
At Nobl9's SLOconf, Dynatrace "SLOgicians" anchored 5 sessions demonstrating benefits and best practices for developing and implementing (SLOs).
Dynatrace recently launched an integration with Nobl9 (soon to be available on the Integration Hub). At Nobl9’s SLOconf—Service-Level Objective conference for site reliability engineers—Dynatracers Andi Grabner, Kristof Renders, Wolfgang Heider and Jürgen Etzlstorfer anchored 5 sessions that demonstrated many benefits and best practices for developing and implementing service-level objectives (SLOs), educating the audience and establishing themselves firmly as “SLOgicians.” Here’s what they presented, and why we at Dynatrace are so excited about SLOs.
What are SLOs?
Service level objectives, or SLOs, are an agreed-upon means of measuring the performance of a software application. Modern software applications running in production environments generate a wide variety of metrics and data points every second that represent the state and performance of the system. SLOs define or support a set of higher-level business objectives by leveraging the data and insights from observability tools.
SLOs can include business metrics, such as conversion rates, uptime, and availability; service metrics, such as application performance; or technical metrics, such as dependencies to third-party services, underlying CPU, and the cost of running a service. Organizations commonly use SLOs in production environments to ensure released code stays within error budgets.
Consider this analogy: To identify strengths and areas for improvement, athletes need well-defined goals against which to measure themselves. Only by taking a carefully considered and meticulously tracked approach can they reach peak performance. The same is true for software.

How do you define SLOs?
With applications continually increasing in both scale and complexity, defining SLOs to maintain service quality and up-time has become critical. But with an overwhelming volume and variety of constantly shifting data, where do organizations start to determine their service-level objectives?
In their session Top 5 customer SLOs: Questions and decisions to define your SLOs, Dynatracers Kristof Renders and Wolfgang Heider presented a set of decisions organizations need to make to establish a set of objectives.
“To establish the most meaningful objectives for your organization, the user must be the focus,” Heider said. “Organizations need to view the services their software provides in terms of what is important to the customer or end-user.” Equally important is how user perception of your app aligns with your organization’s strategic and business goals, such as growing a userbase, building market share, or driving sales.
To find your objectives, Renders and Heider noted the importance of identifying key aspects of your business goals. The top 5 service-level objectives they see in the field are useful examples when setting up your own set of objectives.
Top 5 customer SLOs
- Application satisfaction. Are your users happy with the application? The industry standard for measuring user experience is called the application performance index (apdex), which provides a quick index between 0 and 1.0 and establishes a baseline depiction of user satisfaction. This metric is a standardized index derived from various application endpoint metrics such as response time, failures, and a variety of other internal data points.
- API endpoint success rate. For a given API your application exposes, how reliable is this endpoint? This allows quick insight into the rate of successful calls. This metric tells you what percentage of all the actions a user tried to take resulted in errors. If you run an e-commerce website and 10% of the users are unable to submit payment, this metric can be used to proactively alert you to an area that requires repair or refinement.
- Key user action performances. Using a hypothetical e-commerce application as an example, key user action performances could mean the number of checkouts that occur or the number of times a user adds an item to their cart. Anything a user does when navigating through your app or website can be turned into an action-based objective, captured with the right tools, and tracked.
- Endpoint synthetic availability. With synthetic availability, you can execute a variety of automated, synthetic tests against your application instead of using real user traffic and build objectives around the results. Synthetically created metrics serve a different purpose than those based on real users. While real user metrics serve as a customer’s point of view on availability, the goal to measure uptime defined in contracts might be based on synthetic periodic checks of services. You can also run synthetic tests in pre-production environments to simulate how users interact with the application.
- Number of instances to serve load. How many compute instances is your application using? If you have very little load on the system or a low number of users, but a very high number of computers, CPU, or memory being utilized, this could indicate an application issue, such as processing power wasted on useless tasks. It could also indicate an infrastructure issue like a poorly tuned set of rules that determine how your application should scale. In either instance, more compute often translates to more money spent on running infrastructure. “We can control and monitor this . . . as it can be a sign of architectural cost or inefficiencies,” Renders noted.

“It’s easy for organizations to get lost in the abundance of data they are gathering about the performance of their apps and services,” Renders said. “Boiling that down into proverbial ‘check-engine lights’ means organizations can focus on what’s important – providing value to their customers and not getting lost in the weeds of too much data. This will make organizations quicker at creating value at a lower cost and also have a positive impact on the bottom line for the business.”
Benefits beyond production reporting: SLOs bridge DevOps and SRE
In the session SLOs Beyond Production Reporting, Andi Grabner tackled a different question: “We can use SLOs in production to ensure new releases don’t violate our error budgets and jeopardize reliability –but why not start thinking about SLO-driven engineering?”
Traditionally, DevOps engineers are focused on delivering stable, automated deployment pipelines to production environments, and they want to invest in features that deliver automated value to their customers. For their part, site reliability engineers (SREs) use automation to ensure the resiliency of operations.

“SLOs bridge the gap between DevOps and SRE,” Grabner explains, giving common ground to two teams that sometimes seem at odds with each other. Service level objectives provide a shared goal and a foundational framework for both teams to deliver quality. If SLOs are established and respected, both teams are optimizing toward underlying objectives that are clearly defined, widely understood, and agreed upon.
If teams can shift SLOs that are normally monitored by SREs (such as response time) to the left within the production process, they can be used by DevOps teams as quality gates before code goes into production.
Want to learn more about DevOps?
Streamline the way IT operates and enterprises grow with observability and AIOps. Read our DevOps eBook – A Beginners Guide to DevOps Basics
SLOs as quality gates: powering automation in delivery pipelines
Quality gates can be thought of as “go” or “no-go” checks applied to a release to determine if it’s ready to be promoted to the next DevOps stage or a production environment. These checks can prevent issues from frustrating end-users and violating service level agreements (SLAs), and it can also serve to make the release process more efficient and applications more resilient.
“We all want to enable more automated quality gates in continuous delivery,” Grabner said in his session, SLOs for quality gates in your delivery pipeline. “Where many organizations fall short is that it’s really hard to automate analysis across all their different tools: security scanning tools, functional test tools, performance testing tools, and observability tools.” To deal with this, most organizations build multiple dashboards that analyze different quality metrics to influence decisions, such as whether or not to release. This approach works, but it doesn’t scale.
Grabner suggests that teams should leverage their production SLOs and use them as quality gates in pre-production. “By shifting SLOs left into pre-production and bringing the concept of SLOs into the minds of everyone focused on continuous delivery,” Grabner says, “we can solve the pain of a manual approach to enforcing quality gates because we can fully automate them, which means everything is consistent and much faster.”
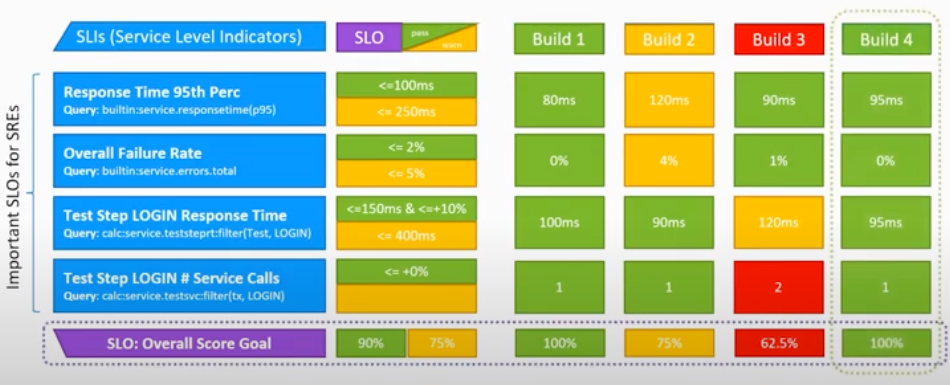
The process works like this:
- Identify service level indicators (SLIs). These are metrics that can come from many sources using many tools, for example, response time, failure rate, login response time, and so on.
- Identify SLOs. These are the actual tolerances your systems must maintain, for example, <=100 ms, <=2% and so on. These measurements can be static or dynamic.
- Define a scoring scale. For example, 90% might mean systems are green; 75% to 90% triggers a warning (yellow); below 75% indicates a problem (red).
Each new build generates scores across these consistent measurements, which enables teams to immediately see where issues are developing and what needs to be fixed for the next build.
Application resilience through SLO-based chaos engineering
Shifting SLOs left to become pre-production quality gates is a great start to building resilience into software. A complimentary practice is SLO-based chaos engineering.
Despite its name, chaos engineering is a controlled practice of testing a system’s resiliency by simulating catastrophic outages that can happen in production, for example shutting down servers, injecting latency, and exhausting resources.
In his session Evaluate application resilience with chaos engineering, Jürgen Etzlstorfer explained how DevOps teams can evaluate system resiliency well before production stages by using SLOs to discover and track how apps and services operate in the face of synthetic outages.
Etzlstorfer demonstrated how you can construct pipelines that include chaos experimentation to cause disruption and outages in the software while simulating real-world load to determine the impact of the outages. This is measured by implementing quality gates based on SLOs that ensure only resilient applications are deployed into production.
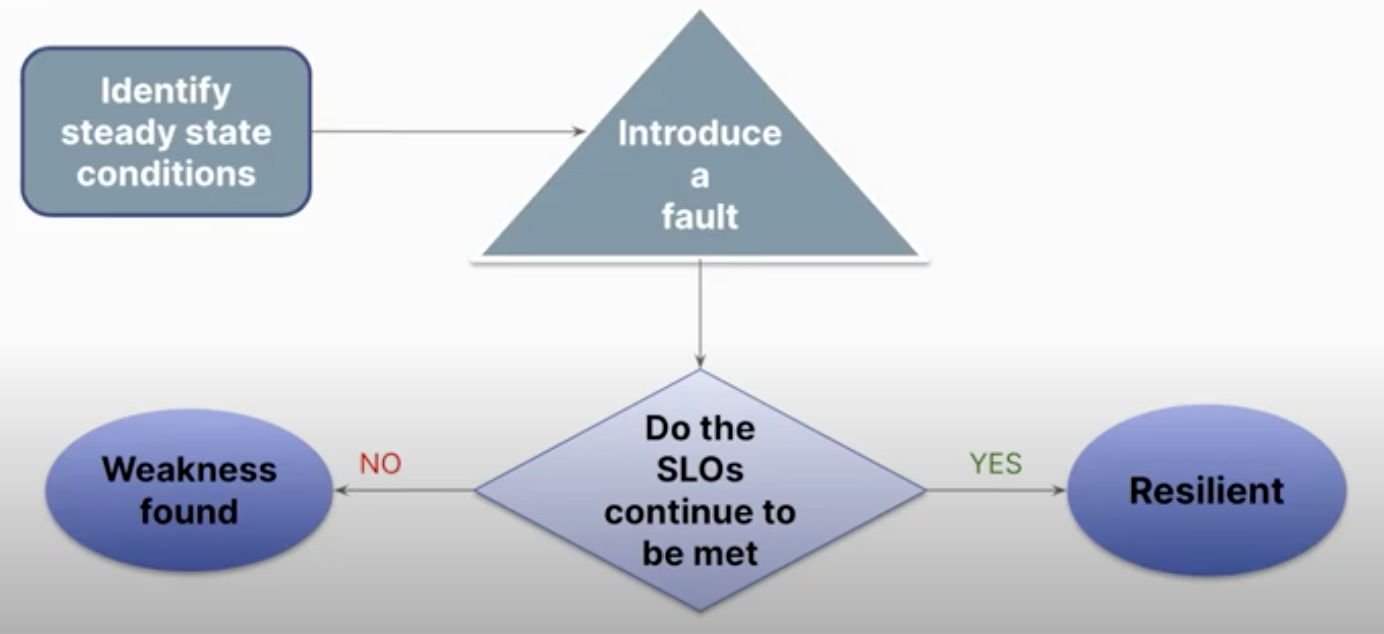
One example is to measure the impact of a crashing application on the overall availability of a software system. Another is to measure the impact of a network outage on the applications. Both resilience criteria can be defined as SLOs, and the application must satisfy resiliency SLOs in order to be allowed to run in production.
Once an SLO is expressed as code, teams can use it to run chaos tests, acceptance tests, and resiliency tests in pre-production and production environments.
Standardizing SLOs as code
With the potential of SLOs to influence every step and touch every team involved in the DevOps pipeline, it’s important to establish standards around your objectives. In his concluding segment, Standardizing SLOs as code, Grabner described why applying standards to objectives enhances agility and enables teams to automate more processes.
Although many vendors and open-source communities offer tools to create and define objectives, there is not a single clear standard of implementation. Because each situation requires unique code to be written, any time you need to switch implementations, you have to re-write all the objectives in the new standard. Additionally, each implementation requires expert knowledge.
Centralizing on an objective standard and creating this standard as code not only simplifies the process when you need to switch implementations, but enables teams to deploy standardized objectives into non-production environments.

With objectives as code, instead of creating objectives in a webpage or graphical user interface, they can be reused in different environments. The ability to repurpose production objectives into pre-production systems is a key benefit, as it allows you to automate software testing and deployment.
With the Dynatrace open-source project, Keptn–an enterprise-grade control plane for cloud-native continuous delivery and automated operations–developers can define the SLOs (what to measure) and specify the criteria for the service level indicators (SLIs–how to collect the data) as two distinct inputs. Distinguishing these roles creates a healthy division of labor: the expert responsible for defining the objectives as code can focus on the key performance indicators important to the business, and the software engineers can focus on the implementation. By converting objectives into code and adopting an open standard, businesses can extract the data faster through efficient collaboration.
SLOs + intelligent automation = better software, happy developers, and better user experiences
Dynatrace has fully embraced SLOs as a method to shift quality gates left into pre-production and to promote automated quality gates. As a leader and regular contributor to open standards, Dynatrace is collaborating with Nobl9 and other core contributors on OpenSLO, an open-source project that makes SLOs portable across the DevOps toolchain.
If you are already a Dynatrace customer, contact the ACE Services team to help you define the correct SLOs for your organization.
The material presented at the SLOconf covered a wide range of SLO topics, from how to determine and define the metrics for success, to discussions around evolutionary tooling and practices that have the potential to turn any app- or service-focused organization into a data-driven powerhouse. You can catch up on any of the sessions here.




Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum