
Dynatrace automatically detects process types such as Tomcat, JBoss, Apache HTTP Server, MongoDB, and many others out-of-the-box. Technologies in your environment such as Docker, Kubernetes, OpenShift, Cloud Foundry, and Azure are also detected and monitored automatically. Dynatrace also automatically groups processes that belong together.
Not only does Dynatrace automatically detect process groups, it also attempts to name them with intuitive names that make sense to the DevOps staff who are tasked with deploying and monitoring them. While process-group detection has worked well in most cases, it hasn’t been perfect. To accommodate more complex and non-standard deployments, we added features around process group detection and now process group naming.
Process group detection vs process group naming
Each process group is a logical cluster of processes running on separate hosts that belong to the same application or deployment unit. Process group detection rules enable you to customize how processes are grouped into clusters and therefore which components are part of each group. For example, it enables you to define which Apache HTTP processes are part of the same web cluster and which belong to other clusters.
In many cases, however, the process grouping itself works fine, but the auto-generated names created by Dynatrace are either too generic or they don’t reflect your naming standards. To change the naming schemes of detected process groups, you need process-group naming rules.
Introducing process group naming rules
Dynatrace has long provided the ability to define naming rules and schemes for services. This feature has been well received. With this in mind, we’re proud to announce that naming rules are now also available for process groups.
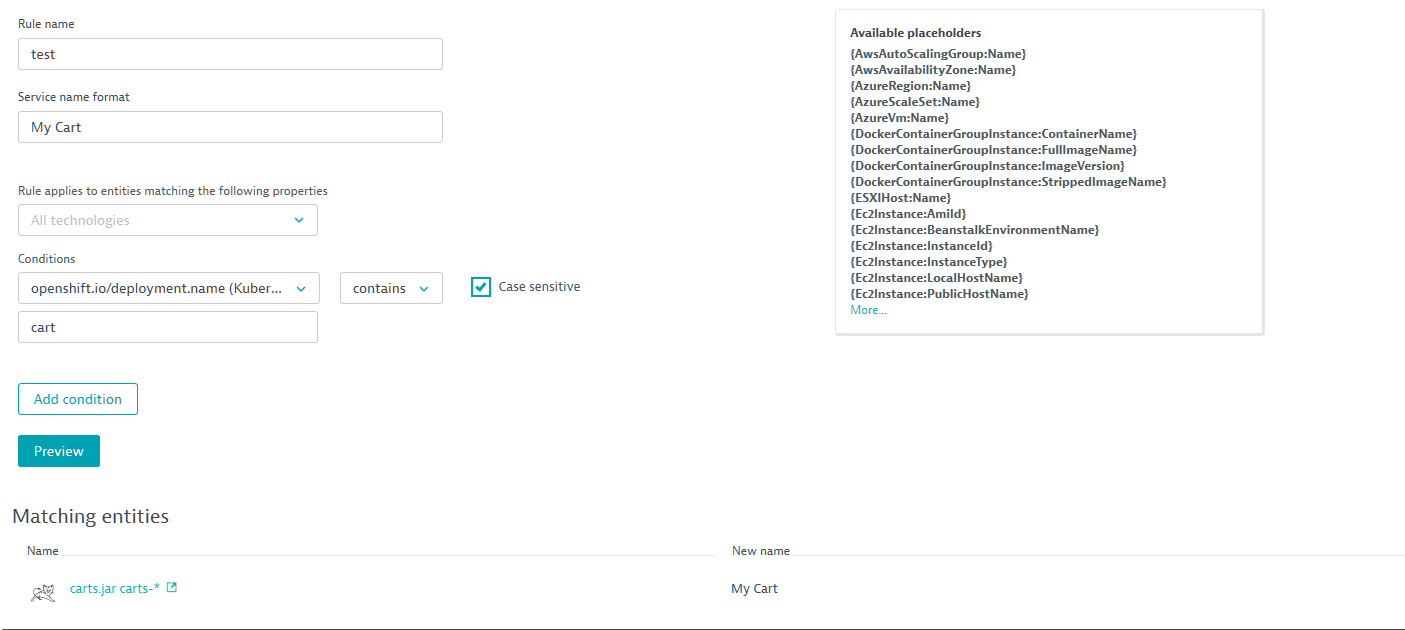
To add a new process-group naming rule
- Go to Settings > Process groups > Process group naming.
- Click the Add new rule button.
- Type in a Rule name.
- Define the Process group name format including any static text string that describes the named process group. Optional placeholders are available to make it easy to dynamically include specific process-group properties in your automated process-group naming scheme.
- Add one or more Conditions to the rule to match the process groups that you want to apply the naming scheme to.
Conditions check for the existence of many different types of specific attribute and state values, from the check of a Docker image to a check of the CloudFoundry space that a process group runs in.
The example condition below applies only to Java processes that are started via a JAR file that begins withcom.dynatrace.easytravel. Looking at the Process group name format below, you can see that it actually takes the JAR file and applies a regular expression to it.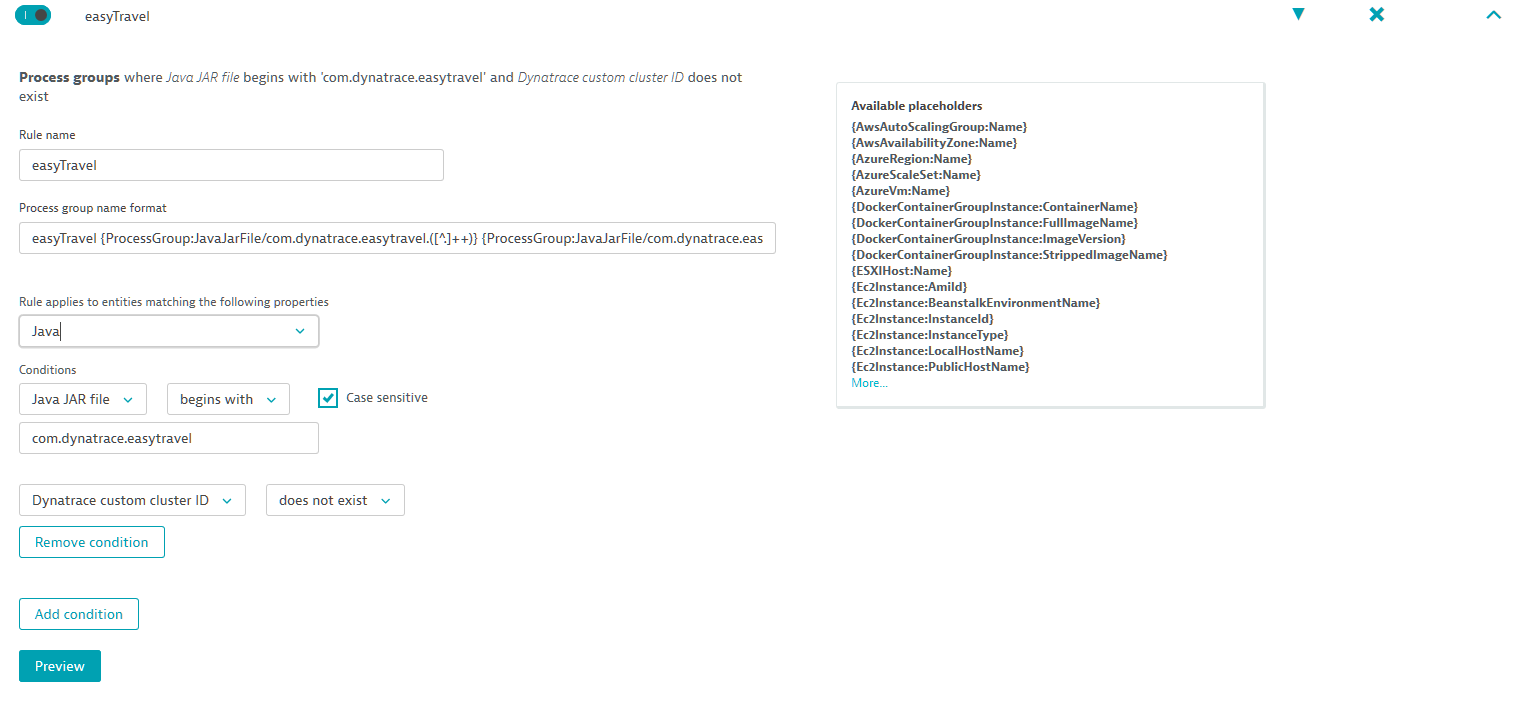
- Use the Preview button to verify that the list of returned entities matching your new rule includes only the entities you want.
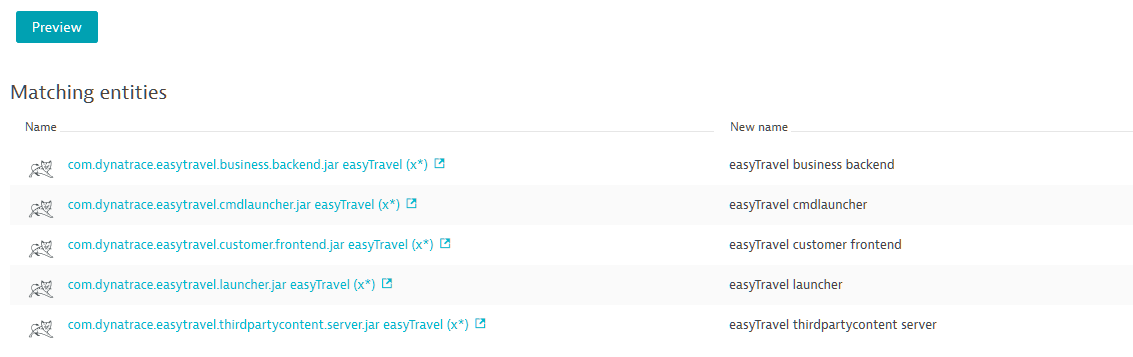
In contrast to process-group detection, process-group naming rules don’t require a restart of your processes and they don’t affect how processes are identified and grouped. These rules simply provide a fast and easy means of applying intuitive naming conventions to your processes.
Use custom metadata to enrich naming rules
You can further enrich Dynatrace process monitoring by incorporating your own metadata into rule conditions. You can then use your custom metadata to better refine your process-group naming rules. See highlighted example below.
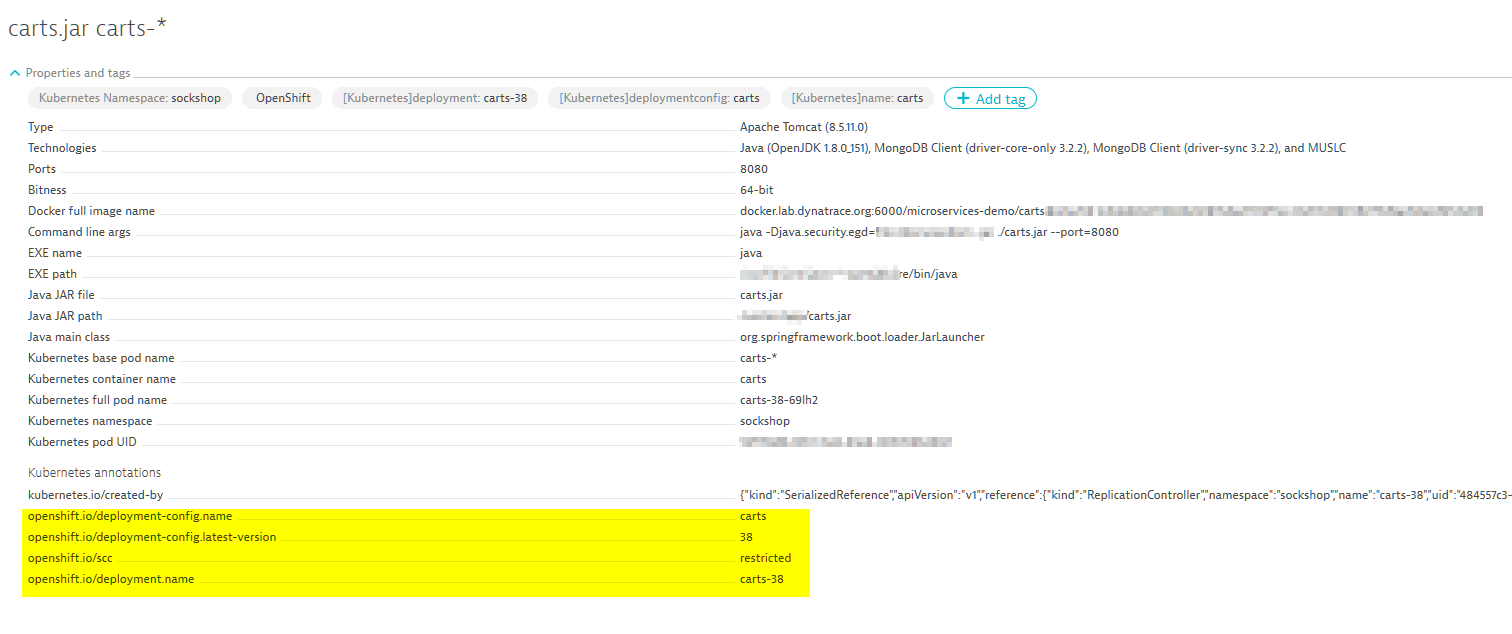
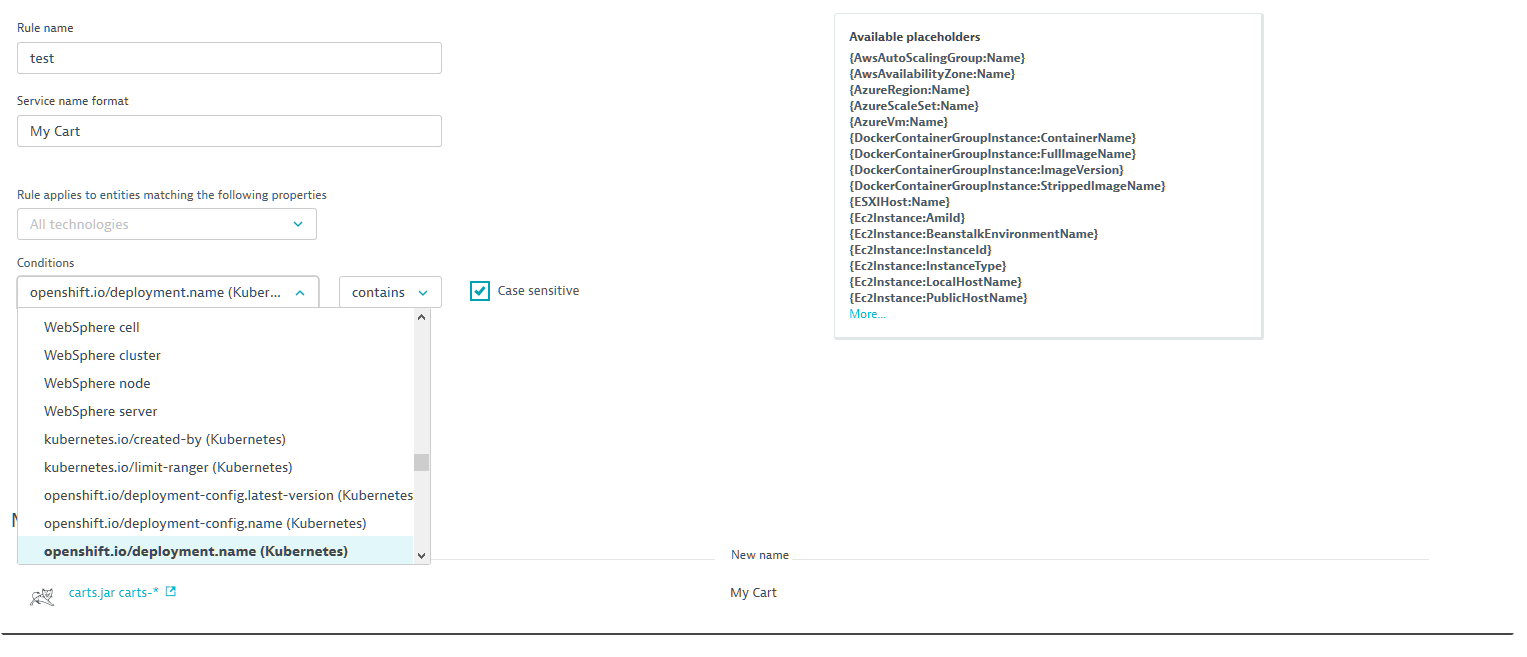
With custom metadata incorporated into your process-group naming rules, you can enforce your own granular naming standards system-wide.




Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum