
|
Johannes Bräuer Guide for Cloud Foundry |
Jürgen Etzlstorfer Guide for OpenShift |
| Part 1: Fearless Monolith to Microservices Migration – A guided journey | |
| Part 2: Set up TicketMonster on Cloud Foundry | Part 2: Set up TicketMonster on OpenShift |
| Part 3: Drop TicketMonster’s legacy User Interface | Part 3: Drop TicketMonster’s legacy User Interface |
| Part 4: How to identify your first Microservice? | |
| Part 5: The Microservice and its Domain Model | |
| Part 6: Release the Microservice | Part 6: Release the Microservice |


On our journey about breaking-up the monolith, we identified a microservice candidate that we will extract from the monolithic application. It is OrdersService that is responsible for booking tickets and which we have “virtually” introduced in our application by leveraging the Dynatrace feature custom service detection. After monitoring OrdersService for a while, we are aware of traffic that flows through this service and how it can be decoupled from the code base of the monolith since we know the exact methods that are involved.
At this point, we have a good understanding of where to break the monolith from a code-perspective, but stop – do we know how data is managed by the planned microservice? Which data is read, inserted, updated, or deleted by OrdersService? Be calm, Dynatrace can help us there. Thus, this part of the blog post series is dedicated to the data management of the microservice. The overall goal is that the OrdersServices consumes legacy data from the monolith but persists new data in its own database.
To follow this part of the blog post series, you need two projects available on GitHub:
- orders-service
- backend-v2
Conceptual Overview of Data Management
In Part III of Christian Posta’s blog series, he discusses the data management of a freshly decoupled microservice and highlights various approaches for dealing with legacy and new data:
- Use an existing API of the monolith to keep the data management in the monolith’s field of duty
- (If no appropriate API is available) create a new lower-level API for the microservice, but keep the data management at the monolith’s end
- Do an Extract, Transform and Load (ETL) process from the database of the monolith to the database of the microservice and keep both in sync
Please consider Christian’s blog post, to get more details about the benefits and drawbacks of the above-mentioned approaches.
In the course of extracting OrdersService, he develops a best practice that provides an own database for the new microservice, involving a connection right up to the monolith’s database. This connection is necessary because the legacy data (in monolith’s database) is going to be the starting point of our new OrdersService. Besides, we want to introduce this new service in a way that properly encapsulates the logic of booking tickets, allows to take load, and to have a consistent view of what is stored by the monolith as well as by the microservice. As a result, we can launch the microservice since it is fully functional and does not mess up the old database.
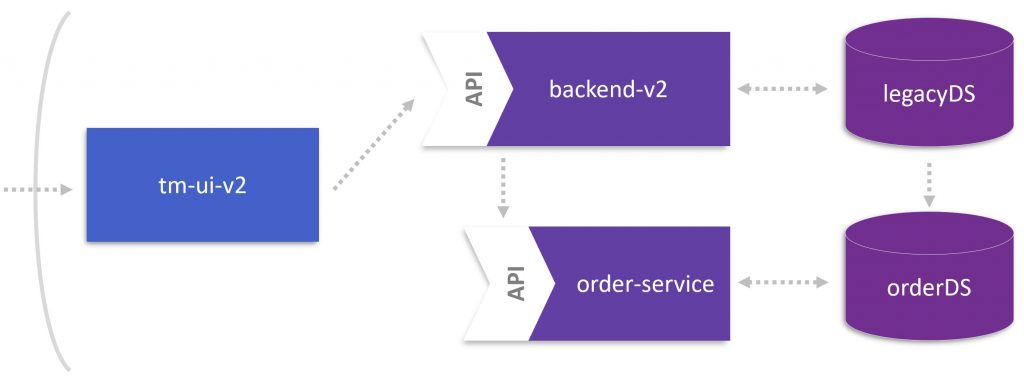
Understand the Data & Domain Model
To achieve the solution outlined above, we should understand OrdersService’s data model. For the sake of clarification, the data model shows how data is stored and entities relate to each other on the persistence layer. Since the data model keeps just an eye on persisting data, we must be aware of additional entities used by the microservices. This is defined by the domain model, that describes the behavior of the solution space of the microservice’s domain and tends to focus on use case scenarios.
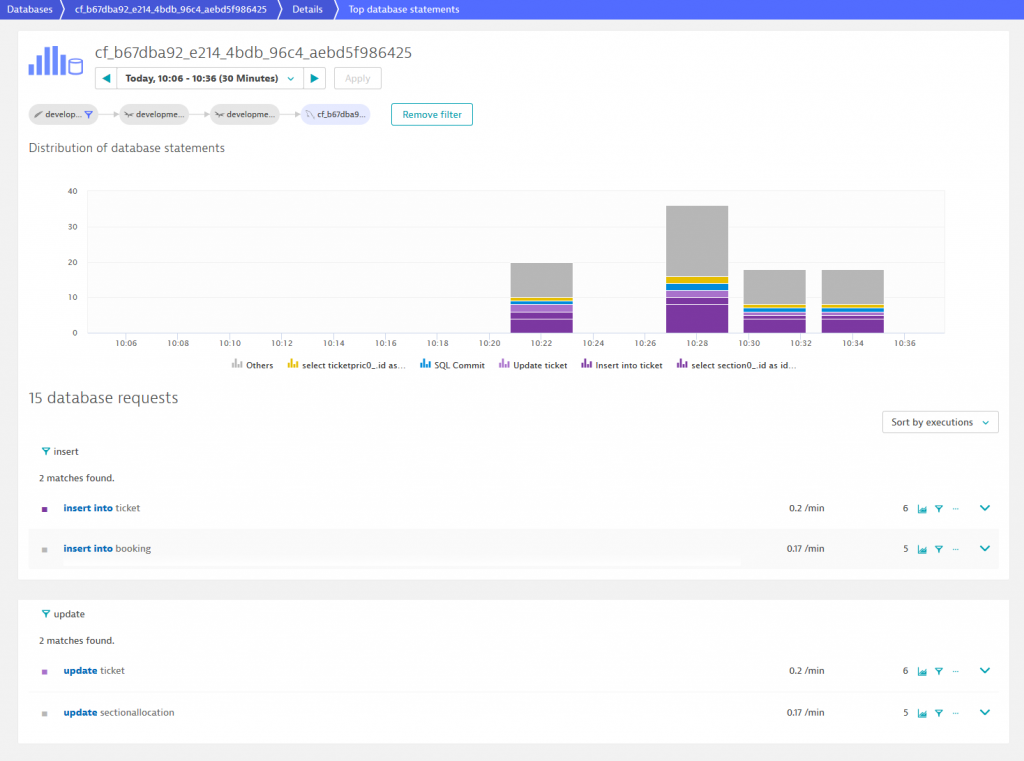
To explore the data model of OrdersService, we can reconsider TicketMonster’s ServiceFlow in Dynatrace. The ServiceFlow depicts a database entity at the end of each flow indicated by the MySQL icon. By following the path through OrdersService, we see a MySQL entity that collects all statements OrdersServices fires to a database. To list them all, just click on the database and then on View database statements. There we can see that OrdersService interacts with multiple tables but performs insert and update queries just in the tables Booking, Ticket, and SectionAllocation. Given this information, we know that new data must be stored in one of these three tables defining the data model of OrdersService.
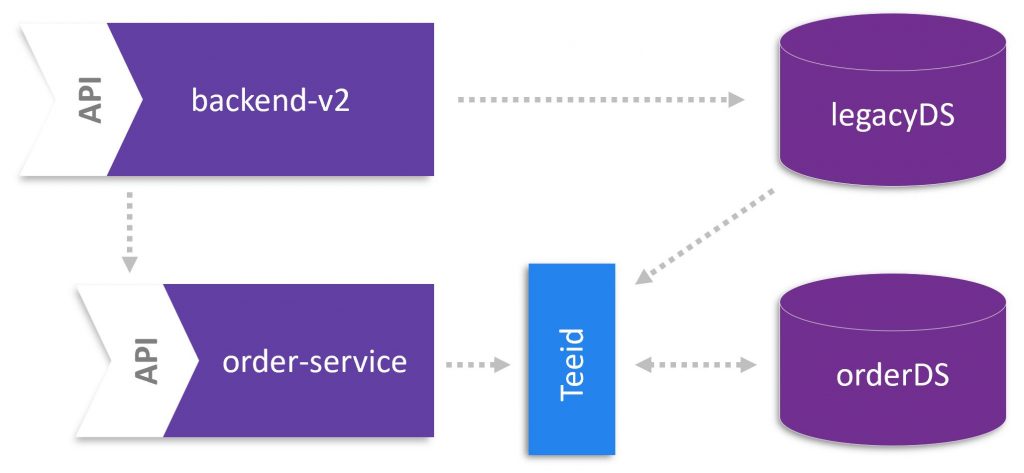
By investigating the select queries of OrdersService, we can logically expand the data model to a domain model that shows the entire information needed from a use case perspective. To implement this domain model, we follow Christian’s approach and use the open source project Teiid. Originally, Teiid was designed as data federation software with the ability of combining multiple data sources to a single virtualized view. In our context, Teiid helps reducing the boiler plate of munging the data model into a domain model by logically combining the database of the monolith and microservice.
At this point it should be noticed that we analyzed just a certain time frame for deriving the relevant tables of OrdersService. This may work for our TicketMonster, but in a real-world scenario, the database utilization needs to be observed for a longer period.
Extract OrdersService from the Backend
Before we get started working on OrdersService and its domain model, we build a starting point that lets us work independently from the current deployment. First, we copy the backend-v1 folder and rename it to backend-v2. This is done for the sake of simplicity, although branching the code base would be a more professional approach.
Second, we extract OrdersService from the new backend version. Therefore, we create a new project orders-service representing our microservice. Given this project, we have to cut out the class containing the method ../ticketmonster/rest/BookingService /createBooking, which we identified as entry point for our microservice. Building the project with just this class will of course fail, because it is missing additional abstractions from the backend. This is the point where we must identify all classes related to the class of the createBooking method. To see a successful extraction of OrdersService, please look at the project orders-service on GitHub. Besides, the project contains a MySQL script to create the database (data model) for our OrdersService.
Utilize Teiid for Data Virtualization
Let’s just briefly restate the upcoming challenge. We leveraged Dynatrace to identify the tables that are used by OrdersService to store data. In other words, these tables represent the data model for our microservice. Moreover, some data need to be read from the monolithic application building the domain model for the microservice. To extend the data model to the domain model, Teiid and especially the extension Teiid Spring Boot will help us.
The technical details to add the Teiid Spring Boot dependencies to OrdersService are summarized on GitHub in orders-service. After adding the dependency, the next step is the definition of the two data sources in ./src/resources/application-mysql.properties and in ./src/config/TeiidDataSources.java. As shown in the configuration snippet below, the place holders legacyDS and ordersDS are referencing our two data sources.
application-mysql.properties
spring.datasource.legacyDS.url=jdbc:mysql://host-name:3306/ticketmonster-mysql?useSSL=falsespring.datasource.legacyDS.username=ticketspring.datasource.legacyDS.password=monsterspring.datasource.legacyDS.driverClassName=com.mysql.jdbc.Driverspring.datasource.ordersDS.url=jdbc:mysql://host-name:3306/orders-mysql?useSSL=falsespring.datasource.legacyDS.username=ticketspring.datasource.legacyDS.password=monsterspring.datasource.legacyDS.driverClassName=com.mysql.jdbc.Driver |
Targeting the Data Model – Update & Insert Queries
As mentioned above, OrdersService is supposed to persist processed bookings. To tell the Teiid framework where to store data, we add the “@InsertQuery” annotation to, for instance, the Booking entity of OrdersService. This annotation specifies the insert query that points to the database of OrdersService as specified by ordersDS.
@InsertQuery("FOR EACH ROW \n"+ "BEGIN ATOMIC \n" + "INSERT INTO ordersDS.booking (id, performance_id, performance_name, cancellation_code, created_on, contact_email ) values (NEW.id, NEW.performance_id, NEW.performance_name, NEW.cancellation_code, NEW.created_on, NEW.contact_email);\n" + "END")@Entitypublic class Booking implements Serializable { ... |
Targeting the Domain Model – Select Queries
To use the power of Teiid for mapping the legacy data source and the domain model of the microservice, a “@SelectQuery” annotation specifies the data sources for an entity in OrdersService. For example, an entity Ticket can come from the legacy or the miroservice’s database. The example below illustrates how to realize the mapping by a union of both tables (i.e., legacyDS and ordersDS) to a single view.
@SelectQuery ( "SELECT id, CAST(price AS double), number, rowNumber AS row_number, section_id, ticketCategory_id AS ticket_category_id, tickets_id AS booking_id FROM legacyDS.Ticket " + "UNION ALL" + "SELECT id, price, number, row_number, section_id, ticket_category_id, booking_id FROM ordersDS.ticket")@Entitypublic class Ticket implements Serializable { ... |
If we have the proper teiid-spring-boot mapping annotations, this spring-data repository will understand our virtual database layer correctly and just let us deal with our domain model as we would expect.
Conclusion and Outlook
To recap this blog post, virtualizing the domain model of our microservice using Teiid is not the final state of a successfully decoupled service. However, this point-in-time solution gives us feedback regarding the domain model of the service without writing much boiler plate code.
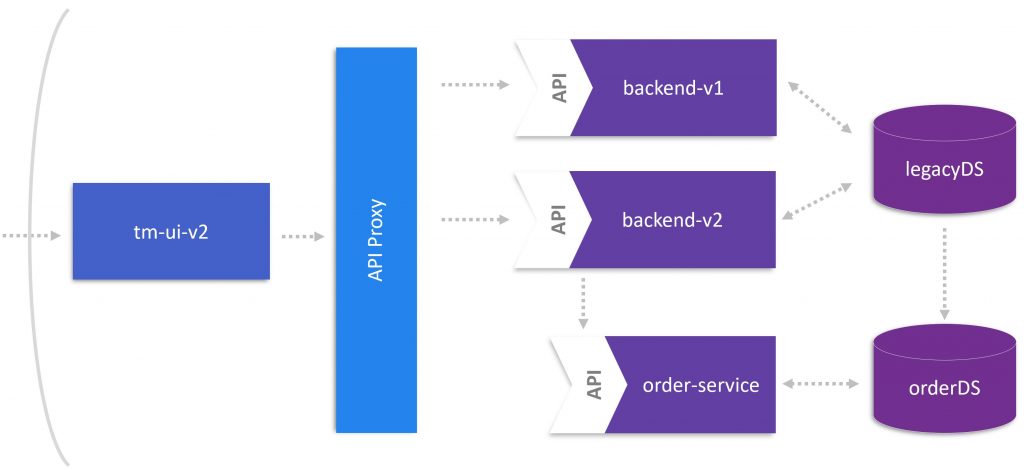
At this stage of our journey, we have an implementation of our OrdersService that has its own API and domain model, which is virtualized based on the monolith’s and its own data model. In the next blog post, we will apply approaches we have learned so far as well as new approaches for deploying the microservices. Be ready, our first microservice will get launched!



Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum