
|
Johannes Bräuer Guide for Cloud Foundry |
Jürgen Etzlstorfer Guide for OpenShift |
| Part 1: Fearless Monolith to Microservices Migration – A guided journey | |
| Part 2: Set up TicketMonster on Cloud Foundry | Part 2: Set up TicketMonster on OpenShift |
| Part 3: Drop TicketMonster’s legacy User interface | Part 3: Drop TicketMonster’s legacy User Interface |
| Part 4: How to identify your first Microservice? | |
| Part 5: The Microservice and its Domain Model | |
| Part 6: Release the Microservice | Part 6: Release the Microservice |


In the first article of this series we have introduced the problem of a monolithic application and the idea to break it into microservices. In this article, we will take a look at the demo application and how to set it up on the Openshift platform. Then we will take the first step of extracting the user-interface from the monolith, to have it prepared for the following steps.
To follow along the conceptual steps in this blog article, there is also a GitHub repository containing all needed sources for our journey. For this article, we will need three sub-projects that are both inside the main repository:
Please note that as a prerequisite, you have to provide your own OpenShift cluster. Please make sure you deploy the Dynatrace OneAgent operator of your cluster, to enable full-stack monitoring for all services running in OpenShift.
Lift and Shift TicketMonster to OpenShift
During this blog series we will apply the Strangler pattern amongst other best practices to extract microservices from the monolith. Therefore, it is convenient for us to have the monolith running on the same platform as the newly created microservices will live on. Although in a real-life scenario, the monolith will be deployed already in a private data center or a private/public cloud, for our showcase we will first take some effort to lift and shift it to our target platform OpenShift. This will also let us gain some experience with the OpenShift platform that will come in handy in the course of this project. We will also make use of Dockerhub, which will be the hub for our deployable images, thus, a Dockerhub account is needed if you want to deploy your own images instead of reusing the provided ones.
For the deployment of TicketMonster to OpenShift, we first have to create its own project where all our artifacts will reside. Next, a MySQL service is needed since the TicketMonster needs to store information on events, venues and bookings in a central database. Simply add your database connection string to the monolithic TicketMonster and you are good to go with your deployment. Since in a real-life scenario we might have additional resources like a load-balancer or a proxy in front of the TicketMonster application, we also deploy a proxy webserver in our scenario.
As a final result, we will have 3 services available in OpenShift. Once again, you will find detailed deployment information and scripts in the provided GitHub repository.

We can decide to expose the monolith-proxy to the public by creating a public route for it in OpenShift and it will serve as our entrypoint for the monolithic TicketMonster application.
Once we hit the monolith with traffic, we can already see detailed information in Dynatrace, thanks to its capabilities in OpenShift monitoring. Pro-tip: use the Dynatrace OneAgent Operator to deploy the OneAgent in your OpenShift environment.
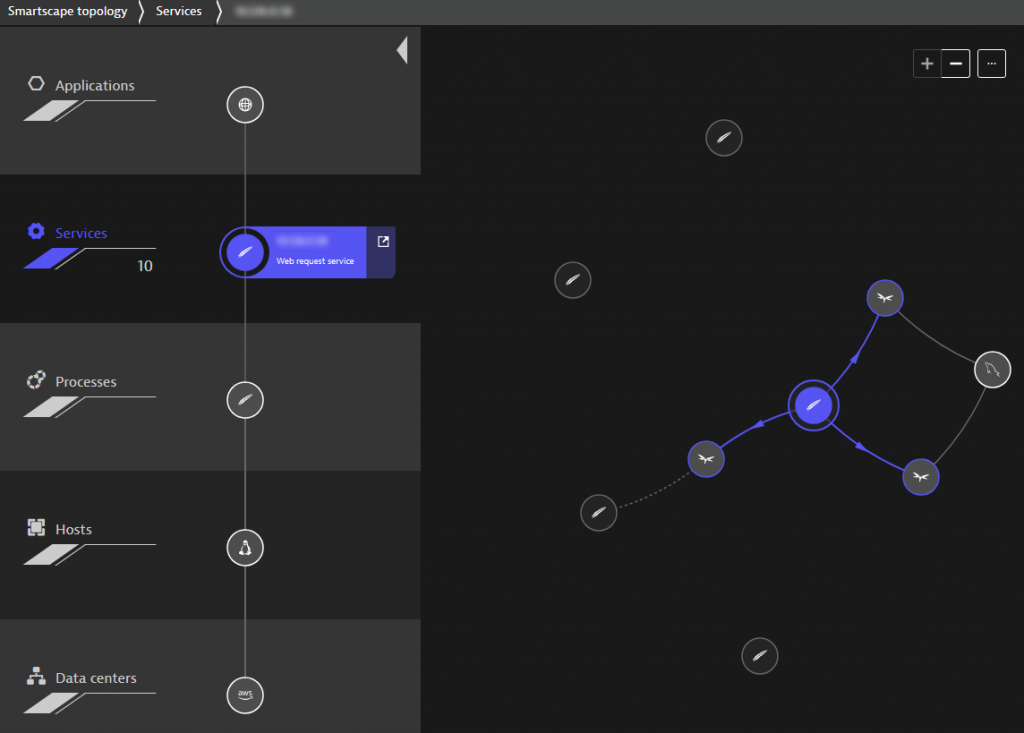
Once we hit our application with some real-user traffic and thanks to the Dynatrace SmartScape technology, we can see our complete environment along both a vertical and horizontal axis, meaning we can investigate our environment from a perspective of having Applications, Services, Processes and Hosts on top of each other running in a Data center. What we can also see are the inter-connections on a specific layer, as for example which Services communicate with each other as shown in the picture above. Without digging into detail, we already have a general understanding which technologies are involved and if and how they are connected to each other. For example, we can see that our Apache proxy (highlighted) does not directly communicate with the MySQL database, but instead has a direct communication with other services running on JBoss Wildfly that are instead communicating with the database.
We can further drill down and take a look at the service flow to get insights how data traverses through our application.
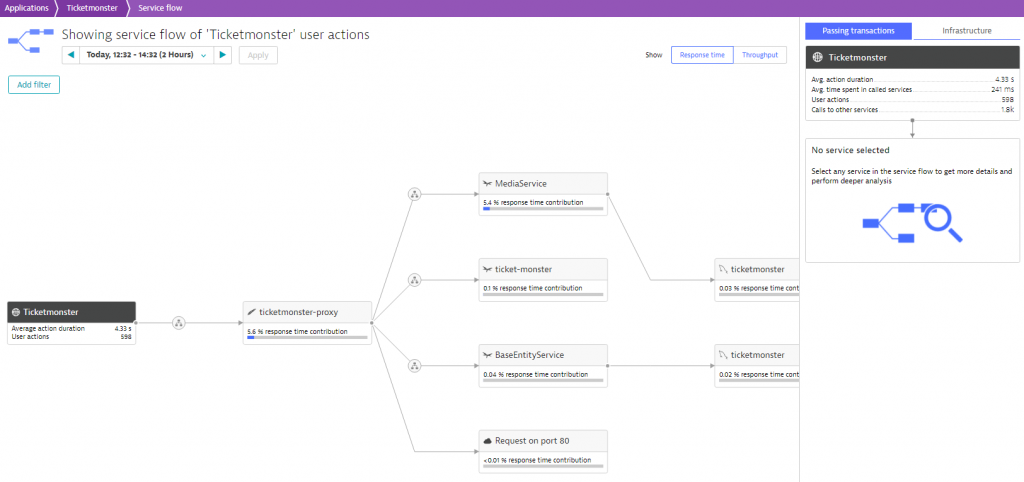
As we can see in this picture, the data flow starts at the very left in our TicketMonster application and includes the ticketmonster-proxy as well as other services all the way back to the database. It is worth mentioning that although the Ticketmonster is a monolithic applicaton, Dynatrace already identifies and exposes different services like the MediaService and the BaseEntityService.
Getting the monolith ready for bigger adventures by decoupling the UI
Since our final goal of this blog series is to break up the monolith into microservices, we have to start by decoupling the UI from the rest of the monolith, which has proven to be a best practice and common starting point. The purpose of this is to decouple the client facing part from the business logic and to communicate only via APIs between these two. Another important fact is that once the UI is decoupled from the monolith, it can be maintained independently. This further means, that development and deployment for the UI and for the monolith are separated, thus gaining more flexibility and decreasing build and deployment times significantly. This also goes along with the requirements on a “12-factor-app” which is a catalogue of criteria that should be implemented by a modern microservice to be cloud-native.
With this in mind we have our own sub-project in our repository for the first version of the UI. This sub-project only consists of all UI relevant data, i.e., HTML, JavaScript and CSS files, without the business logic written in Java. Eventually, we can deploy the UI in it’s own container running an Apache webserver. However, we have to make sure, that calls to the monolith are routed correctly. Therefore, we adjust the httpd config file:
# proxy for backend of TicketMonster ProxyPass "/rest" "http://ticket-monster.YOUR-SYSTEM-DOMAIN.com/rest" ProxyPassReverse "/rest" "http://ticket-monster.YOUR-SYSTEM-DOMAIN.com/rest"
Doing so, we can now deploy this Docker image on OpenShift to put the UI in its own service and in front of the monolith.
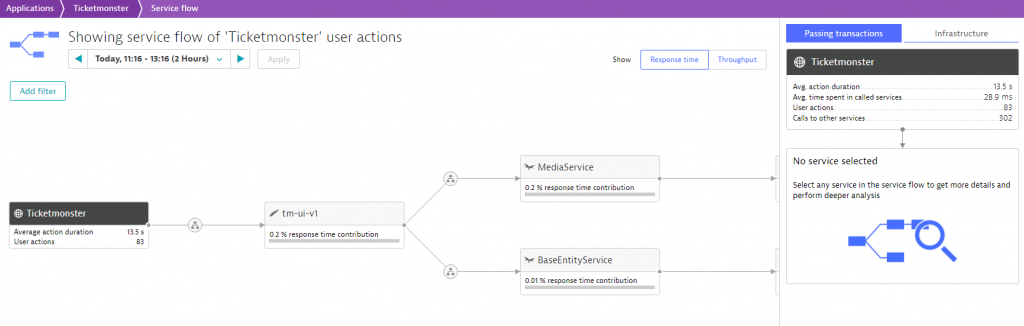
In Dynatrace, we also have evidence of the decoupled UI and monolith by taking a look at the new service flow:
Summary & Outlook
Summarizing, in this blog post we have learned how to set up our monolithic TicketMonster application in our target platform OpenShift and we have taken a first step in preparing it for breaking it up into microservices.
Although we have successfully decoupled the UI from the monolith, it is not recommended to release the newly decoupled service to all end users immediately. Instead, we want to release it to a small user group at first and if we don’t see any errors we incrementally increase the amount of users that are routed to the new UI. Therefore, in the next blog article we will make use of OpenShifts routing mechanisms and will learn how to enable canary releases for our scenario.



Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum