
Logs present yet another data silo as IT managers try to troubleshoot and remediate issues. To turn log data into meaningful insights, and to advance IT automation, organizations need a data lakehouse, combined with software intelligence.
For IT infrastructure managers and site reliability engineers, or SREs, logs provide a treasure trove of data. Logs assist operations, security, and development teams in ensuring the reliability and performance of application environments. But on their own, logs present just another data silo as IT professionals attempt to troubleshoot and remediate problems. Instead, organizations are increasingly turning to AIOps—or AI for IT operations—and data lakehouse models to get more real-time data insight.
Application and system logs are often collected in data silos using different tools, with no relationships between them, and then correlated in manual and often meaningless ways. These traditional approaches to log monitoring and log analytics thwart IT teams’ goal to address infrastructure performance problems, security threats, and user experience issues. Data silos persist, and data insights to troubleshoot problems and expand IT automation remain obscured.
How does a data lakehouse—the combination of a data warehouse and a data lake—together with software intelligence, bring data insights to life? And how can this combination unlock greater IT automation?
Data volume explosion in multicloud environments poses log issues
Achieving the ideal state with aggregated, centralized log data, metrics, traces, and other metadata is challenging—particularly for multicloud environments. This is because logs may be generated from thousands of applications, built by different teams, and spread across a complex global landscape of cloud and on-premises environments.
Further, these resources support countless Kubernetes clusters and Java-based architectures. They can call on dozens of databases and deliver gigabytes of data across myriad devices. Each process could generate multiple log entries, adding up to terabytes of data every day. As a result, organizational data volumes are becoming costly to store and unmanageable to analyze for relevant, timely data.
Indeed, according to one survey, organizations’ data volumes are growing by 63% a month.
Data variety is a critical issue in log management and log analytics
Logs are just one source of data that development and operations teams use to optimize application and infrastructure performance. Distributed traces are also critical to identifying the following:
- the path a request took;
- performance bottlenecks between services, and
- where an error occurred at the code level.
Lining up traces, logs, and metrics based on user events and timestamps provides the most complete picture of full-stack dependencies. Teams can also use logs to create custom metrics, providing a snapshot of data at a moment in time. Metrics are often tracked and measured relative to a baseline or threshold.
Given this fragmentation and inefficiency, the value of logs diminishes at the scale of modern, multicloud environments. Teams have multiple tools to manage and budget. And when it comes to troubleshooting, everyone leans on a different source of truth. Clearly, this works against the goal of digital transformation.
The advantage of an index-free system in log analytics and log management
Traditionally, teams struggle to centralize all these data silos through the process of indexing. Log indexing is an approach to log management in which logs are organized by keys based on attributes. In most data storage models, indexing engines enable faster access to query logs.
But indexing requires schema management and additional storage to be effective, which adds cost and overhead. With a modern log analytics approach, teams can access data in real-time and get precise answers without having to index it first. This can vastly reduce an organization’s storage costs and improve data efficiency.
Instead, an index-free system categorizes data in buckets and can then indicate to a query engine whether to include sought-after data in that bucket. A modern approach to log analytics stores data without indexing. Without indexes, IT pros can query data faster, so they gain data insights faster with improved access to that data.
Avoiding the speed-cost-quality tradeoffs by using a data lakehouse
A data lakehouse with an analytics engine combines the flexible storage of a data lake with data management and querying capabilities of a data warehouse.
This means a data lakehouse can store structured, semi-structured, and unstructured data with access to high-quality, real-time data and performance. Combining this data lakehouse with real-time observability data provides an efficient, low-cost, and high-performance data repository for AIOps and analytics.
Now, teams can move faster without needing to rehydrate and cobble together data from multiple systems searching for clues. A data lakehouse also ensures that teams have the most complete and up-to-date data available for data science, machine learning, and business analytics projects.
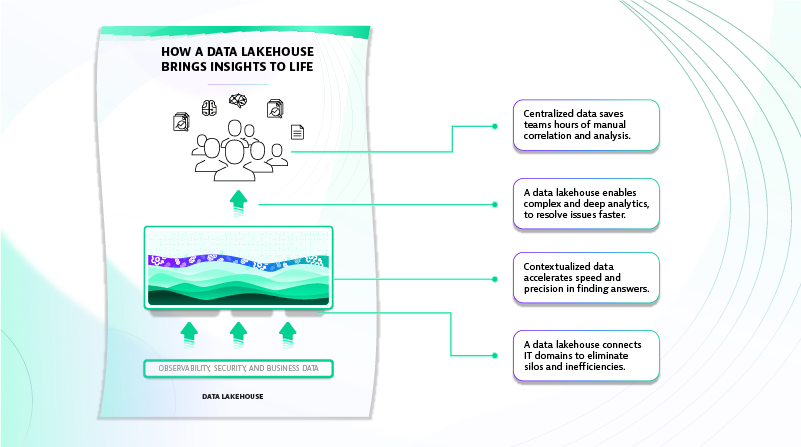
Providing data in context: A data lakehouse differentiator
But DevOps and SRE teams still require IT automation and software intelligence to place data in context. Turning raw information into meaningful insight requires context. With an AI-driven software intelligence layer overseeing a vast repository, teams can automatically contextualize and monitor data in real time and at a previously unimaginable scale.
AI software intelligence integrated with operations at the massive scale of a data lakehouse brings AIOps to a new level. “There is no future of IT operations that does not include AIOps,” wrote the authors of the Gartner report Market Guide for AIOps Platforms. “It is simply impossible for humans to make sense of thousands of events per second being generated by their IT systems.”
With AIOps, logs, metrics, traces, and other data types are no longer just another data silo. Now, they become a treasure trove of contextualized information. This data provides precise answers to the root cause of problems and helps IT teams act in real time.
With the Dynatrace platform and its deterministic AI, IT teams have the ammunition they need to make informed decisions in real time about application errors, system downtime, and malicious threats. Teams have access to the data they need without having to wait a week to gain access to that data.
Ultimately, this kind of infrastructure can eliminate the tradeoff between cost, speed, and visibility.
With modern, indexless log analytics, IT teams can maximize the value of log data. No-index logs make it easier and cost-effective to ingest, retain, contextualize, and analyze log information. Indexless log analytics gives teams a single source of truth and enables them to resolve issues faster. This goldmine of data ultimately provides IT with the answers they need in real time to get ahead of problems before they affect the business.
How a data lakehouse brings business ROI
Beyond the technical benefits, a data lakehouse brings benefits to the whole business.
- Eliminates team silos. With data centralized and paired with context through AI, teams can collaborate more efficiently rather than work in silos. Without a common repository, IT teams use siloed logging tools and struggle to determine root cause.
- Faster, better-quality insights. A data lakehouse enables IT teams to gain real-time access to accurate data without having to rehydrate it. Moreover, combining this proximal data store with contextualized analysis enables IT teams to precisely identify system issues in applications and infrastructure in real time. As a result, teams can proactively identify issues before they create system downtime, user problems, or security concerns.
- Cost-effective architecture. A data lakehouse combines the cost efficiency of a data lake with the analytics capabilities of a data warehouse. This combination provides the best cost-to-value benefit to your organization.
The value of event logs is maximized when they are automatically contextualized with other observability data, then analyzed in real-time using causation-based AI, and stored in the most cost-effective cloud storage available.
For more information on how Dynatrace can provide your organization with intelligent log management and analytics, visit our website.
The Dynatrace difference, powered by Grail
Dynatrace offers a unified software intelligence platform that supports your mission to accelerate cloud transformation, eliminate inefficient silos, and streamline processes. By managing observability data in Grail—the Dynatrace data lakehouse with massively parallel processing—Dynatrace automatically stores all your data with causational context, requiring no rehydration, indexes, or schemas.
Dynatrace analyzes each log, metric, business event, user session, trace, and dependency automatically and in real time, from devices to your back-end infrastructure. With unparalleled precision, Dynatrace cuts through the noise and empowers you to focus on what is most critical. Through the platform’s automation and AI, Dynatrace helps organizations tame cloud complexity, create operational efficiencies, and deliver better business outcomes.




Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum