
| >> Scroll down to see predictive capacity management in action (14-second video) |
Our recent blog post, Stay ahead of the game: Forecast IT capacity with Dynatrace Grail and Davis AI, showed how Dynatrace Notebooks are used to predict the future behavior of time series data stored in Grail™. This follow-up post introduces Davis® AI for Workflows, showing you how to fully automate prediction and remediation of your future capacity demands. The anticipation of future capacity demands makes it possible to completely avoid critical outages by notifying you days in advance, well before incidents arise.
Predictive capacity management starts within a Dynatrace Notebook, where the operations team explores important capacity indicators, such as the percentage of free disks, as shown below.
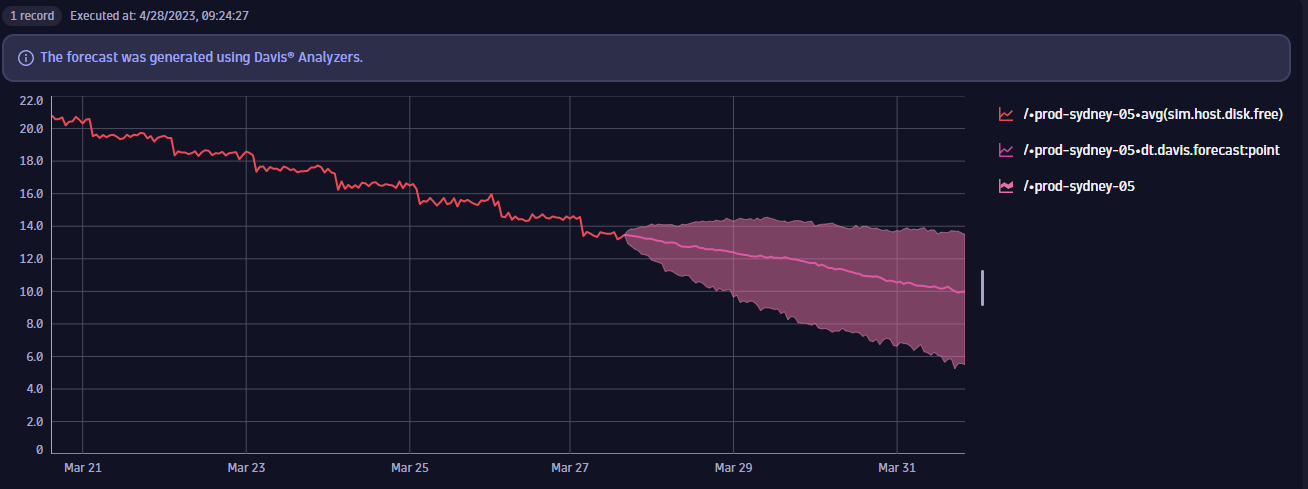
After exploring and selecting the most important capacity indicators for your environment, a workflow triggers forecast reporting at regular intervals. The example workflow below is triggered every Monday at 8:00 AM to provide a capacity report for all the disks that will likely run out of space within the next week.
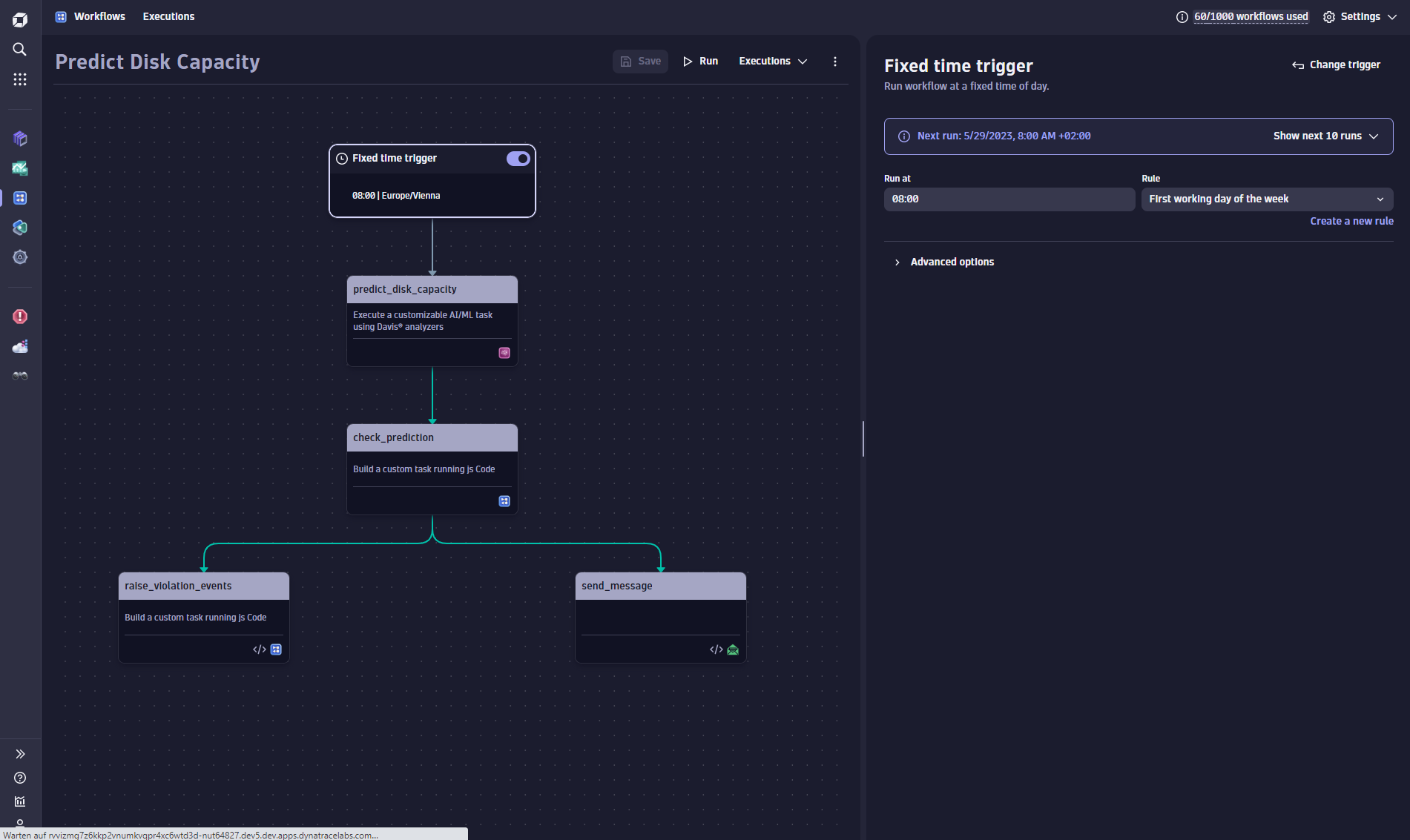
Define the forecast
The workflow uses the Davis for Workflows action to automatically trigger a forecast for a selected set of disks. The forecast operation is selected within the Davis action, and a DQL query is used to specify the set of disks and the capacity indicator metric that should be predicted. Note that you can use any time series data you can fetch from Grail using DQL within the forecast action.
While this example uses the metric dt.host.disk.free, you can choose any kind of capacity metric, such as host CPU, memory, or network load—you can even extract a metric value from a given log line.
The forecast is trained on a relative timeframe (for example, the last seven days) which is specified in the configured DQL query. The DQL query example below trains forecasting on a relative timeframe of the last seven days:
timeseries avg(dt.host.disk.free), by:{dt.entity.host, dt.entity.disk}, bins: 120, from:now()-7d, to:now()
The configuration below shows that a forecast horizon of 100 data points is requested, which means that 100 additional predicted points will expand the initially fetched 120 data bins of the source DQL query. This predicts one week into the future.
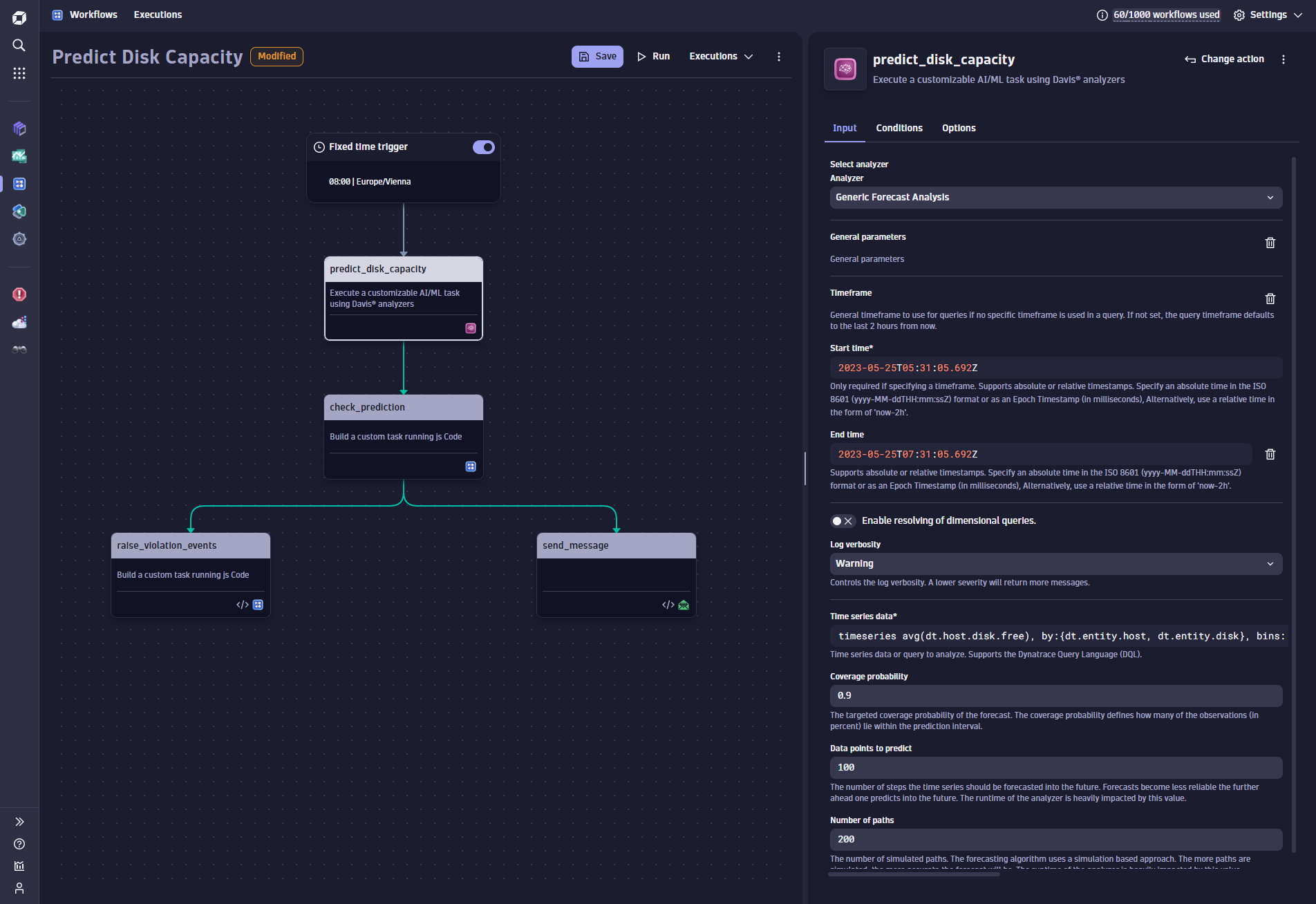
The prediction action returns all its forecasted time series lines, which can include hundreds or even thousands of individual disk predictions.
Evaluate the forecast results
Within the following TypeScript action, each disk prediction is tested against a threshold to determine if the disk will run out of space in the next week. The TypeScript code snippet below is responsible for checking for threshold violations and for preparing all the violations in a result object for subsequent actions to follow up on:
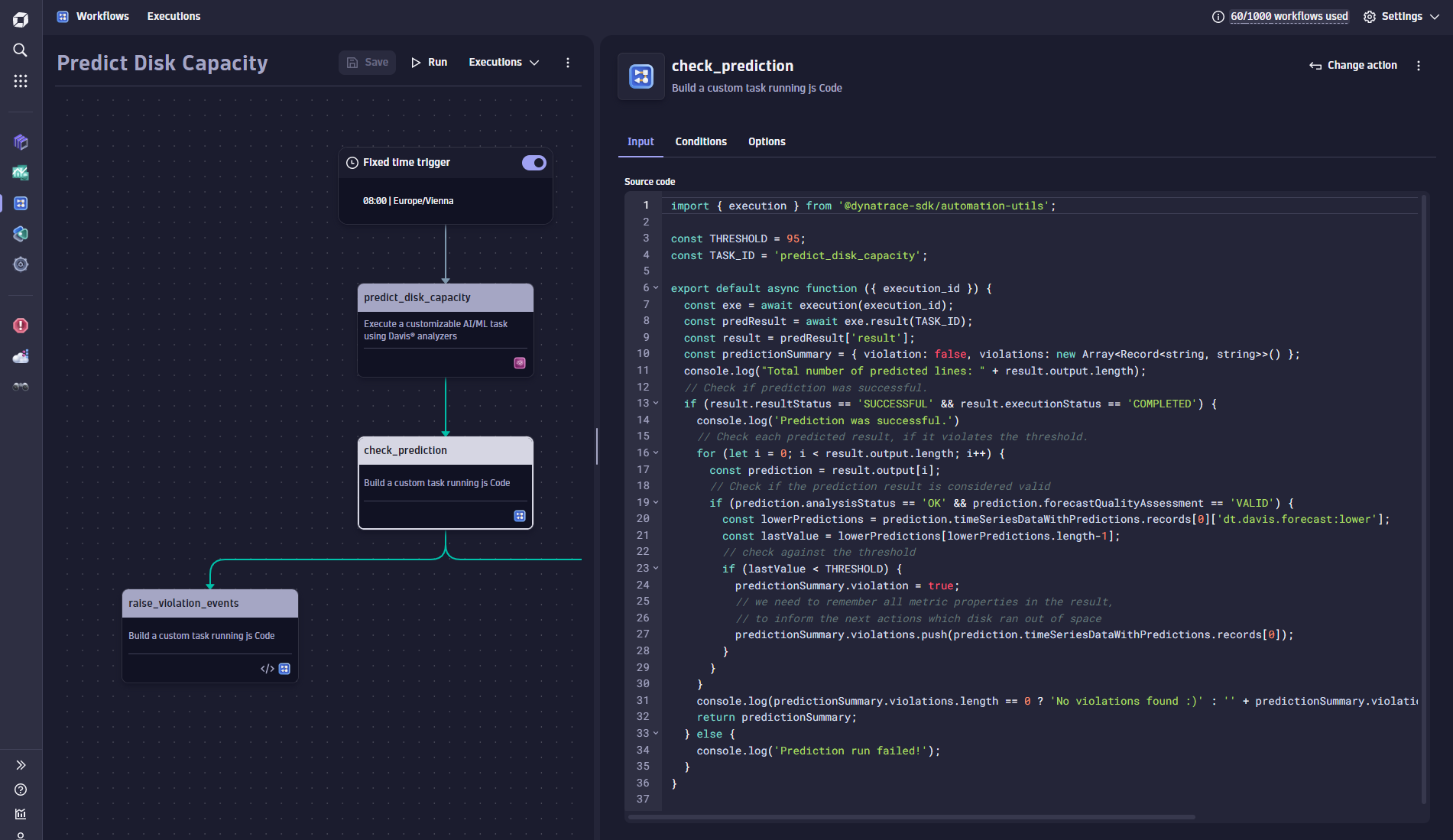
The TypeScript action returns a custom object that uses a Boolean flag (violation) to tell the follow-up actions about violations and an array of all the violation details (violations).
const predictionSummary = { violation: false, violations: new Array<Record<string, string>>() };
Tip: Download the TypeScript template from our documentation.
Trigger remediation actions
A collection of remediation actions can be used to follow up on predicted capacity shortages. In this example, two parallel actions are defined. One action sends out an email notification; the other raises a Davis problem for each violating disk. All remediation actions use the Boolean violation flag of the previous workflow action to avoid invocations when there are no violations.
Here you can see the invocation condition used in the follow-up actions that control the invocation.
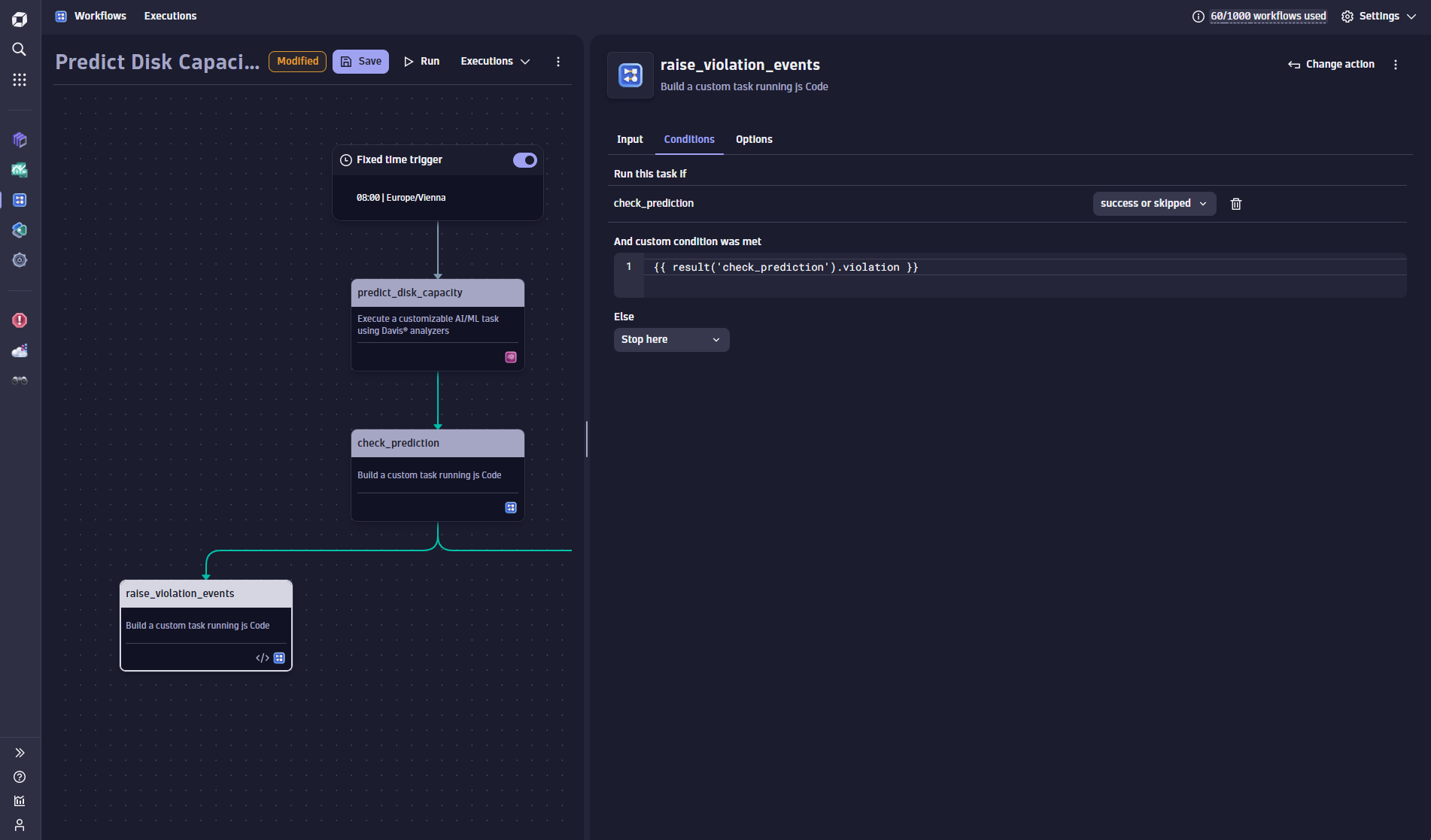
Raise events in case of disk capacity shortage!
A TypeScript remediation action is used to iterate through all the predicted disk shortages and to raise individual alarm events. Each alarm event has custom event properties that can be used to deliver further details about the situation and to further identify the disk or host.
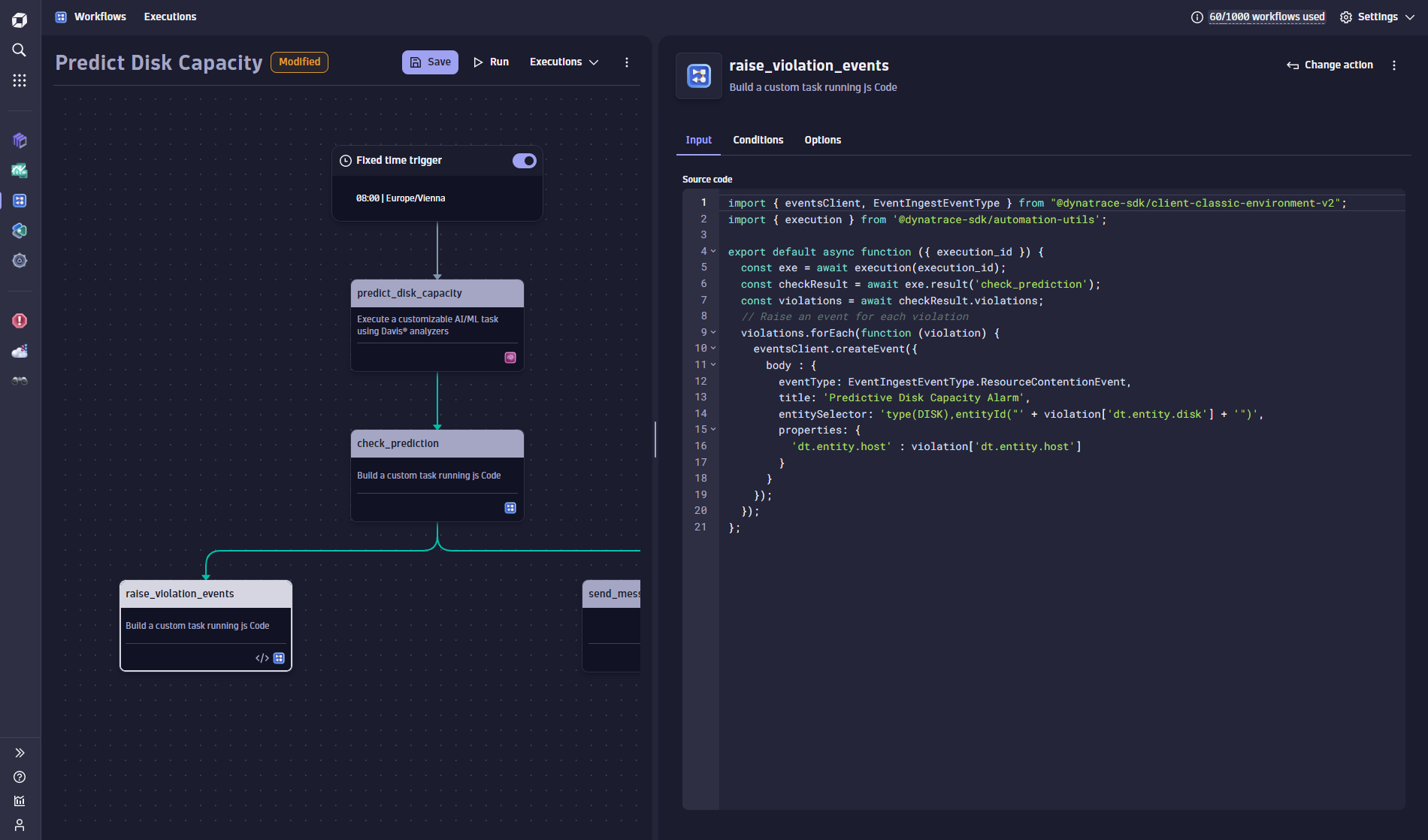
Tip: Download the TypeScript template from our documentation.
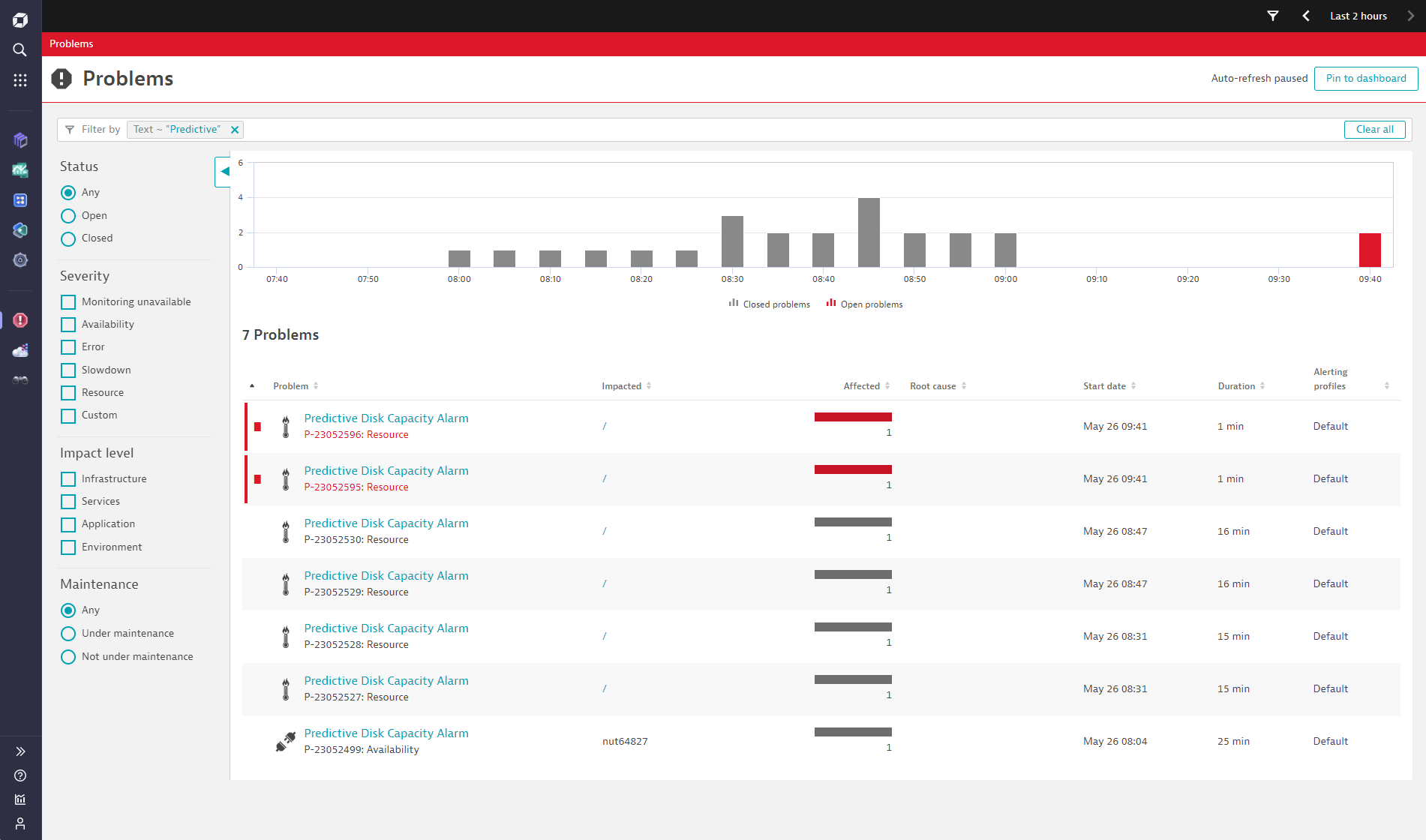
Review all Davis-predicted capacity problems
Navigating to the Davis problems feed, the operations team can review all the predicted disk capacity shortages. Remember, raising events and problems is an optional remediation step that can be skipped entirely by directly sending emails or Slack messages to the responsible teams.
The creation of alerting events within this workflow example highlights the flexibility and power of the Dynatrace AutomationEngine combined with the analytical capabilities of Davis AI and Grail.
Summary
The combination of Davis AI forecasts with Dynatrace AutomationEngine and Grail opens the door for many valuable use cases—anticipative management of capacity being the most prominent of these. Predicting future capacity shortages for thousands of disks or hosts allows operations teams to anticipate critical situations weeks before incidents occur. The flexibility and power of the Dynatrace AutomationEngine allow operations teams to react to detected shortages flexibly and to customize and implement their remediation flows.
You can install Davis® for Workflows via the Dynatrace Hub. As a starting point for implementing your own anticipative capacity management workflow, you can download all the TypeScript code used in this example from our documentation:
For full details, see Davis AI analysis in workflows documentation.


Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum