
The growing number of data sources that, for example, sense the external world, capture business events, or collect observability data continuously increases the amount of generated data. Considering such a high data volume, continuously processing data streams and producing near real-time results is a recurring challenge.
The jobs executing such workloads are usually required to operate indefinitely on unbounded streams of continuous data and exhibit heterogeneous modes of failure as they run over long periods.

Stream processing
One approach to such a challenging scenario is stream processing, a computing paradigm and software architectural style for data-intensive software systems that emerged to cope with requirements for near real-time processing of massive amounts of data.
Stream processing enables software engineers to model their applications’ business logic as high-level representations in a directed acyclic graph without explicitly defining a physical execution plan. This high level of abstraction is provided by industry-grade, open source stream processing frameworks such as Kafka Streams, Apache Flink and Spark Structured Streaming. Such frameworks support software engineers in building highly scalable and efficient applications that process continuous data streams of massive volume. They provide high-level APIs and domain-specific languages to define processing logic as directed acyclic processing graphs that filter, transform, aggregate, and merge data streams.
Performance is usually a primary concern when using stream processing frameworks. See more about the performance of stream processing frameworks in our published paper. ShuffleBench is a benchmarking tool for evaluating the performance of modern stream processing frameworks. ShuffleBench focuses on use cases where stream processing frameworks are mainly employed for shuffling (in other words, re-distributing) data records to perform state-local aggregations, while the actual aggregation logic is considered a black-box software component.
Fault tolerance stands as a critical requirement for continuously operating production systems. Failures can occur unpredictably across various levels, from physical infrastructure to software layers. Stream processing systems, designed for continuous, low-latency processing, demand swift recovery mechanisms to tolerate and mitigate failures effectively. On the one hand, fault tolerance guarantees such as At Least-Once Semantics (ALOS) or Exactly-Once Semantics (EOS) are already provided by modern stream processing frameworks. On the other hand, fault recovery’s impact on the quality of services is not sufficiently measured, which is one of our research interests.
We designed experimental scenarios inspired by chaos engineering. Failures are injected using Chaos Meshan open source chaos engineering platform integrated with Kubernetes deployment.
Chaos scenario: Random pods executing worker instances are deleted.
Main findings
A relevant observation from our findings is that Kafka Streams shows volatile behavior in recovering from failures and takes longer to recover than other frameworks. For instance, the figure below shows a scenario where, periodically, two random pods execute worker instances—entities executing the stream processing applications—are killed. After failures, Kafka Streams’ partition assignment strategy, triggered by rebalances, causes its executions to accumulate more lag. This significantly increases event latency. Additionally, following failures, some worker instances can be assigned to more partitions or partitions with accumulated records. In which case some workers become overloaded while others are underutilized.
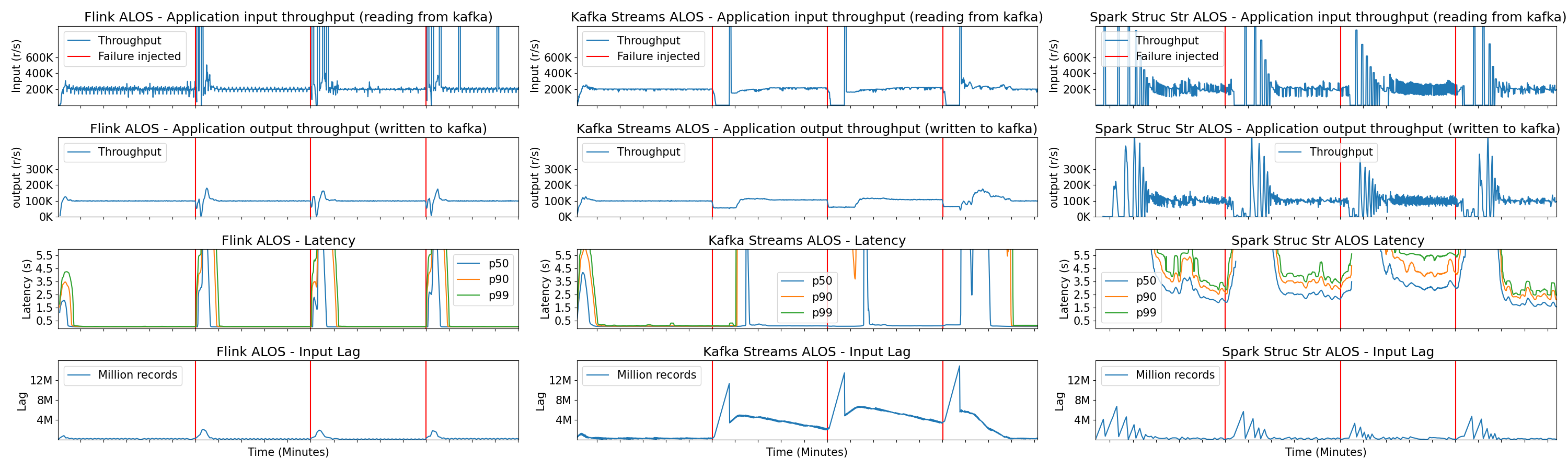
In our recent paper, we provide comprehensive measurements. The following are key insights from our extensive experimental analysis:
- Flink, Kafka Streams, and Spark Structured Streaming are resilient to different types and degrees of failure. However, the frameworks impact running applications differently.
- In use cases where ALOS guarantees are required, Flink currently provides the best recovery, which is fast and stable. Spark Structured Streaming can also provide consistent fault recovery for applications where latency is not a critical requirement. Kafka Streams takes longer to recover from failures and presents volatile behavior.
- Flink is the best candidate when EOS guarantees are necessary. On the other hand, Kafka Streams has limited performance, and Spark Structured Streaming has limited native support for EOS.
Optimized fault recovery
We’re also interested in exploring the potential of tuning configurations to improve recovery speed and performance after failures and avoid the demand for additional computing resources. In Kafka Streams, a large configuration space is available for potential optimizations.
From the Kafka Streams community, one of the configurations mostly tuned in production is adding standby replicas. The aim is to establish a predetermined number of replicas per store and maintain their synchronization contingent upon sufficient operational worker instances. In task recovery within worker instances, priority is assigned to those equipped with standby replicas tailored to the specific task.
In practice, standby replicas demand far more resources. Therefore, we are more interested in other configurations that can improve fault recovery without demanding more resources. While investigating the causes of the performance overhead in Kafka Streams’ rebalance protocol, we noticed that one of the main reasons is that the convergence is too slow after failures. The failure of worker instances triggers a rebalance, where the partitions affected by failure are usually unevenly redistributed to the remaining instances. After a redistribution, follow-up rebalances are needed to achieve an even partition distribution to improve the load balance. The number of rebalances necessary to achieve even partition distributions can vary significantly. However, the first Kafka Streams’ rebalance is only triggered 10 minutes after failure with the default configurations.
In our exploratory research and interactions with the community experts, we noted that this default period can be changed with the probing.rebalance.interval.ms configuration, which represents the maximum waiting period before initiating a rebalance, aimed at verifying the readiness of warm-up replicas so they can be deemed sufficiently up-to-date for task reassignment. When a given task needs to be moved to another worker instance, a warm-up replica is placed in the destination worker instance before it receives a task reassignment. Hence, the worker instance can warm up the state in the background without interrupting the active processing, having a smooth transition.
We evaluate a shorter rebalance interval set to a minimum of 1 minute, and we allow more warm-up replicas up to a value equal to the parallelism level of 8 used in our experiments. These configurations can theoretically speed up the fault recovery by being faster (shorter rebalance interval) and offering more robust rebalances (more warm-up replicas enable more tasks to be migrated per rebalance), which can enable an optimal number of partition distributions to the worker instances available. An optimal distribution can provide a true fault recovery with load balance and improve the application performance.
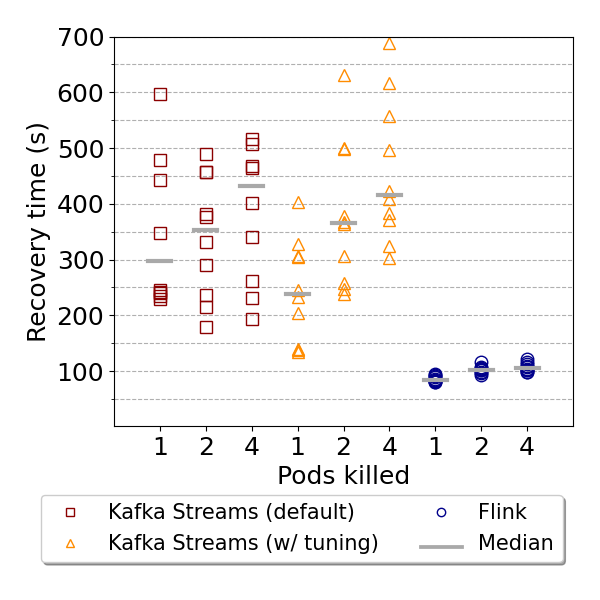
The figure below summarizes the results of the fault recovery times with output throughput and latency p90 as the default metrics of Kafka Streams, the optimized deployment, and Apache Flink. Regarding the throughput recovery depicted below, it is notable that Flink’s executions still achieve the fastest recovery in terms of throughput. Moreover, Kafka Streams’ executions with optimizations provide slight improvements in recovering the application’s output throughput, which is relevant to reducing downtimes.
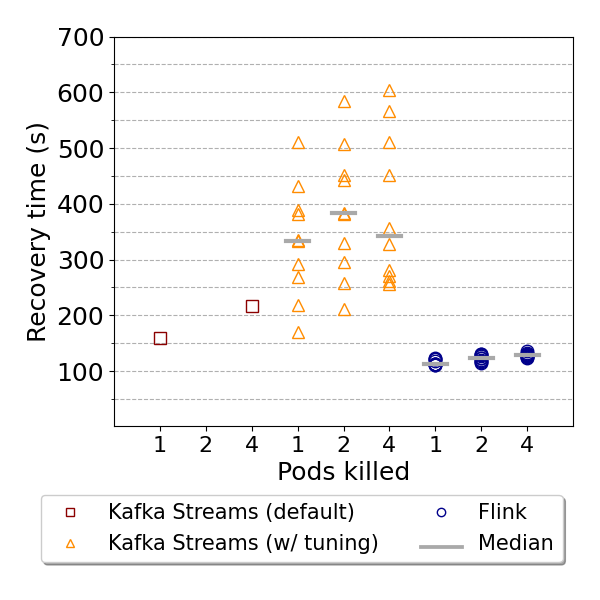
The latency recovery is depicted below, where Flink again achieved the fastest recovery. In contrast, Kafka Streams’ default executions only fully recovered in the 12 minutes (before the next subsequent failure was injected) in two cases out of 30 failures injected. This outcome is mostly due to the slow rebalancing after failures causing limited latency recovery. The figure below shows that Kafka Streams’ executions with tuning recovered from failures, achieving median recovery times between 300 and 400 seconds. Finally, the latency recovery achieved on the execution with tuning demonstrates Kafka Streams’ potential for configuration tuning.
Summary
Ensuring fault tolerance in data-intensive, event-driven applications is crucial for successful industry deployments. Applying Chaos engineering matters because we can (1) compare frameworks and find suitable approaches for our use cases, (2) create robust measurements that mimic advanced deployments that can capture unexpected issues before they happen in production, and (3) analyze potential optimizations and solutions to overcome issues.
The performance gains achieved with the Kafka Streams tuning approach are paramount. This is mostly because fault recovery capabilities impact the quality of service and are a criterion for choosing stream processing frameworks. However, achieving such gains is conditioned by significant complexities in understanding which configurations should be tuned and with what values, which can burden developers.
Therefore, we believe new abstractions for transparent configuration tuning are also needed for large-scale industry setups. We believe that more software engineering efforts are needed to provide insights into potential abstractions and how to achieve them. Another potential alternative is prompting large language models to tune configurations automatically. However, we noticed that GPT 3.5 and industry-grade copilots, such as Microsoft Copilot, can still not identify the relevant configurations to be tuned in Kafka Streams. We believe that further research and novel approaches to enhance the generalizability of configuration tuning and provide abstractions for developers are needed.
What’s next
Learn more about the existing frameworks: Kafka Streams, Apache Flink, and Spark Structured Streaming.
See more about the performance of stream processing frameworks in our published paper and the open source benchmarking framework.
See more fault recovery experiments and insights in our full paper.




Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum