
Dynatrace Managed now compresses transaction data that's older than three days and includes improvements to Adaptive Data Retention ADR).
Dynatrace Managed is the on-premises software intelligence platform that brings Dynatrace SaaS capabilities to your infrastructure while ensuring resilience and optimizing the total cost of ownership. One main advantage of using a product in SaaS mode is the automatic scaling of resources based on system load. In on-premises environments, resource scaling is not always easy and requires time and thorough planning by the administrator. Using existing storage resources optimally is key to being able to capture the right data over time.
Dynatrace continuously invests in improvements to resource optimization and the mechanisms that allow Dynatrace Managed to automatically adapt to changing resource usage. In this blog post, we announce:
- Compression of transaction data that’s older than three days
- Improvements to Adaptive Data Retention
Transaction-data compression for Dynatrace Managed environments
Dynatrace stores transaction data (for example, PurePaths and code-level traces) on disk for 10 days by default. Data retention settings for different data types determine the length of time for which data is stored and the amount of data that’s stored over time. These retention settings can be configured by your Dynatrace Managed admin. In a typical usage scenario, recent data is accessed more frequently than older data. Dynatrace Managed now compresses transaction data that’s older than three days and automatically decompresses the data at read time. This decompression of data is achieved with minimal impact on performance and costs. Compression of data that’s older than three days utilizes one virtual CPU.
Increased storage space availability
The compression of transaction data older than three days can free up to 50% more storage space in your Dynatrace Managed Cluster. The amount of storage you gain depends on many factors, including:
- Retention times configured for your environments and transaction-data storage, in particular. As only data older than three days is compressed, the amount of storage space gained relates directly to configured retention times. For example, when retention times are set to 5 days, only 2 days of older data is compressed; or when set to 10 days, 7 days of older data is compressed.
- Storage quotas defined for your Dynatrace Managed deployment and its environments.
- The amount of transaction data captured relative to other Dynatrace data stored on disk (for example, data storage used for Session Replay or Log Monitoring).
The following are examples of how these different factors impact overall storage gained after compression. However, because of the factors mentioned above, these examples should not be used to predict your actual storage gains:
- In an environment where the retention time was set to 10 days, 70% of data was compressed. The compression resulted in disk-space savings of about 50%.
- In an environment where the retention time was set to 5 days, 40% of the data older than three days was compressed. This resulted in disk-space savings of about 30%.
When transaction-data compression is activated for Dynatrace Managed
Transaction-data compression is enabled for all Managed deployments beginning with Dynatrace Managed version 1.222. After the update, you need to restart your Dynatrace Managed Cluster within a maintenance window to start transaction-data compression. You can expect to see a slight increase in CPU usage (by a few percentage points) of one virtual CPU until the compression of the existing data is complete. Following the initial compression of data older than three days, data is automatically compressed on the fly as it ages.
Duration of initial transaction-data compression
The duration of initial compression depends on your environment and the data stored, so it’s not possible to predict the exact duration. Configured retention times and your Cluster infrastructure directly impact the duration:
- Compression begins with processing of the oldest available data. This typically doesn’t include code-level data and is stored in small chunks with high retention times. Therefore, not much impact on disk usage is visible during the initial phase.
- As compression continues over time, data with lower retention times, for example code-level data, is compressed. This data is stored in larger chunks and has higher impact on disk usage.
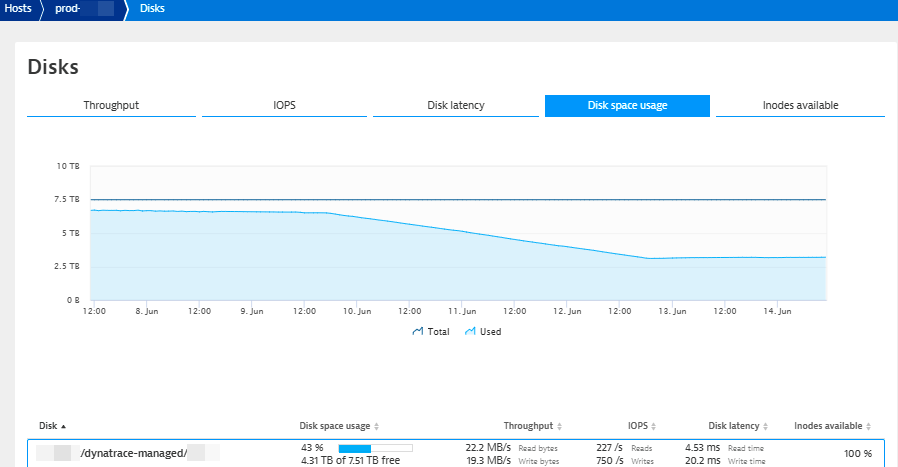
The screenshot below of one of our own test environments visualizes how disk-space usage consistently decreases after the initial activation of compression:
- Compression of data begins immediately after compression is enabled on June 7.
- Only a slight increase in free disk space can be seen in the next few days as the oldest, smaller-chunk data is compressed.
- The gain in free storage due to compression becomes more evident on June 9, when the compression of data in larger chunks begins.
- Data compression is completed on June 12.
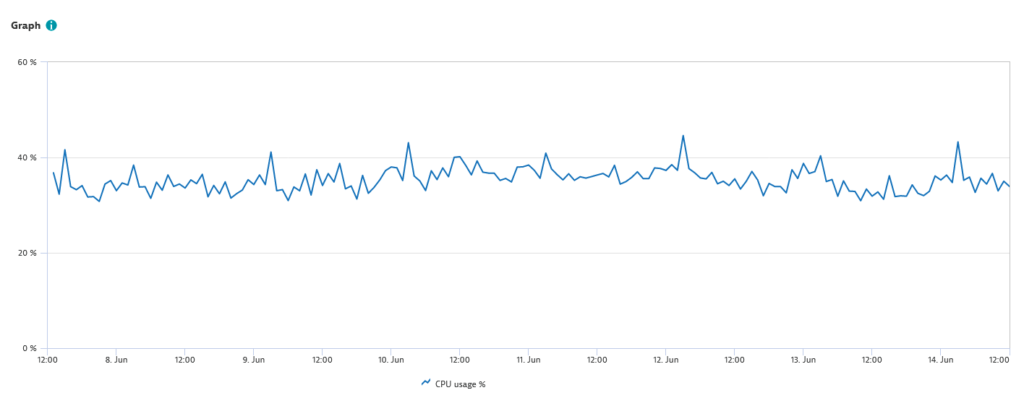
The screenshot below shows CPU usage on the same server (a 32-core machine). Only a slight increase in CPU usage is visible after the start of compression on June 7.
Transaction-data compression eventually results in more available disk space on your Managed Cluster and enables you to increase configured retention times for your environments and retain data for longer periods of time.
Improvements to Adaptive Data Retention (ADR) for Dynatrace Managed environments
Dynatrace retention times for certain data types can be configured by the administrator of your Dynatrace Managed deployment. When the data-retention cutoff for a data type is reached, older data is automatically deleted. The amount of data that can be stored is determined by the available disk space and the storage quotas defined for the deployment and its environments. To ensure that recent data is always captured even when disk resources run low or quotas are exceeded in deployments, Dynatrace Adaptive Data Retention automatically adapts retention times. When ADR is triggered, retention times are increased or decreased for:
- Transaction data (for example, PurePaths and code-level traces).
- Session Replay data.
As soon as disk space or quotas are freed up again, retention times are continuously increased until they reach the configured values.
With the new improvements to ADR, Dynatrace has unified how we automatically adapt retention times for a Dynatrace Managed Cluster:
- If a Cluster node runs out of disk space, retention time is automatically reduced for all environments on that Cluster
- If an environment violates its storage quota, retention time is automatically reduced for that single environment
For more information on ADR and what you can do when ADR is active, see Adaptive Data Retention in Dynatrace Documentation.
What to expect with the ADR improvements
The improvements to Adaptive Data Retention were enabled with Dynatrace Managed version 1.216.
ADR is only activated for your deployment if:
- Disk space is no longer available.
- Storage quotas are violated in an environment.
When ADR is activated, you’ll see a corresponding message in the Storage settings section of your environment’s page in the Cluster Management Console. The screenshot below shows the messaging for an environment with active ADR resulting in reduced retention time for transaction-data storage.

These improvements to ADR enhance existing behavior and lead to more equitable data retention across environments in a Dynatrace Managed Cluster.
Questions?
Your input matters. Please share your feedback with us by posting your questions and clarifications in the Dynatrace Open Q&A forum.



Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum