
As organizations struggle to achieve a measurable reduction in outages, mean time to repair and other incident management metrics are critical to DevOps success. But what is MTTR? It stands for more than just mean time to repair.
DevOps and ITOps teams rely on incident management metrics such as mean time to repair (MTTR). These metrics help to keep a network system up and running, a critical task that’s easier said than done. Other such metrics include uptime, downtime, number of incidents, time between incidents, and time to respond to and resolve an issue.
A 2022 Outage Analysis report found that enterprises are struggling to achieve a measurable reduction in outage rates and severity. They also found that the financial consequences of outages are steadily increasing. This pressure escalates the stakes on MTTR and other incident management metrics.
So, what is MTTR? Most often, it stands for mean time to repair. But it can also stand for mean time to respond, resolve, and recovery. All these definitions are distinct and important. Just as importantly, though, how does MTTR fit in with other incident management metrics? Here’s what these metrics mean and how they relate to other DevOps metrics such as MTTA, MTTF, and MTBF.
Understanding the most common incident management metrics
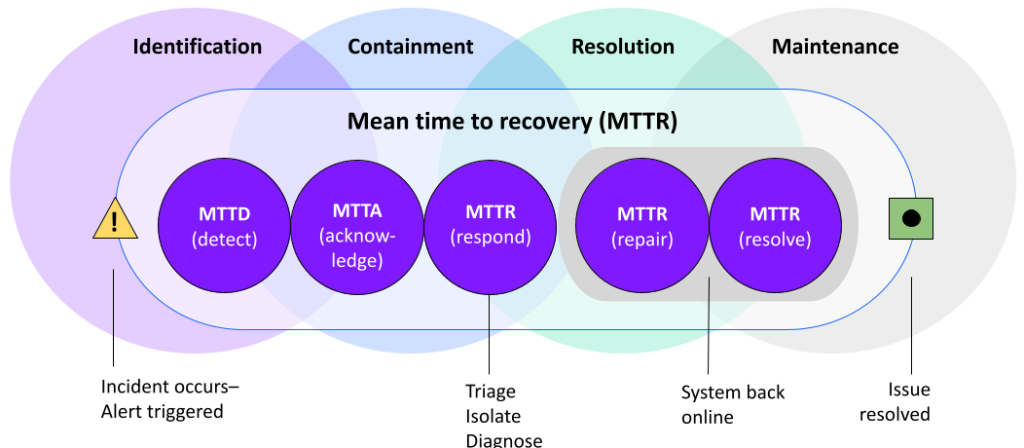
An IT incident is an unpredicted or unexpected event that causes a service disruption or outage that interrupts business operations. The four main stages of an IT incident are the following:
- Identification: Detects and records details of what occurred, prioritizes incidents in terms of impact and urgency and assesses the level of impact on customers and the business.
- Containment: Implements actions to safeguard affected systems, resolves incidents quickly and escalates an event to other teams when necessary.
- Resolution: Ensures remediation is complete and identifies when the current business impact has ended.
- Maintenance: Reduces the risk of an incident occurring again with root-cause analysis and continuous improvements to the system.
Most IT incident management systems use some form of the following metrics to handle incidents efficiently and maintain uninterrupted service for optimal customer experience.
What is MTTR? Breaking down the differences
MTTR stands for mean time to respond, repair, resolve, and recovery. Each is distinct and fits into its own spot in the incident management framework.
| Metric | Description |
|---|---|
Mean time to respond |
Mean time to respond (MTTR) is the average time it takes DevOps teams to respond after receiving an alert. Teams often use this metric to measure the time between when they detect an incident and when they mount a remediation plan. Many teams include the time it takes to repair or remediate the issue in this metric. This does not include lag time in the alert system.
Calculate MTTR by measuring the time from when your team detects an incident to when you launch (or complete) the repair or remediation plan. Divide that time by the number of alerts your team responded to in a given timeframe. MTTR is often used in cybersecurity along with mean time to detect (MTTD) to measure a team’s success in neutralizing system attacks, and the ability to predict and prevent future security breaches. |
Mean time to repair |
Mean time to repair (MTTR) is the average time it takes to repair a failed component, application, or service. This measurement includes time spent testing until the service is fully functional again. Generally speaking, mean time to repair focuses only on the average time a team takes to implement the fix once your team diagnoses the problem.
To calculate MTTR, take the total time your team spends correcting failures and divide by the number of completed repairs. If it takes 30 hours to correct five issues, you have a mean time to repair of six. Collect this data over time to calculate an average MTTR score. Organizations often include MTTR in a maintenance contract or service level agreement (SLA). If one system has an MTTR of 24 hours and another has an MTTR of three days with equal time between failures, the first system is more valuable because its availability is higher. |
Mean time to resolve/remediate |
Mean time to resolve/remediate (MTTR) is the time it takes to fully diagnose and fix a malfunctioning system. This includes fixing the root cause of the problem so it doesn’t recur. It shows how efficiently your DevOps team is at quickly diagnosing a problem and implementing a fix. A good mean time to resolve rate reflects how well a team anticipates and plans for malfunctions.
To calculate MTTR, add up the time it takes to diagnose and resolve incidents within a specific time period, then divide by the number of incidents. If systems were down for two hours in a 24-hour period and teams spent two hours diagnosing and fixing the outage, the time to resolve is four hours. Mean time to resolve is the average amount of time it takes DevOps to diagnose and fix an issue. This includes time your team spends investigating, repairing, and testing. The timer doesn’t stop until the system is fully operational and your team has addressed the underlying problem to avoid future outages. |
Mean time to recovery |
Mean time to recovery (MTTR) measures the entire amount of time it takes to get a downed network or system back up and running. It starts when the alert is first triggered and ends when all affected systems are functioning as normal.
Calculate MTTR by dividing the downtime for a given period by the number of incidents. If you had 20 minutes of downtime caused by two different events over a period of two days, your mean time to recovery would be ten minutes. MTTR measures the efficiency of your entire incident response capability. It spans the whole outage period, from the moment the system or product malfunctions until it resumes normal functioning. MTTR gives you insight into how rapidly your incident response team can get your business and any impacted customers back to normal. It’s a good aggregate metric to measure the overall efficiency of all aspects of your incident response protocols. |
Learn more about the benefits of incident management to DevOps practices, read the ebook, A beginner’s guide to DevOps.
What are MTTD, MTTA, MTTF, and MTBF?
The mean time to recovery lifecycle includes more measurements at the beginning and the end of the process. These incident metrics measure how quickly teams detect issues and acknowledge them to stakeholders at the outset. They also measure overall failure statistics to determine reliability and repair efficiency over time.
MTTF measures the reliability of a network and durability of its hardware. Shorter MTTF indicates more potential downtime since failures require downtime while the sytsem is replaced. MTTF measures the operational phase of components and is part of the maintenance cycle.
| Metric | Description |
|---|---|
Mean time to detect |
Mean time to detect (MTTD), measures how long a problem exists before it’s discovered. MTTD is a primary key performance indicator for IT and DevOps teams. The longer an incident remains undetected, the more time it has to wreak havoc on the system. MTTD is also referred to as Mean time to identify (MTTI). MTTD is the time it takes to detect or get alerted to an incident.
Calculate MTTD by measuring the average time it takes to discover incidents over a set period, then divide by the number of incidents. A low MTTD is important because the faster you discover issues, the less potential damage to your systems, and the less costly they may be to fix. |
Mean time to acknowledge |
Mean time to acknowledge (MTTA) is the length of time between when a system generates an alert and when a team member responds. MTTA is concerned with how long it takes a team member to begin working on a problem after they receive the alert.
A low MTTA shows a team is responding rapidly, prioritizing high-risk alerts that may have the most critical downtime and outages. MTTA is useful for measuring your alert system’s effectiveness and helping your team meet its responsiveness agreements. A low MTTA indicates a “fix it” mindset to prevent any loss of service that is critical to Digital Experience Management. |
Mean time to failure |
|
Mean time between failures (MTBF) |
Mean time between failures (MTBF) measures the average interval between system failures of repairable systems. MTBF is another way to measure system reliability.
Shorter MTBF indicates more potential downtime since failures require identification, containment, and resolution measures. Like MTTF, MTBF is part of the maintenance cycle and measures the operational phase of components. |
How to measure MTTR and slash incident response times using AI and automation
Measuring MTTR depends on detailed metrics from all monitored systems. In traditional on-premises environments, that’s complicated enough. But effectively managing incident response at the scale of modern multicloud environments requires a platform approach that uses artificial intelligence for IT operations (AIOps) and automation.
The Dynatrace Software Intelligence platform monitors the full multicloud stack. Using fault-tree analysis, Dynatrace automatically identifies issues and pinpoints their root causes in context. This automatic discovery cuts metrics gathering and root-cause analysis time to near zero for all incident management stages, including MTTD, MTTA, MTTR, and MTBF.
Automatic and intelligent analysis from Dynatrace enables early detection and automated response, which prevents problems from escalating into an outage. DevOps teams can set any of the incident management metrics as a service level objective (SLO) to automate incident response and slash MTTR.
To learn more about how MTTR and incident management fit into a site reliability engineering (SRE) strategy, read the Dynatrace State of SRE Report.


Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum