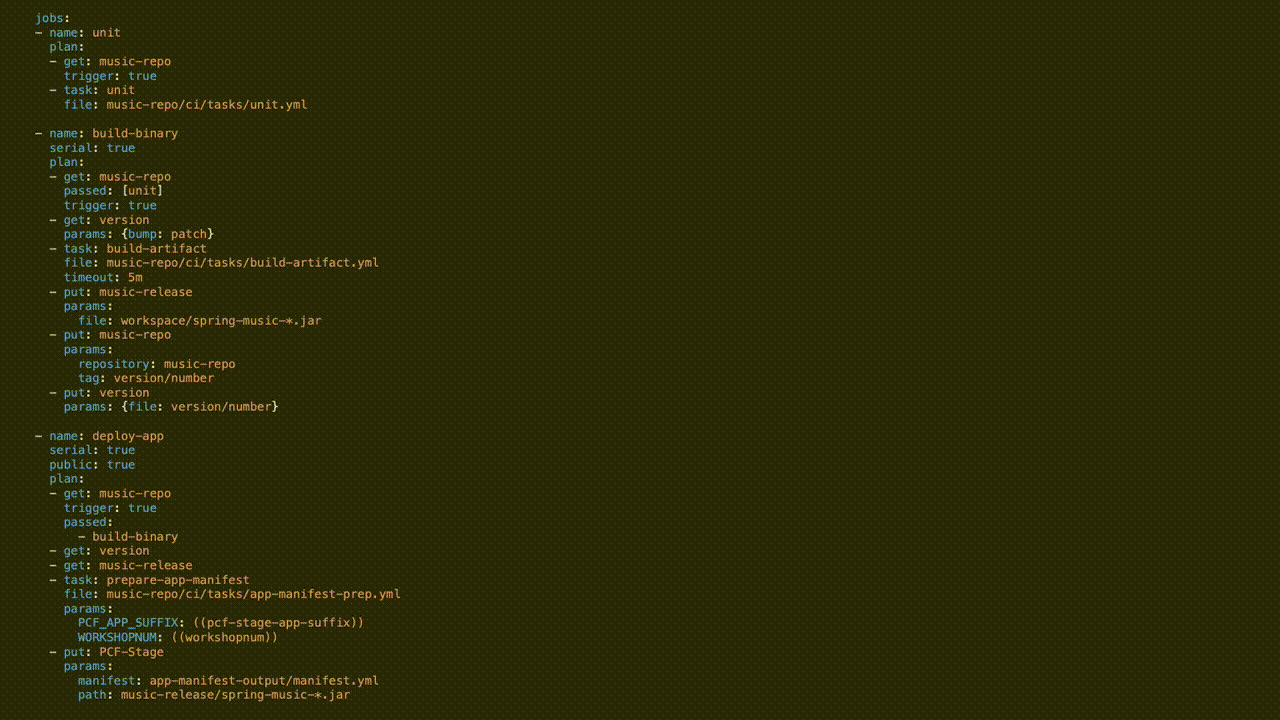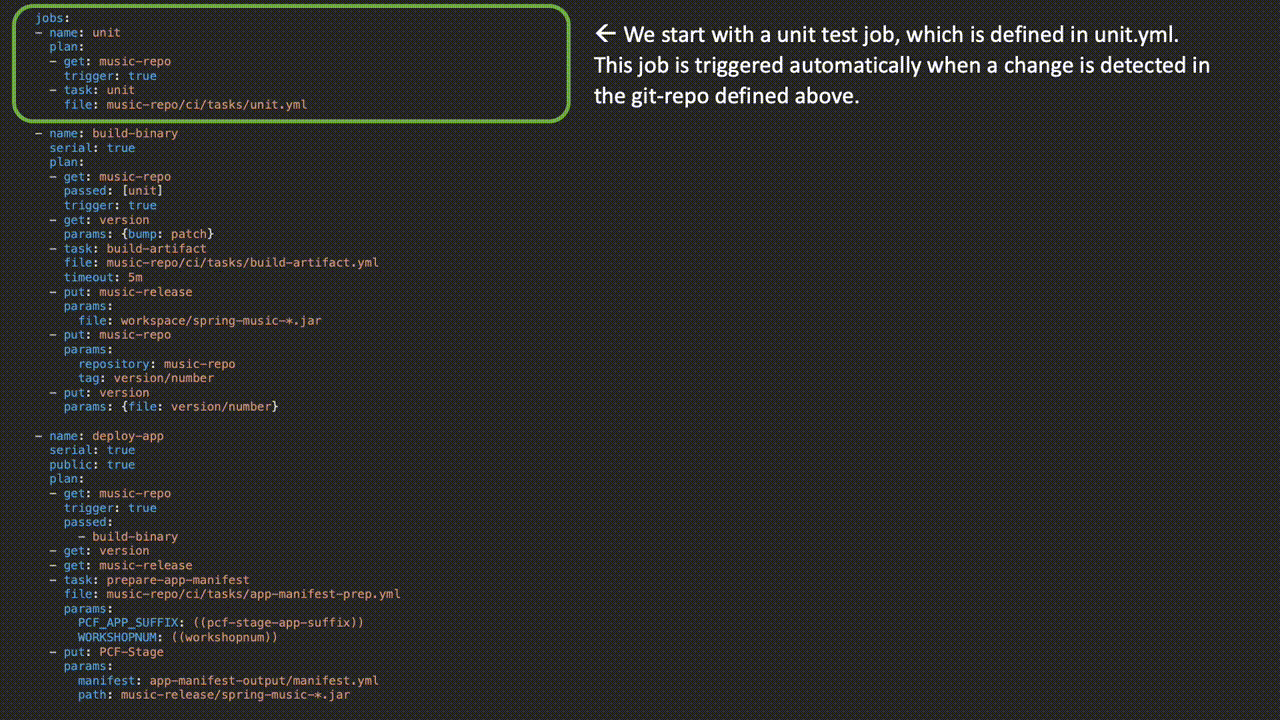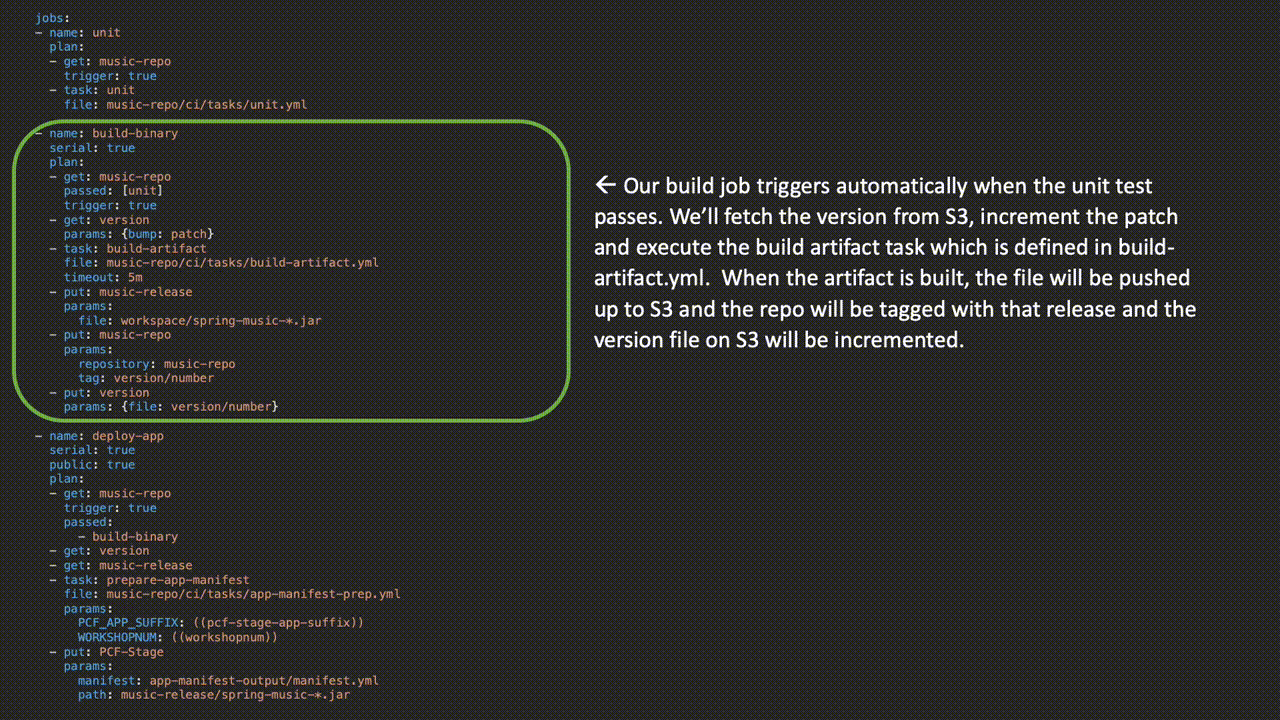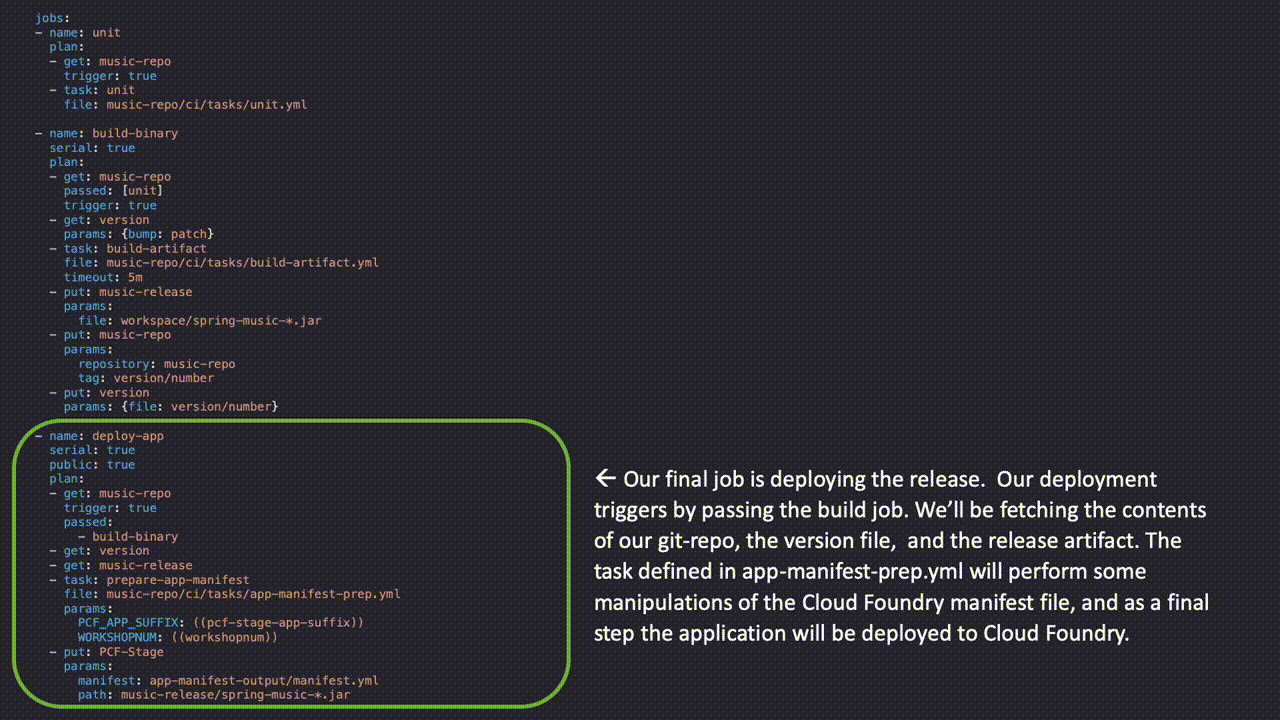
Parameters wrapped in parenthesis are replaced when the pipeline is uploaded to Concourse via either a credentials file or from a credentials store like Vault or Credhub. Check out the entire pipeline on GitHub here.
Shift-right and leverage build data with Dynatrace
While the above example fully takes a sample application from code change committed to source-control through deployment, the pipeline can now be enhanced in several ways.
One valuable and easy enhancement is to “shift-right” the build event metadata and push it to the Dynatrace AI engine, Davis®.
Once sent to Dynatrace, the build events will be shown alongside the monitored services and can then be included and referenced as a possible root-cause when sleuthing performance and availability degradations.
Sending build event metadata from Concourse to Dynatrace is made even easier with a Dynatrace Concourse resource. This Dynatrace resource will post the data to the Dynatrace’s event API and make use of “monitoring-as-code” monspec files stored alongside the application source code. This will determine which entities need to receive the event. Read more about monspec in our AWS DevOps Tutorial here.
Integrating the Dynatrace resource into a pipeline is simple
![]()


A more robust pipeline example containing usage of the Dynatrace resource as well as performance tests can be found here.
Shift-left and improving quality gates with Pitometer
For a truly unbreakable continuous delivery pipeline, you must also include “shift-left” quality gates.
Previously, I’d implemented these via a Concourse task that utilized Andi Grabner’s dtcli but the introduction of Pitometer gives us a great opportunity to revisit this cool functionality.
Pitometer has a pluggable source and grader functionality that allows for a flexible framework to evaluate both performance and architectural requirements in perfspec files, collocated with our application code in source-control.
My colleague, Rob Jahn, had already begun work on creating a cli implementation of Pitometer and from this, we were able to collaborate on a number of improvements culminating in making the cli available packaged up in a Docker container. Once available via a container it was a simple matter of making a new Concourse task.
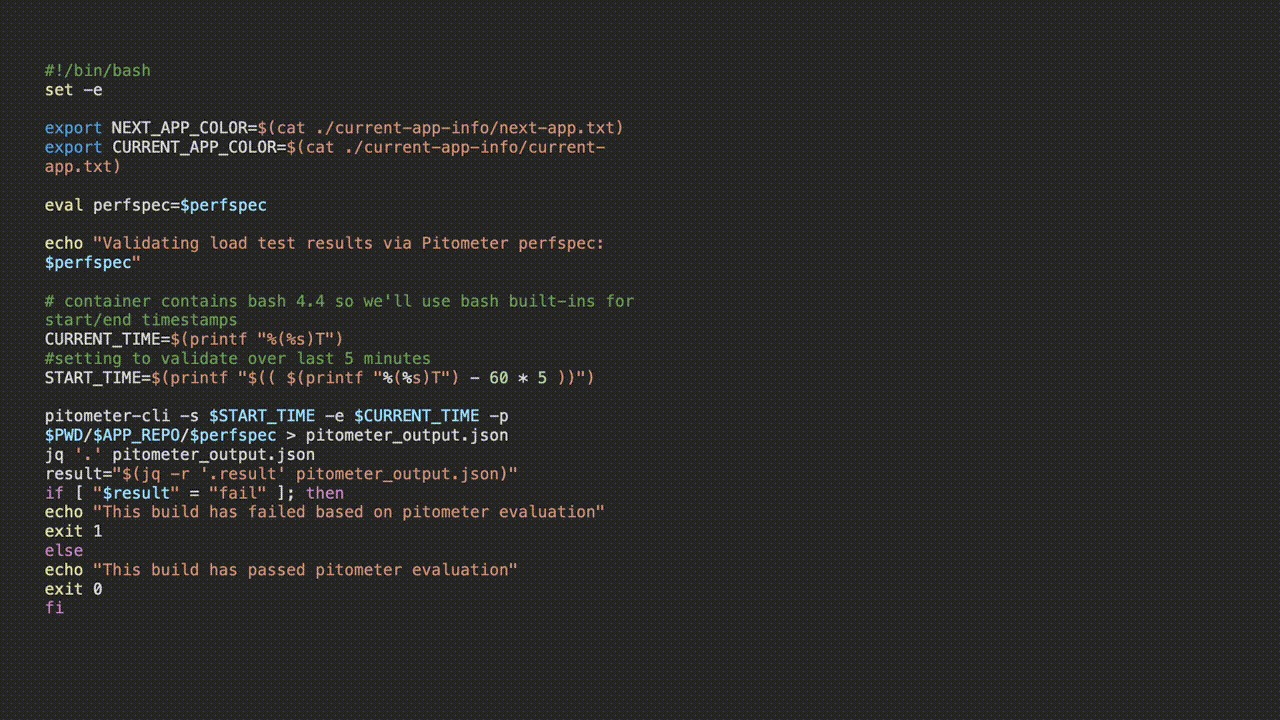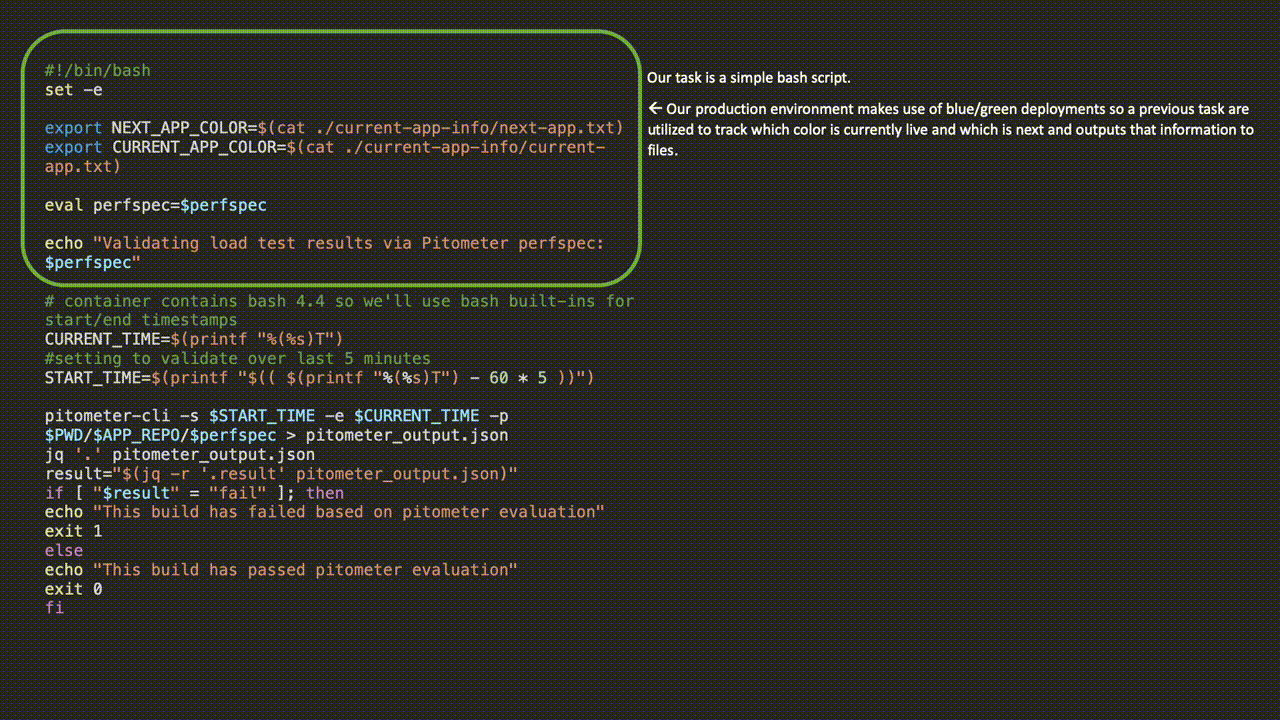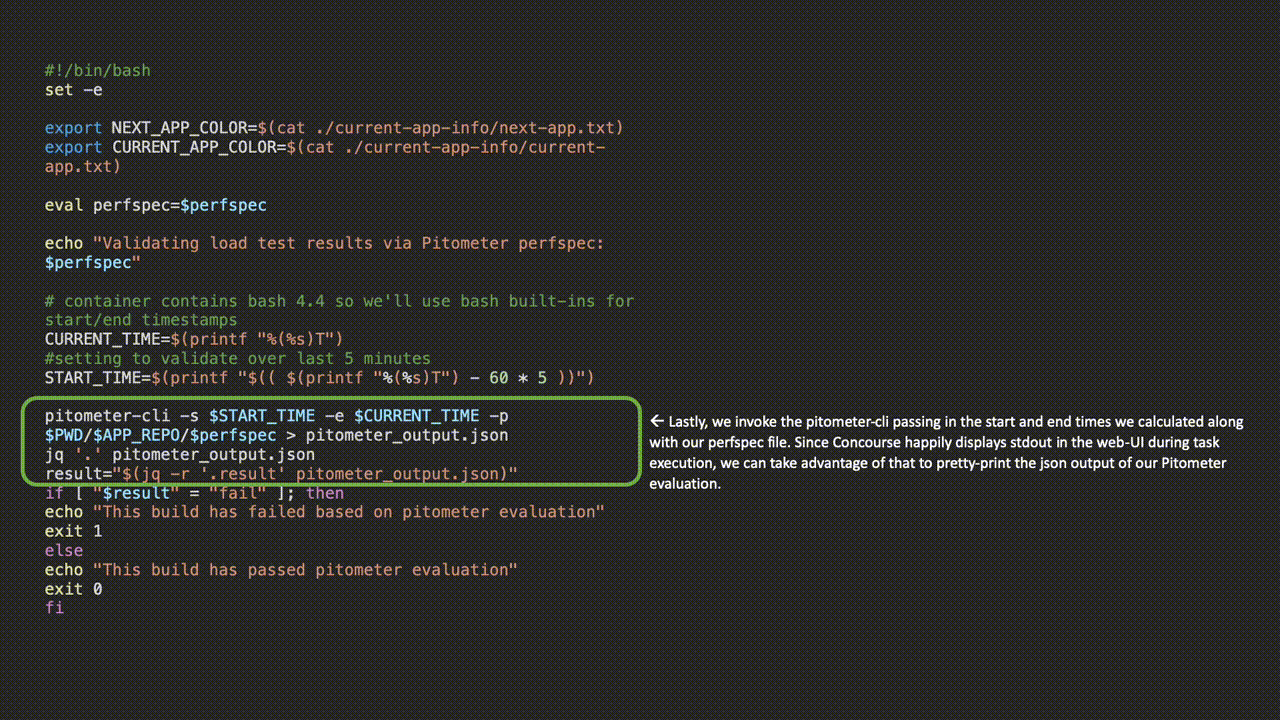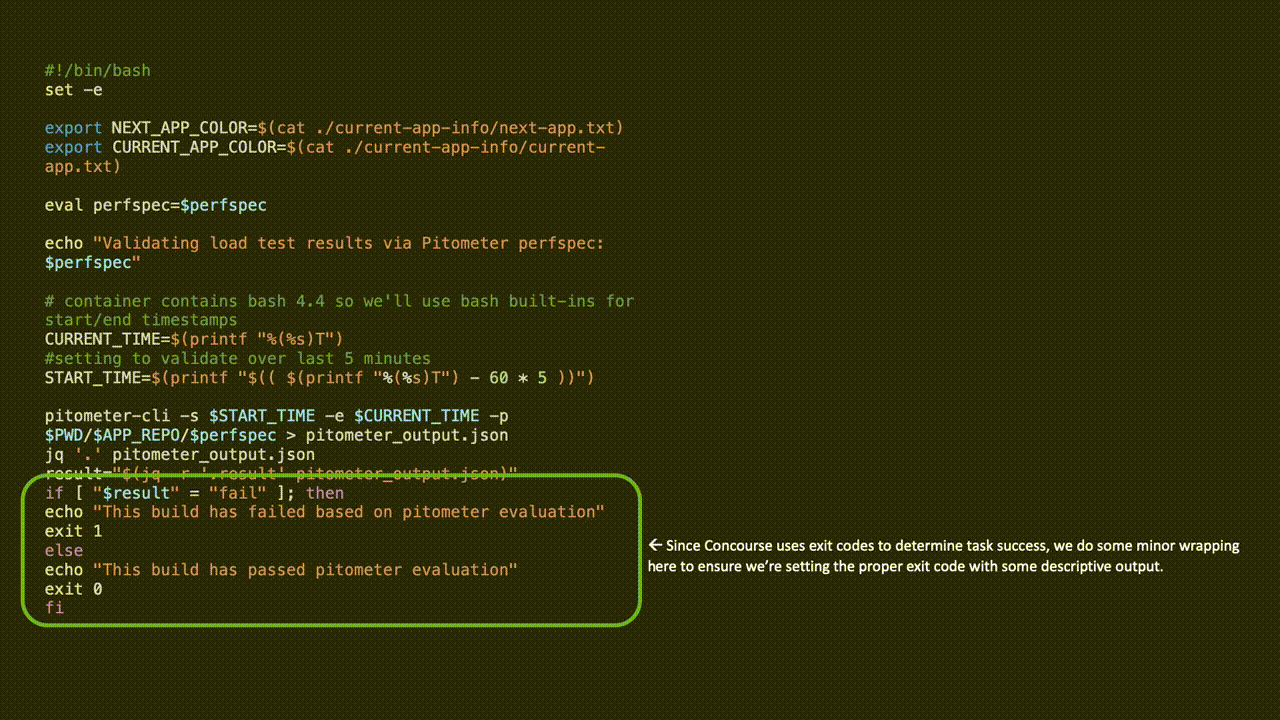
![]()
Upon task execution in the pipeline, Concourse will persist the pretty printed output from the task and allow us to see the Pitometer output as well as task or failure status at a glance.

In this example, we had a pass threshold of 90 being passed into the grader. We can see that our response time measures and error rate measures have all failed while our architectural validation (“OutgoingDependencies_SpringMusic”) has passed giving us a total build score of 10. This is WELL below the score of 90 that is necessary to pass. This build has failed and our pipeline will be halted at this step.
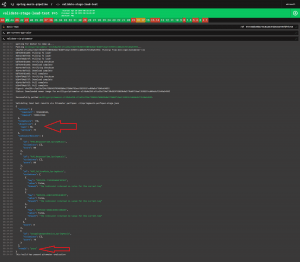
Again, the threshold for the build is a score of 90 but this time we have passed because all of the subsequent measures have passed. This passed quality gate will now move onto the next step of the pipeline.
A complete sample reference pipeline with Dynatrace resource, Pitometer task, as well as an example validated blue/green deployment is available on my GitHub here.




Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum