
Dynatrace Davis® AI detects problems, underlying root causes, business impact, and SLO impact across your full-stack production deployments. Dynatrace® Cloud Automation uses this information to trigger and execute remediation actions and observability-based validations. This blog post explains how Dynatrace Cloud Automation protects your production environments with automated remediation actions.
While development teams focus on innovation and quick release cycles, operations teams and Site Reliability Engineers (SREs) focus on stability. Of course, your customers expect both fast innovation and reliability.
Dynatrace Cloud Automation lets you track your most critical SLO). Further, it enables you to release with confidence by catching poor quality code before it reaches production. Now, we’re happy to extend our Cloud Automation offering with automated problem remediation.
The costs of downtime
Surveys suggest that a single hour of downtime can cost an organization from $1 million to over $5 million. For Fortune 1,000 companies, the average costs of unplanned application downtime per year are $1.25 billion to $2.5 billion.
Beyond extensive financial costs, broken SLOs lead to customer dissatisfaction, and customers might look elsewhere for similar services. A tarnished brand reputation might discourage prospects from trying your services, slow down your customer growth, and even hinder your talent recruiting.
Root cause-based automated problem remediation
What are the requirements for rapid problem remediation that prevents downtime? When looking at reports such as the DevOps Automation report 2021, it becomes clear that the most significant challenges during remediation are manual toil (lack of automation) as well as challenges related to communication, for example, reaching the right people, using the right runbooks, and ensuring that decisions are based on reliable data.
Dynatrace Davis AI detects problems, underlying root causes, business impact, and SLO impact across your full-stack production deployments. Dynatrace Cloud Automation uses this information to trigger and execute remediation actions and observability-based validations.
Based on data insights and customer research, we’ve identified the top five use cases for automated problem remediation:
- Feature flag settings—Observe application and service behaviors, identify error-causing feature flags, and switch them accordingly to guarantee stable environments.
- Process restarts (for example, JVM memory leaks)—Trigger a service restart or related actions for applications with underlying bug fixes that have been deprioritized or delayed.
- Kubernetes resource adoption—Act on external, holistic, and customer-centric behavior observations—rather than on only internal parameters—and automatically roll out Custom Resource Definitions (CRDs) to designated environments.
- Deployment and rollback—Trigger predefined rollback or roll-forward actions when a faulty deployment violates SLOs or decreases your error budget above the target.
- Targeted notifications—Based on the auto-detected details of underlying root causes, keep your business and technical users, SREs, and Operations team updated regarding ongoing remediation actions and escalate if the situation requires higher visibility.
Take out the guesswork
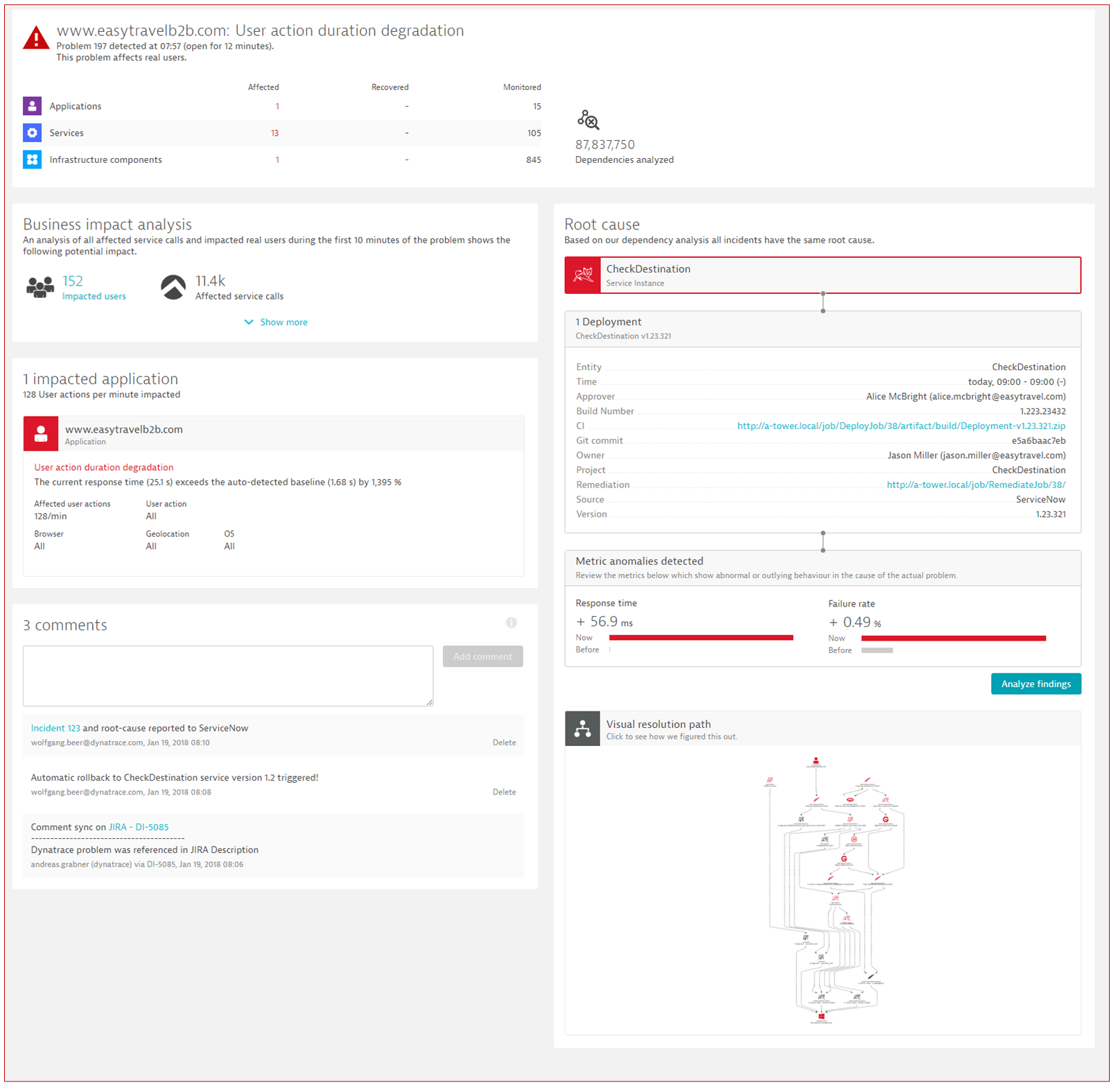
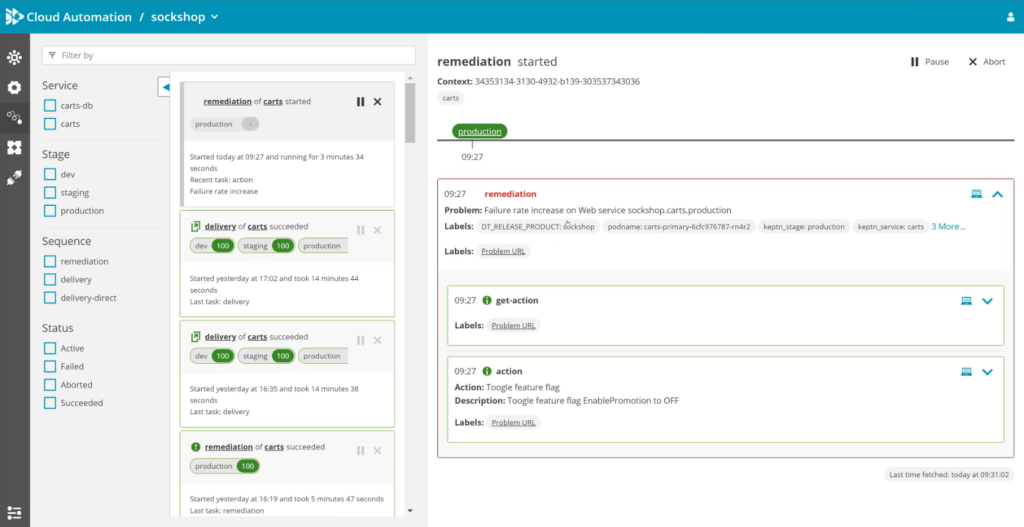
Let’s look at an example scenario where automated problem remediation is applied. Consider that Davis AI has detected that turning on a particular feature flag leads to a failure rate increase and raises a problem. While this information is used to alert Operations or SREs, Dynatrace now allows you to link root causes to freely configurable runbooks. In this scenario, the runbook can turn off the failure-rate-increasing feature flag while checking the system’s health to see if the remediation action fixed the problem. Once the problem is fixed, Dynatrace Davis AI closes the problem. Otherwise, the next escalation level of the runbook is executed, for example, sending a notification to a human operator.
What’s next
This blog post is the first in a series of publications centered around different problem remediation use cases and exemplary toolchain integrations. Check out further information in our SLO documentation.
Stay tuned for the next blog post in this series to learn how to extend problem remediation beyond the feature flag mechanism and level up your software delivery by integrating Cloud Automation into your existing DevOps toolchain. Then you can orchestrate the software development lifecycle and remediate issues automatically. Reach out to us today for a demo.



Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum