
Organizations choose data-driven approaches to maximize the value of their data, achieve better business outcomes, and realize cost savings by improving their products, services, and processes. However, there are many obstacles and limitations along the way to becoming a data-driven organization. The following are some of the most pressing challenges:
- Managing cost and scale of large data. The exponential growth of data volume—including observability, security, software lifecycle, and business data—forces organizations to deal with cost increases while providing flexible, robust, and scalable ingest.
- Understanding the context. With siloed data sources, heterogeneous data types—including metrics, traces, logs, user behavior, business events, vulnerabilities, threats, lifecycle events, and more—and increasing tool sprawl, it’s next to impossible to offer users real-time access to data in a unified, contextualized view.
- Addressing security requirements. Organizations need to ensure their solutions meet security and privacy requirements through certified high-performance filtering, masking, routing, and encryption technologies while remaining easy to configure and operate.
Dynatrace is addressing these challenges with a single, built-in data ingest functionality: Dynatrace OpenPipeline™, the ultimate addition for data-driven organizations.
Introducing Dynatrace OpenPipeline
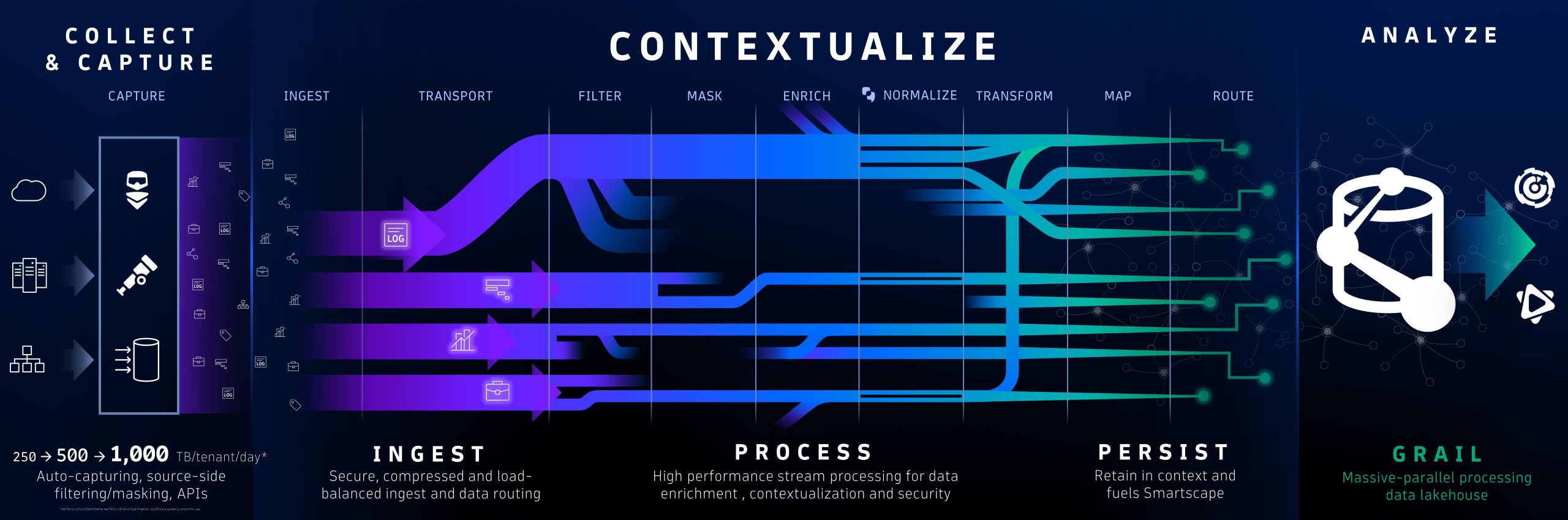
OpenPipeline is a stream-processing technology that transforms how the Dynatrace platform ingests data from any source, at any scale, and in any format. With OpenPipeline, you can easily collect data from Dynatrace OneAgent®, open source collectors such as OpenTelemetry, or other third-party tools. OpenPipeline then filters and preprocesses that data to manage and reduce costs.
OpenPipeline also includes data contextualization technology, which enriches data with metadata and links it to other relevant data sources. By putting data in context, OpenPipeline enables the Dynatrace platform to deliver AI-driven insights, analytics, and automation for customers across observability, security, software lifecycle, and business domains.
Furthermore, OpenPipeline is a data security and privacy technology that ensures data is collected and processed securely and compliantly, with high-performance filtering, masking, routing, and encryption capabilities that are easy to configure and operate.
OpenPipeline works seamlessly with Dynatrace Grail™ to handle data ingest at an unparalleled scale. During the data ingestion process, OpenPipeline enriches data and data signals with their context and simultaneously interconnects them with Smartscape®, a real-time interactive map that reflects the topology and dependencies of all data signals. This “data in context” feeds Davis® AI, the Dynatrace hypermodal AI, and enables schema-less and index-free analytics. Unlike other pipelining solutions that serve to consolidate and move data from one place to another, OpenPipeline enhances the Dynatrace platform and allows users to extract even more value from their data.
Scale beyond petabytes
Dynatrace can collect data from the full application stack without configuration—including metrics, traces, logs, user sessions, security events, business events, and more. OpenPipeline unifies the ingestion of data sent to Dynatrace from any source in any format. During transport, data is prioritized, compressed and encrypted, ensuring data integrity and protection. Data is then dynamically routed into pipelines for further processing.
Designed to reach beyond petabyte (PB) scale, OpenPipeline will—at its launch—quintuple the ingest throughput from 100 TB a day per tenant to 500 TB a day per tenant. Further scaling, to and beyond 1 PB per day, will be announced in the near future.
This massive increase in data-ingestion throughput is possible thanks to several patent-pending high-performance stream-processing technologies, including a breakthrough in the simultaneous processing of thousands of data-processing rules. OpenPipeline rule processing outperforms most rule-processing algorithms by magnitudes (by a factor of 6-10 compared to prior art), with lower memory consumption and no degradation in data throughput.
Manage the cost of data with ease
With the exponential growth of data, and the need to retain data longer for business and security reasons, it’s important to preprocess and manage data appropriately to maximize value and minimize cost. OpenPipeline high-performance filtering and preprocessing provides full ingest and storage control for the Dynatrace platform. As a result, dedicated data pipeline tools are unnecessary for preprocessing data before ingest.
Filtering data is crucial for privacy and compliance to minimize the exposure of sensitive data. Additionally, it helps to reduce data volume and keep the cost of storing and querying data under control by eliminating duplicates, redundancies, and dropping unnecessary data fields. As an example, in early preview usage, AWS GuardDuty events were reduced by 84% by filtering out security-irrelevant events, which reduced cost and alert noise at the same time.
Transformations preprocess data and reduce data volume further, especially in situations where raw data is not required. OpenPipeline extracts data with context and transforms it into more efficient formats, for example, logs to metrics. Such transformations can reduce storage costs by 99%.
Routing of data to specific Grail buckets of varying retention durations lets you decide which data to keep and for how long. It also separates data organizationally for improved access control and focused query scope.
Protect your sensitive data
- Privacy by design. One essential aspect of OpenPipeline is the ability to mask data at capture using OneAgent® and automatic, rule-based processing. This approach suppresses sensitive data capture entirely before the data leaves the process, service, or customer environment. This ensures compliance and protects sensitive information from the start.
- Commitment to privacy. Dynatrace Trust Center demonstrates the Dynatrace commitment to privacy (and security) by design. Masking personal and sensitive data is of vital importance. With OpenPipeline, Dynatrace users can configure filtering and masking to their specific needs.
Bring data into context for improved analytics, automation, and AI
As OpenPipeline processes data streams in real time and it retains context during data normalization. At the same time, it performs contextual enrichment to ensure high-fidelity analytics, automation, and AI. With OpenPipeline processing power, you can:
- Enrich data and improve its value and quality by adding supplemental attributes (such as IP address geolocation or the related trace ID to a log line).
- Normalize data without losing context, as it detects known data structures automatically and provides optional rules for custom data structures.
- Transform contents into well-defined fields, convert raw data to time series, calculate metrics, or create business events from log lines.
- Converge heterogeneous data sources with ease, as data normalization and contextual enrichment can also happen on read, thanks to the schemaless and indexless approach of Grail.
- Contextualize and map data and get a unified view by identifying and connecting data points to the topology and dependencies within a software environment using the Dynatrace Semantic Dictionary. This contextualization provides Grail with additional semantic information in real time.
- Prioritize business data for a desired quality of service (QoS). Dynatrace provides unmatched accuracy by treating relevant business data (for example, real-time consumption or revenue dashboarding and analytics) with a higher priority and ensuring that data is not only in context but also not dropped or sampled.
Such contextually enriched data is the key to unlocking the full potential of your data for improved analytics, automation, and AI. By adding metadata and linking data to other relevant data sources, you enhance the quality, accuracy, and value of your data.
Davis—the unique Dynatrace hypermodal AI—builds on more than a decade of AI expertise in predictive and causal AI, and as announced recently, generative AI technologies. Automation and business observability require precise results. Contextually enriched data enables unrivaled predictive and causal AI power that provides real-time risk and root-cause analysis, enabling immediate insights and automated, AI-powered IT operations.
OpenPipeline in action
Let’s take a look at a concrete example—a logline that contains the following information:
2024-01-31 15:08:12 INFO [user-service] User john.doe@example.com logged in from 192.168.0.1
OpenPipeline can parse this logline and extract the following fields:
- Timestamp:
2024-01-31 15:08:12 - Log level:
INFO - Service name:
user-service - User email:
john.doe@example.com - User IP:
192.168.0.1
From here, OpenPipeline can convert this log entry into a time series metric that counts the number of logins per service, or create a business event that triggers an alert or notification when a user logs in.
With no schema or indexing, Grail even handles such data normalization and contextual enrichment “on read” as well, which makes it even easier to converge heterogeneous data sources. This additional power is enabled by the Dynatrace Semantic Dictionary, which provides Grail additional semantic information in real-time for the mapping of topology and dependencies within a software environment. Let’s look at another example, where a data source contains the following information:
{
"user_id": "123456789",
"user_email": "john.doe@example.com",
"user_name": "John Doe",
"user_role": "admin",
"user_location": "Linz, Austria"
}
Grail can use the Dynatrace Semantic Dictionary to map the user_email field to the User email field extracted above by OpenPipeline and enrich the data with additional context, such as user_id, user_name, user_role, and user_location. This way, Grail can provide a holistic view of the user and their activities across different data sources.
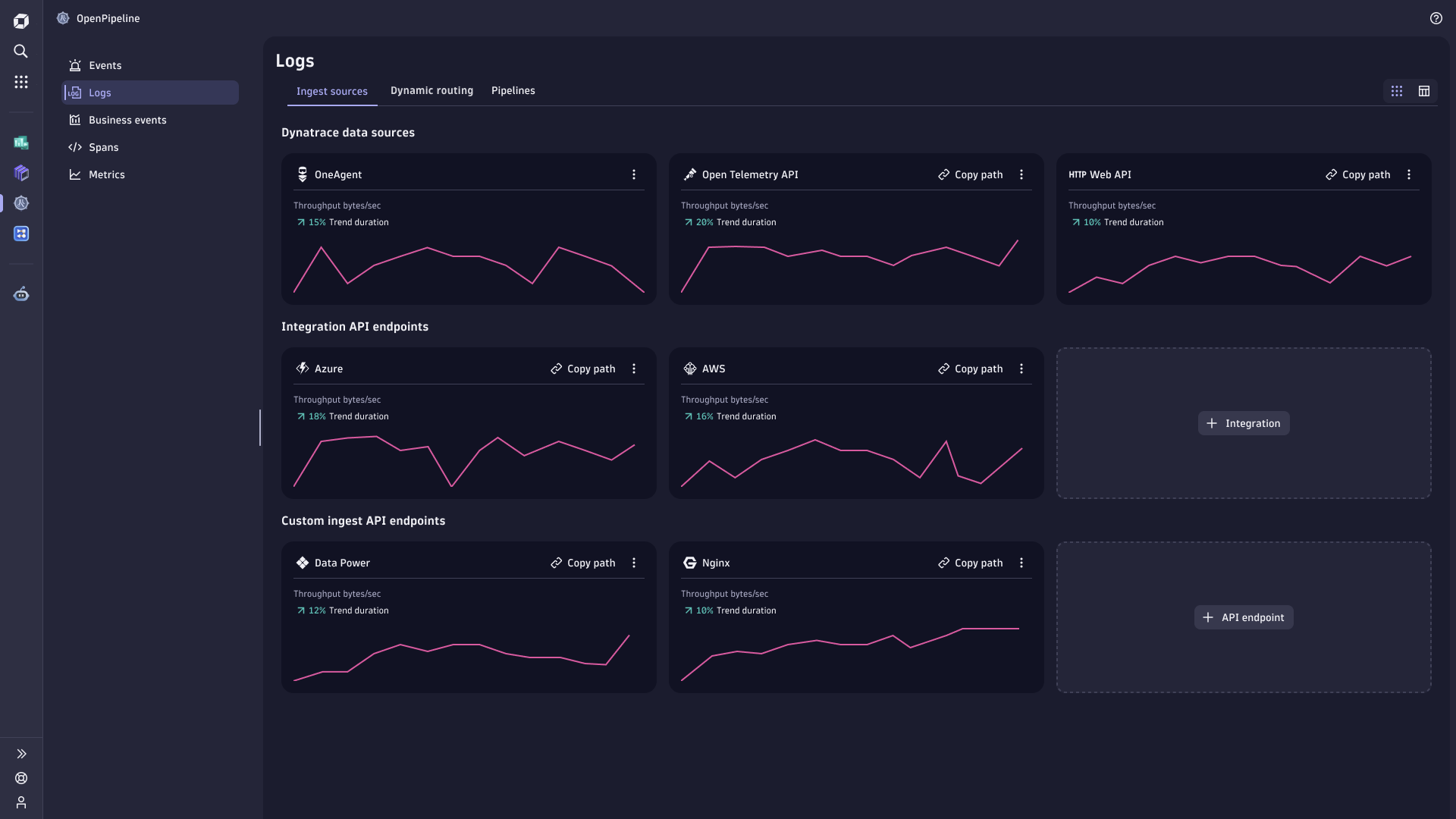
OpenPipeline is part of the unified Settings experience, inside the built-in Settings app
OpenPipeline offers an easy way to create and configure routes and pipelines at scale, comfortably situated within the Settings app. This app simplifies the configuration process by utilizing Dynatrace query language (DQL) for matching and processing routes. Of course, configuration-as-code using an application programming interface (API) is also available.
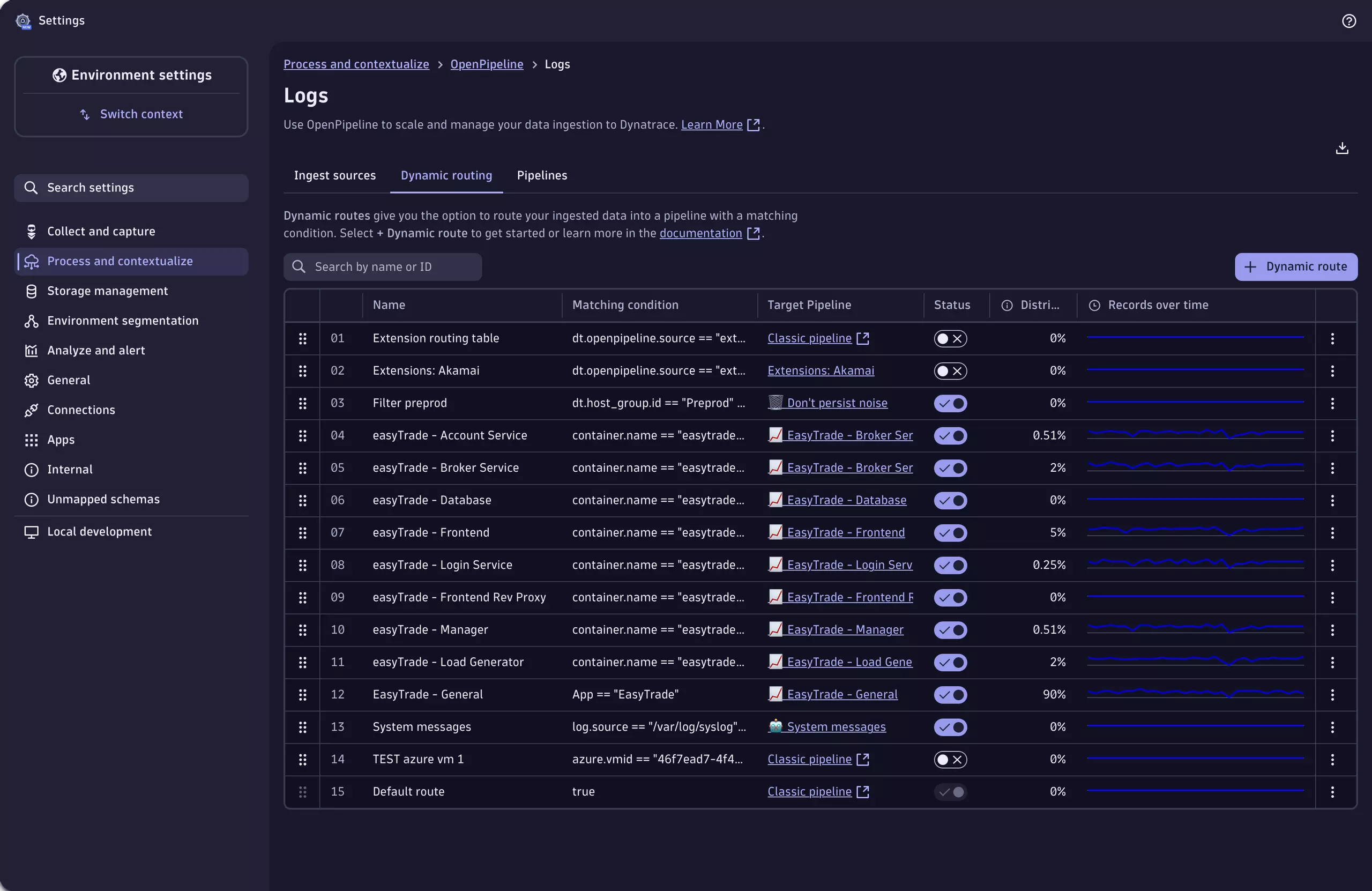
Visual guidance within the user interface is available to administrators for managing rules, setting up ingestion configurations, dynamic routing into individual pipelines, controlling data enrichment and transformation policies, and sending data from a source to its destination (such as specific Grail buckets).
You can read more about setting up and managing pipelines in our documentation.
Get more value from your data with OpenPipeline
OpenPipeline complements Grail with high-performance stream processing to maximize security and ease the management of large heterogeneous data, while minimizing cost. It manages parallel pipelines to ingest, transport, mask, filter, enrich, normalize, transform, contextualize, route, and persist data. OpenPipeline is available to Dynatrace customers at no additional cost.
- OpenPipeline enables cost-effective and scalable data ingest, with up to 500 TB per day per tenant, with plans to go beyond the petabyte-per-day level in the near future. It also offers built-in data transformation features that reduce storage costs by up to 99%.
- OpenPipeline contextualizes data in real time with enrichment, discovered topology, and tags. Using its patent-pending stream-processing technologies, OpenPipeline optimizes data for Dynatrace analytics and AI.
- OpenPipeline ensures data security and privacy with source-side masking and encryption at the source, additional filtering, and masking at ingest. In combination with Grail, this ensures data privacy and compliance at the storage and query level. Such a centralized data management approach has substantial potential to reduce security and audit efforts.
The first release of Dynatrace OpenPipeline, supporting logs, business events, and generic events, will be released within 90 days. Once available, Dynatrace SaaS customers running on AWS or Azure, and using the latest version of Dynatrace, can start using OpenPipeline without installing anything: the OpenPipeline Configuration app will be pre-installed on all eligible tenants. Existing processing rules for logs and business events will be automatically migrated to new pipelines, so existing customers will benefit from the new OpenPipeline functionality from day one.


Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum