
AWS Lambda is enormously popular amongst our customers and while it was once perceived as just a new toy for startups who wanted to be at the cutting edge of technology, we’ve seen that many enterprise customers are now adding Lambda functions to their stacks. This is because AWS Lambda provides a relatively low barrier for entry into cloud computing without the need to pursue a whole lift-and-shift operation right away.
Nonetheless, operating Lambda functions comes with its own unique challenges and—especially when used within enterprise stacks—the operational requirements are the same as for any other piece of software.
In a previous blog post, we covered how Lambda functions work under the hood. Let’s now turn the focus towards typical use cases for Lambda functions, challenges related to operating Lambda functions, and how Dynatrace provides enterprise-grade intelligent observability for Lambda functions.
A quick primer on Lambda functions
In short, Lambda functions can take on almost all of the operational duties of running an application; all you need to do is provide the code that should be executed on a given event or trigger.
This means that there is no need to provision or manage servers (or even containers). Lambda handles all of the following for you:
- Load balancing
- Auto scaling
- Failure retries
- Security isolation
- OS management
- Utilization and capacity
On top of this, Lambda functions are billed strictly on a consumption basis. This means that there are zero costs incurred while a Lambda function isn’t running.
So, a well-architected Lambda architecture can save a lot of costs. Also, having AWS manage the utilization of your compute resources and reduce idle times is also good for the planet.
Wherever there is light, there is also shadow, and while there is really almost no operational overhead when running a function, there are new challenges that need to be tackled when moving to AWS Lambda.
Local development is harder
A Lambda function runs inside the AWS Lambda runtime and is deeply integrated into the AWS stack. As such, providing the same environment during local development can be complicated. Also, “serverless” means more than just Lambda functions. When using Lambda, you might soon end up using more serverless offerings, like databases, which makes emulating the same environment locally even harder.
If you haven’t done so already, providing a testing environment for developers to easily test their functions with AWS solves most of these challenges and makes the required tooling similar to what’s required for operating microservices.
Deployment and orchestration are harder
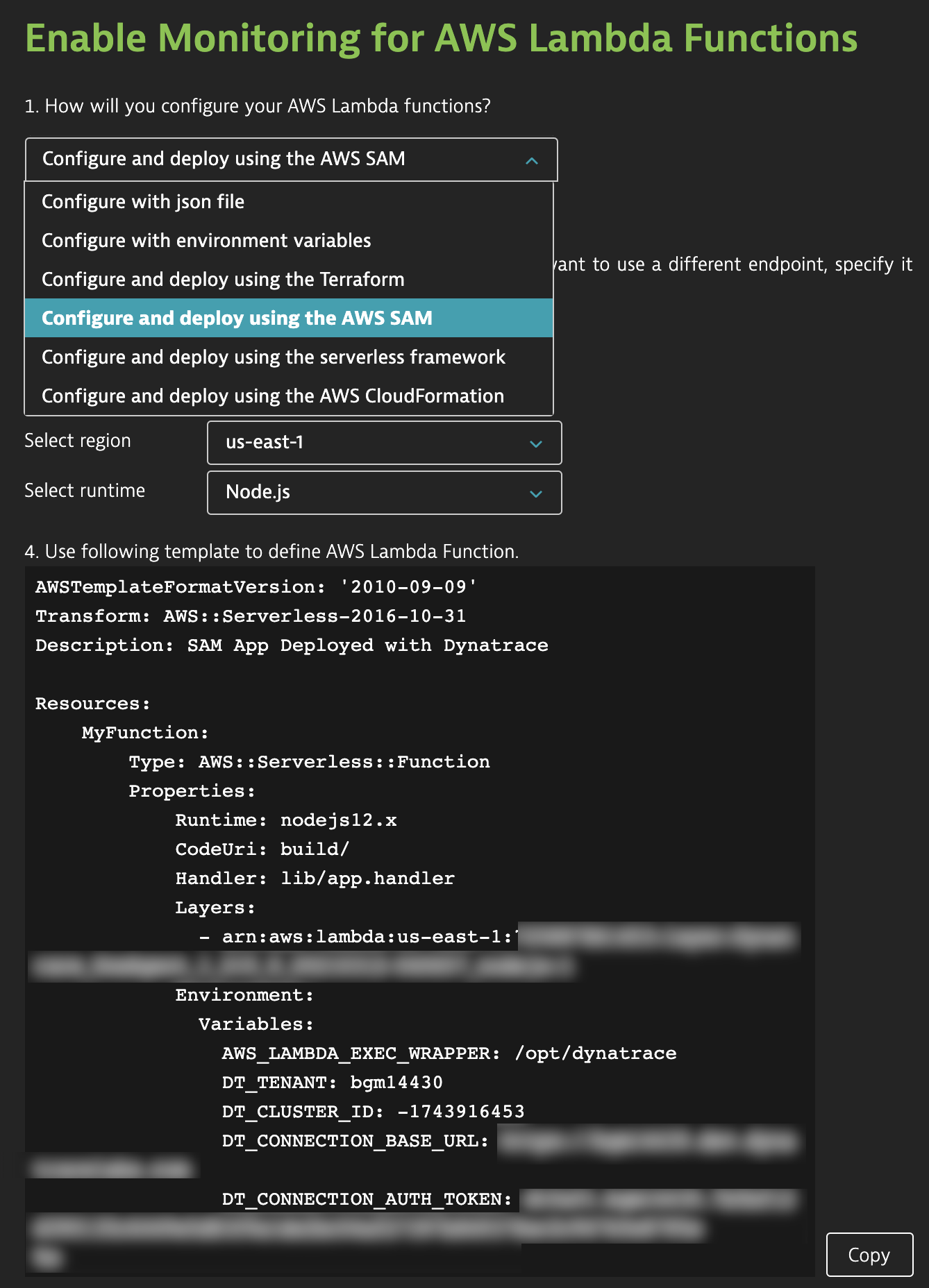
While AWS takes the operational overhead for operating Lambda functions off your shoulders, using Lambda functions at a larger scale requires mature deployment strategies. If you haven’t yet considered using Infrastructure as Code (IaC), this is the right time to consider it so that you avoid ending up with a forest of manually deployed function instances. As for the development stage, Continuous Integration and Continuous Deployment is what you should be looking at. In consideration of this reality, The Dynatrace Lambda monitoring extension supports all well-known IaC technologies to deploy Dynatrace along with your function.
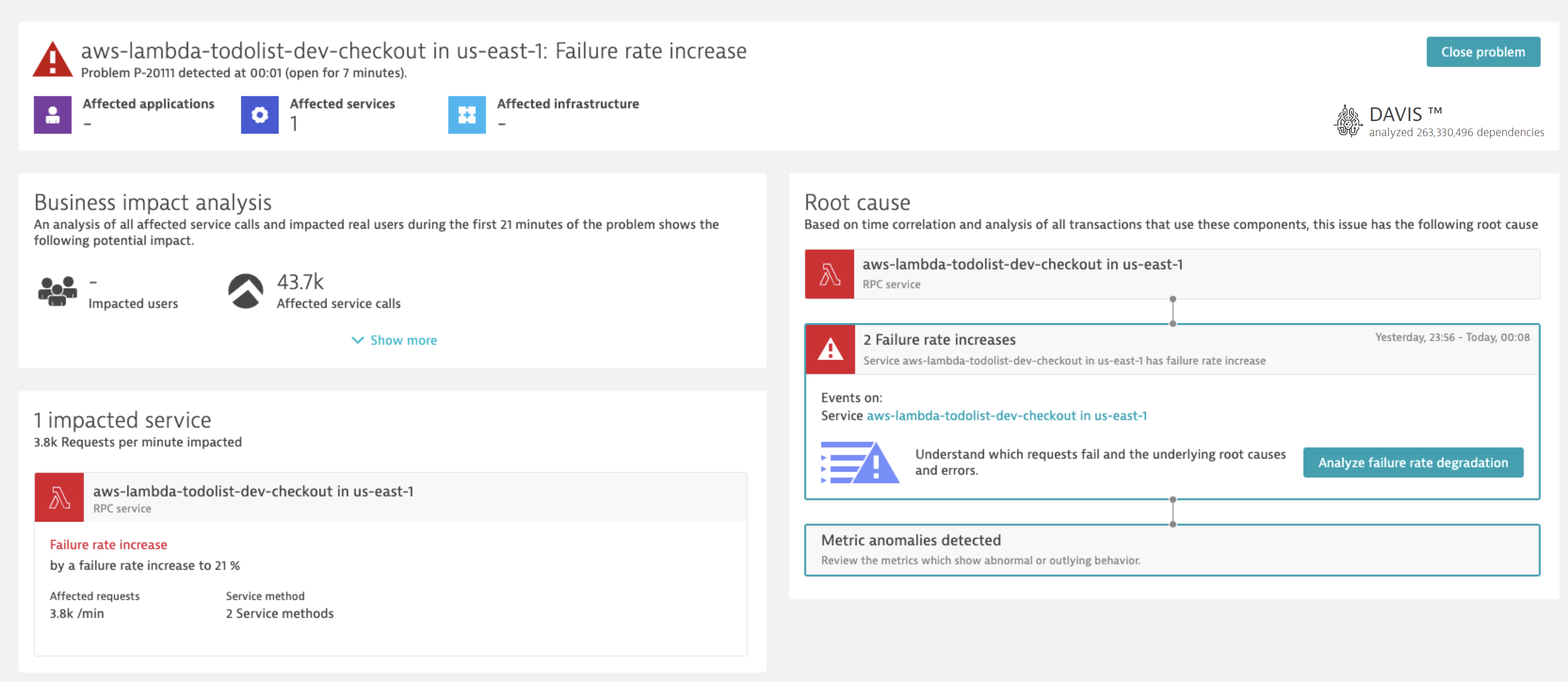
Enterprise-grade observability is harder to achieve
Soon after developers started to adopt AWS Lambda, operations and SREs began looking for ways to get the same level of insights they’ve grown to expect from traditional workloads. Soon niche products that only focus on monitoring Lambda deployments emerged, but they didn’t satisfy the usual enterprise requirements of end-to-end observability between on-premise deployments and hybrid clouds.
While these niche products were mostly building upon AWS CloudWatch and Xray, their agents were rather limited as running an agent in process with a Lambda function comes with some challenges. (See our previous blog post for more information on that.)
With the release of the Dynatrace Lambda extension, this is a thing of the past. Today, Lambda can be monitored by Dynatrace in hybrid environments, thereby satisfying the enterprise requirements.
Top enterprise use-cases for AWS Lambda
While working with our customers, we were able to isolate a set of the most common Lambda use-cases. These served as our benchmark when creating our Lambda monitoring extension.
Extending existing enterprise stacks
For many enterprises, Lambda functions provide an easy way to tap into cloud computing without starting a whole cloud migration initiative. Frequently used services that are on the edge are good candidates for Lambda. With our customers, we see capabilities like authentication or computational tasks being moved to Lambda. Often, Lambda functions just serve as a gateway to other AWS managed services, which leads us to our next use case.

Gateway/proxy tier to other AWS services
AWS offers a whole range of managed services that also fall into the “serverless” bucket. Using these services from within Lambda functions is easy. All that’s needed is to use the AWS SDK for a given service and provide the ARN of the endpoint. This puts all AWS services at the fingertips of developers, enabling them to build complex applications without deploying a single host or container.
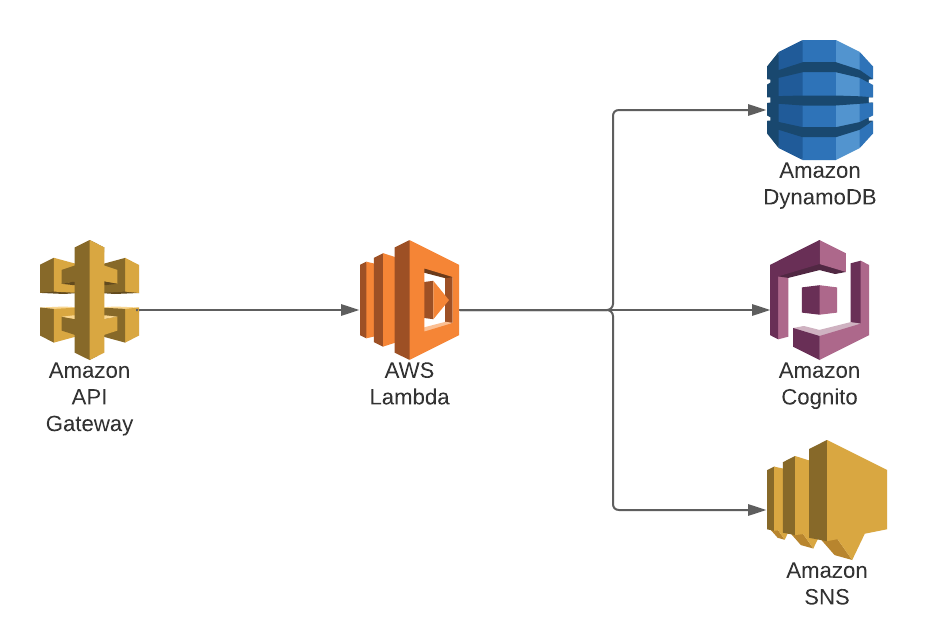

This is where monitoring requirements come into play. If your application relies on Lambda functions and downstream services, end-to-end observability is imperative (in contrast to working with a black box or monitoring functions using a point solution).
As mentioned, Dynatrace ensures the same level of end-to-end visibility regardless if your application is served by a dedicated host, a container in Kubernetes, or a Lambda function.
Backend for single-page applications
It may come as a surprise, but a frequent use case for Lambda amongst our customers is providing a backend for single-page applications (SPAs).
In contrast to a regular web page, where most user interactions lead to a complete reload and server-side rendering of the page, SPAs change their content dynamically using JavaScript. Today, frontend frameworks like Angular, React.js, and Vue.js are used to accomplish this task. To provide dynamic content, SPAs mostly rely on REST APIs to fetch their data using a means provided by modern browsers, such as XHR or fetch.
A Lambda function behind an API gateway can provide exactly such an API endpoint to fetch data from other AWS services, or even to call back into the enterprise application to fetch data from, for example, a mainframe.

Yet, the HTML and JavaScript of a SPA must still be hosted somewhere. Amazon S3 and CloudFront provide a perfect solution for hosting and serving such static assets. AWS Lambda as well as S3 are mostly billed based on consumption. This means that, compared to running a regular web server, there are virtually no costs while users are not interacting with your site.
In single-page applications, monitoring user actions and calls to the backend are the only means of finding out about problems before your end users begin to complain.

This is why Dynatrace Real User Monitoring (RUM) is fully integrated into our AWS Lambda monitoring extension. By adding a JavaScript snippet to your static page and setting a configuration option on the Lambda functions, Dynatrace provides the full capabilities of Real User Monitoring and also provides end-to-end traces for calls from the browser to the backend powered by AWS Lambda.
What’s next
The Dynatrace AWS Lambda extension, with all its advanced capabilities, is just a first step—we have lots of great functionality in the pipeline including:
- Ingestion of AWS Lambda logs
- Support for additional languages
- Support for container images deployed on AWS Lambda
So, stay tuned for more blog posts and announcements.
Are you new to Dynatrace?
If so, start your free trial today!


Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum