
In part one, we began our discussion about intellectual debt by pointing out how machine learning systems contribute to the widening gap between what works and our understanding of why it works. Part two added a few simple examples of how intellectual debt might accrue, highlighting the subtle but real drag on efficiency. We concluded by suggesting that the fuzziness of machine learning systems presents a fundamental problem for autonomous IT operations. Since we began the series pointing out parallels to technical debt, let’s revisit that comparison.
The reasons we inadvertently accrue intellectual debt are similar to those that contribute to technical debt. We make sub-optimal or under-informed choices under pressure. In choosing a monitoring solution, these factors might include an established relationship with an incumbent vendor; product bias based on the team’s past experiences; or budget constraints, especially with an overly tactical short-term perspective of ROI. Compounding these tendencies is the messaging confusion that permeates the emerging AIOps market as new and established vendors make claims that are often difficult to parse.
Machine learning vs. Dynatrace AI
One of the fundamental differences between machine learning systems and the artificial intelligence (AI) at the core of the Dynatrace Software Intelligence Platform is the method of analysis. While just one of many, this particular distinction speaks directly to the threat of intellectual debt.
Machine learning systems
- Examine large data sets, applying statistical correlation to uncover patterns in observable behaviors, including metrics, events, logs, and alerts.
- Suggest multiple answers to problems based on the strength of these correlations.
- Require training—learning periods—to uncover structure and commonalities and identify normal behavior.
- Work best on large homogeneous data sets that are relatively static; the more dynamic the environment, the further behind the learning algorithms may lag.
- Don’t understand cause and effect, requiring humans to interpret and determine root cause.
Dynatrace AI—Davis
- Uses a deterministic step-by-step fault-tree analysis, analyzing dependencies to determine true cause and effect.
- Davis® can precisely identify the root cause of a problem.
- Works without training; the entire system context is captured and updated in real-time, as hosts and processes appear.
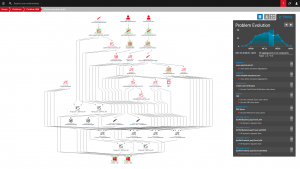
- Davis explains its results; presenting a problem evolution timeline and fault-tree analysis chart for each identified problem.
- You can even replay the chain of events to view a problem’s evolution, visualizing the fault-tree logic as it pinpoints the root cause, with the Problem Evolution player.
Through these clear explanations, each supported by contextual drilldowns, you can see how Davis makes it easy to avoid intellectual debt while offering a clear path towards autonomous IT operations.
Towards a debt-free autonomous future
Just as with technical debt, avoiding intellectual debt starts with making informed decisions with a clear understanding of where you’re headed. For virtually every digital enterprise, this means automation—to innovate faster and deliver better business outcomes.
Tomorrow’s hybrid multi-cloud environments are hyper-dynamic with highly distributed application environments, rapidly escalating the challenges to human-centric operations teams.
To remain competitive, companies must prepare to move from a traditional delivery and operational model towards NoOps and a fully autonomous cloud approach—on the path to a self-driving enterprise. While machine learning systems can improve on today’s IT efficiency, their inherent imprecision and inability to expose cause and effect contribute to intellectual debt and will eventually limit prospects for automation.
Further reading
Part 1: Intellectual debt: The hidden costs of machine learning




Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum