
Very often, I heard that chaos engineering is only a technique used by larger companies (like Netflix) or in cloud-native environments. Last week, I watched the Mastering Chaos Engineering Performance Clinic from my colleague Andi Grabner and Ana Margarita Medina, Chaos Engineer from Gremlin which could have totally changed this opinion of the watchers.
You should read on if:
- You want to get an idea what chaos engineering is
- You want to know if chaos engineering is only usable in cloud native environments
- You plan to use chaos engineering in your delivery process
Performance clinic: Mastering Chaos Engineering
If you want to watch the more in-depth version of Mastering Chaos Engineering, head to our on-demand webinar here:

Why would I want chaos in my environment?
With the rise of cloud and container technologies, companies developed a lot of microservices. As this led to a countless number of connections and dependencies between them, the complexity of such systems increased. Chaos engineering provides mechanisms to test for failures, create awareness of this systems in terms of how complex and how distributed they are, and to be proactive.
Controlled Chaos
At first, chaos engineering is neither intended to break production nor to break things in a random way. Moreover, chaos engineering experiments should be designed to reveal weaknesses in systems in a planned way with the aim to make systems more robust. Additionally, chaos engineering can be used to verify your monitoring. You might create chaos experiments which break single components of a distributed system and want to make sure that your monitoring system informs about such failures (but the system should work either way).
In the Performance Clinic, Ana also mentioned it can be used to train engineers in terms of training failure situations. Also, a defined load model can be generated and therefore, experiments can be used to right size a system. Last but not least, using chaos engineering techniques enable to replicate outage scenarios and could prevent regressions to happen.
But it is only usable in a cloud native environment, right?
Fortunately, chaos engineering is definitely not only useful in cloud native environments – it can also be used for monolithic services on virtual machines. While cloud native platforms – such as Kubernetes – have a lot of built-in mechanisms for error prevention and recovery, there are a multitude of failure scenarios which could be covered in monolithic environments.
Experiments can be very specific, for instance it can be tested what happens when an application loses its connection to the database and if the auto-scaling and failover mechanisms work properly without downtime. An example of failures which possible could happen in monolithic (but also cloud native) applications is illustrated in Figure 1.
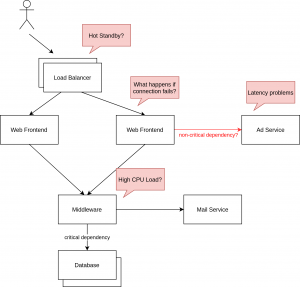
When doing chaos engineering in cloud native environments, failures which can happen on the respective platform (e.g. Kubernetes) should be covered. Therefore, the configuration of Horizontal or vertical auto-scaling would be part of the test set as well as testing for Host or Pod shutdown or limits. As Kubernetes service discovery is highly dependent on DNS, failures on this service would also be a good candidate for testing.
Difference to vulnerability testing and other disciplines
During the Q&A of the webinar, many attendees raised questions around how chaos engineering differs from other disciplines and techniques organizations have already implemented – like vulnerability or performance testing. The question was: What is the difference? As it seems like many techniques used in chaos engineering might be covered in other disciplines – like vulnerability or performance testing – where the difference is.
Ana stated that things covered in chaos engineering tests are not always part of functional tests. Chaos engineering combines many of these things on a higher level to validate the resilience, but also the recoverability (and therefore disaster recovery) of a system. As it tends to make disaster recovery rather a standard procedure than an emergency, it should prevent doing it manually.
I want chaos engineering; how should I start?
At first, you should take a look on architecture diagrams and mind about the design of the application to get an overview about things which could break and their impact. Afterwards, you should set the target metrics baseline, such as Service Level Indicators (SLIs) and Service Level Objectives (SLOs) per service to get an idea how your system should behave. With the information gathered, you can form a Hypothesis (what happens if the node has a CPU spike or runs out of memory), but also abort conditions for the case that the chaos experiments run in production and really break a system.

By defining the blast radius of a chaos experiment, you define if it should run on pre-prod, staging or prod, but also how many application instances should be affected. In any case, it should be the target to run these experiments in production, but in a safe way. After running the experiment, the results of this experiments will be analyzed. During this stage, you want to find out how your system, but also your monitoring behaved. Based on that, measures can be implemented to make the system more resilient in the future. After getting the system stable for the defined scope, this can be expanded (e.g. to Staging) and re-tested.
To make others aware of the things you done and how you improved your system, you should share your results with your team. Additionally, your improvements and findings can be shared with open source communities to provide insights how specific technologies can be configured more robust.
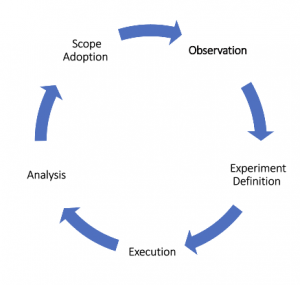
5 step recipe from idea to execution
This approach can easily be applied to an environment which is monitored by Dynatrace and using Gremlin as a chaos engineering platform.
- The current state of an application can easily be observed using Dynatrace SmartScape and Service Flow. Using this information, links between the service and the response times without any load are gathered. When gathering information about your systems, you may differentiate between critical or non-critical dependencies. Non-critical dependencies are the ones which should have no or a small impact, if they fail, e.g. an advertising service or an e-mail service. Otherwise, critical dependencies – as the connection from the connection to its database – might cause the application to fail. These assumptions can and should be used in the experiments.
- Afterwards, you form your Hypothesis for the chaos experiment. For instance, it can be defined that a CPU attack (high CPU usage) on 75% of all host will be executed, and this should have no impact on the overall application behavior. Additionally, possible Abort Conditions could be HTTP 400 or 500 requests, failing synthetic checks, but also problems identified by Dynatrace. This hypothesis will be used to identify exactly this attack in Gremlin.
- When the attack is started, Dynatrace gets notified that a Gremlin attack is running, and shows this as an annotation in the Dynatrace host view. Using this information, the impact of the attack is clearly visible in Dynatrace and if a problem is raised, it will also be visible that a chaos experiment was running when it happened. As mentioned before the experiment can be stopped when Dynatrace detects an error. After the testing a finished event is sent to Dynatrace, so the annotation will not be added to upcoming problems.
- In a perfect world, your SLIs and SLOs should not be impacted when chaos experiments running, as the system should be resilient enough to deal with the injected problems. Furthermore, you want to validate that problems with soft dependencies will not have an impact on the system while hard dependencies could cause larger problems in the system.
- After the test has been started, the resiliency problems can be solved, and the experiments started with the same or a larger scope.
Conclusion and further reading
Using chaos engineering enables Site Reliability Engineers to train disaster recovery, to improve the resilience of systems and to build awareness for problem situations which could happen. Chaos engineering should not be implemented with the intention to break production, experiments should be designed to make systems more resilient (like you would do with integration or unit tests).
Dynatrace and Gremlin can be used for chaos experiments. While Gremlin is an awesome tool to execute chaos experiments, Dynatrace observes the systems behavior during the test and provides information to Gremlin. If you want to try out chaos engineering, just create a free Dynatrace Trial account and use the free version of Gremlin.
The full recording of the Performance clinic can be watched here.


Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum