
DevOps is now a mandatory CIO initiative, and would be hard to dismiss it as a short-term trend. It is a proven competitive differentiator to help increase speed to market, increase operational efficiency, and lower costs, and a large majority of companies and industries are getting on board. To confirm my statements let’s look at the latest State of the DevOps Report which Puppet and DORA announced at DevOps Enterprise Summit 2017 in London. The report reveals that the number of organizations investing in DevOps increased by 68% (from 16% to 27%) in the past three years. This is also reflected by Gartner, positioning DevOps in the Top 3 CIO Initiatives:

Whether you are already running “full steam ahead” on your own DevOps journey, or are still evaluating what DevOps really means for your organization, let me share some of the insights I gained in recent months while engaging with DevOps practitioners, customers, and performance experts at conferences and meetups around the world.
DevOps Days Conferences & DevOps Meetups
Some of my favorite DevOps communities can be found at DevOpsDays or at local DevOps Meetups. In May, I was fortunate enough to present our own Dynatrace DevOps Transformation story at DevOpsDays Toronto. Special thanks go to Ashton Rodenhiser for capturing my presentation in this beautiful piece of art:
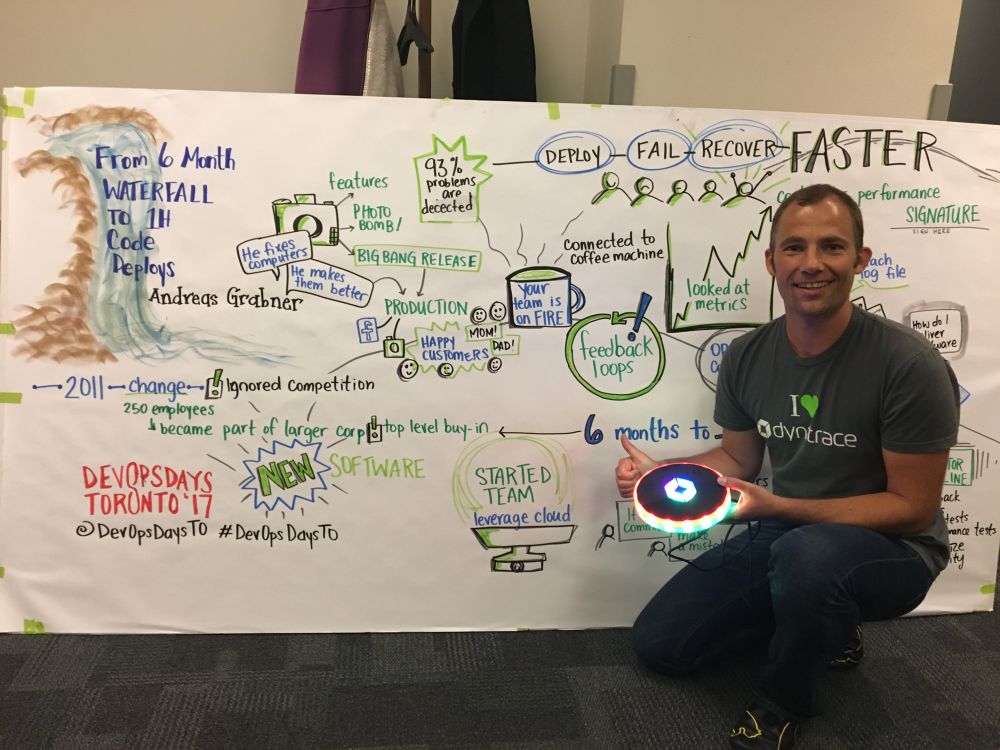
DevOpsDays Toronto, and more recently the DevOps Enterprise Summit (DOES) and Velocity, were very enlightening to me. Not only because of the great talks and information sharing, but because of several Open Spaces sessions in which I participated where DevOps driving factors, best practices and challenges – including struggles and frustrations – were discussed openly.
Driving Factors for DevOps Adoption
Lets start with a quick reminder on why organizations drive DevOps adoption:

Most of these reasons are rather obvious, and are always on the list if people talk about their reasons for DevOps adoption. I thought that Employee Retention was a very interesting one, particularly because we are all involved in an industry that battles for good technical talent.
DevOps Adoption Challenges
While the reasons for DevOps adoption are “common sense”, the implementation and transformation that often come with it creates big challenges and complexity. This can make people question whether DevOps is worth it.
What follows here is a list of common challenges that I compiled after DevOpsDays in Toronto, mainly from Open Space sessions that I attended. Let’s take a look.

Technical Complexity
“Choose the technology that solves your problem – but don’t let your technology dictate what problems to solve, or how to solve them!”.
I love this “DevOps practice” because it allows individual engineering teams to deliver their app or service faster. That’s cool. But if 10 different (micro)service teams pick ten different technologies you end up with huge technology diversity and complexity across your organization. That’s tricky, because this complexity must be managed by the Ops-side of DevOps who are responsible for production. And it is the production environment where all these moving pieces must work together in unison. Unfortunately, it is often in production where these pieces end up being deployed together for the first time. Before that point in time these code changes “only” make it through the individual pipelines and often only get tested in separate, mocked up or scaled down pre-prod environments.
At DevOpsDays Toronto we had a slight majority of Ops roles in the audience as compared to Dev. The frustration about this new technical complexity was LOUD AND CLEAR!!
Bad Quality
“Faster-to-market” is one of the primary competitive business drivers for DevOps adoption.
Backed by the numbers from the State of DevOps Report we see that low performers are in fact catching up with Speed-of-delivery (“faster-to-market”). Low performers are, however, falling behind on quality which is reflected in much higher Failure Rate per Deployment and Mean Time to Recover.
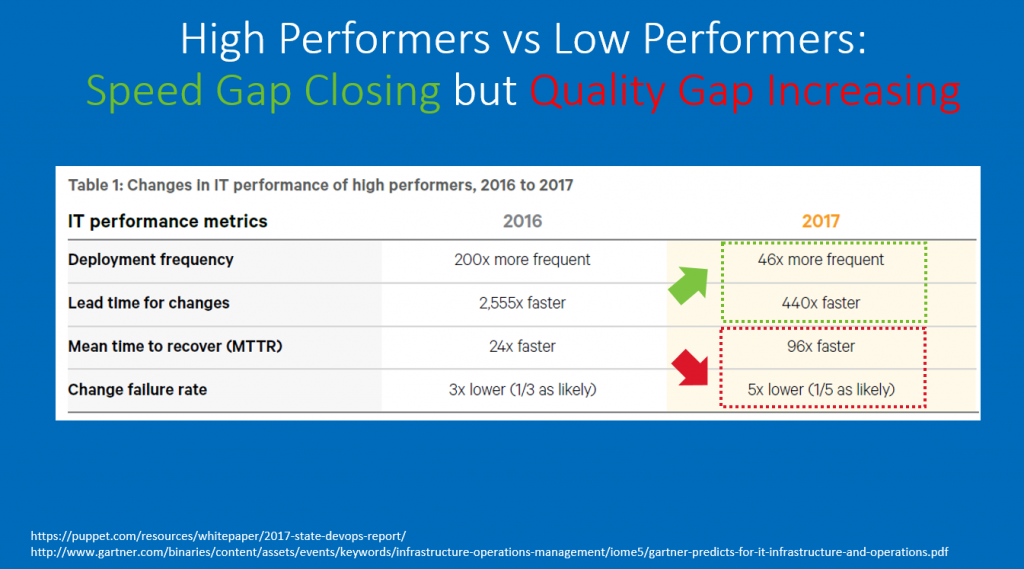
This means that not only is business impacted, but your end users are getting frustrated due to bad deployments and downtime of your services. It also means that Ops and Dev teams spend more time firefighting and fixing, which takes away time from innovation.
Therefore, THE REAL DevOps adoption driver Should BE: “Faster Quality to Market” as it is the more sustainable long term strategy!
Alert Drowning
The combination of technical complexity and bad quality is a perfect storm combination for what I call “Alert Drowning”. What is that exactly?
To explain this more clearly, let me paraphrase one of the Ops engineers in one of the Open Spaces who said: “On average I get about 8000 alert emails from our many monitoring tools. I am drowning in them and, on top of that, most of them are not actionable. They all end up in a special email folder I hardly ever look at.” He continued: “Last month I missed one of these critical alerts. I didn’t get to see it until last week when business was asking me about the lower conversion rates they had just observed. For 3 weeks, we had NO CLUE that we had a technical issue impacting business. That was NOT GOOD!”
This story was echoed by others in the room as well as complaints on all the different monitoring tools, for many different technologies, that they must support. Individually these tools detect volumes of isolated tech stack specific problems that are most often not related to any critical problem impacting the real user. This results in Ops drowning in the “noise” of alerts and often missing real problems.
A “wish list” would condense it down to “Actionable Alerts”!
Disruption of Traditional Ops
Looking at some of the DevOps practices from a developer’s perspective it appears like DevOps is just rolling out agile principles to the whole delivery pipeline. The core principles of smaller iterations, automation and feedback loops, is not all that new for developers. The rate of change, which is constantly increasing, is what development teams have been measured by anyway as, for example, stories-per-sprint, or features-per-release.
Traditional Ops on the other side, are measured by uptime and availability (classical 99.999%), which is now jeopardized due to the increased velocity in deployments, as well as technology diversity. If you take all of this into consideration, and look back to the topics discussed above, technical complexity, bad quality, alert drowning, it is no surprise that traditional Ops feels like it is getting disrupted the most. And, they feel like being left alone to fix all the mess that Dev(Ops) left behind!
We as an industry and DevOps community need to work on taking away that fear. DevOps collaboration between Dev and Ops (and everyone else involved: business, security, quality, etc) is the foundation. We must:
- Build new architectures on top of new scalable platforms that are failure resilient by default
- Involve Ops early in the delivery process to re-use Ops Best Practices in every pipeline phase
- Collaborate on finding ways to safely innovate faster without failing more often
Dynatrace Addresses Challenges through Monitoring
Within our own Dynatrace DevOps transformation we struggled with all the problems I’ve identified here. We knew that monitoring could solve some of the technical challenges that our Ops team was struggling with, but the monitoring we had when we started our transformation wasn’t where we needed it to be. So we took an opportunity to develop a modern monitoring approach while going through our transformation. We shaped the technology to the needs of today’s software delivery pipelines. Our team believes that it can also greatly benefit all our customers in their transformation journey, too.
If you are looking to find a solution to similar problems, I’d encourage you to test drive our monitoring solution and see for yourself, sign up for our Dynatrace SaaS Trial – or contact us to request a Dynatrace on-premises trial.
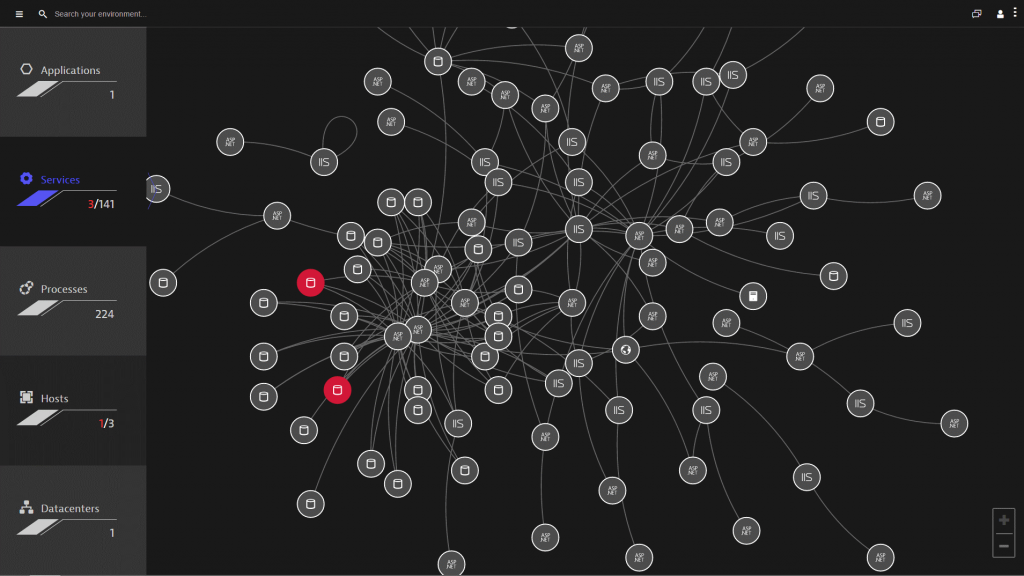
OneAgent Full Stack Support to address Technology Complexity
Instead of installing different agents for different technologies (Java, .NET, PHP, Node.js, Go, Lambda) different platforms (CloudFoundry, OpenShift, Azure AppFabric, AWS Beanstalk) and different stacks (AWS, Azure, VMWare, Docker, OpenStack, Google Cloud) you ONLY install a single agent on a host: Dynatrace OneAgent!
AI-based Quality Gates to address Bad Quality
Shift-Left is not only for testing but also for true for Monitoring. Therefore, Dynatrace integrates into your Continuous Delivery Pipeline and analyze performance, scalability and architectural regressions as soon as developers commit code. Fully integrated with your Jenkins, Bamboo, Bitbucket, AWS CodePipeline, TFS or other CI/CD Tools you can stop bad code changes earlier.
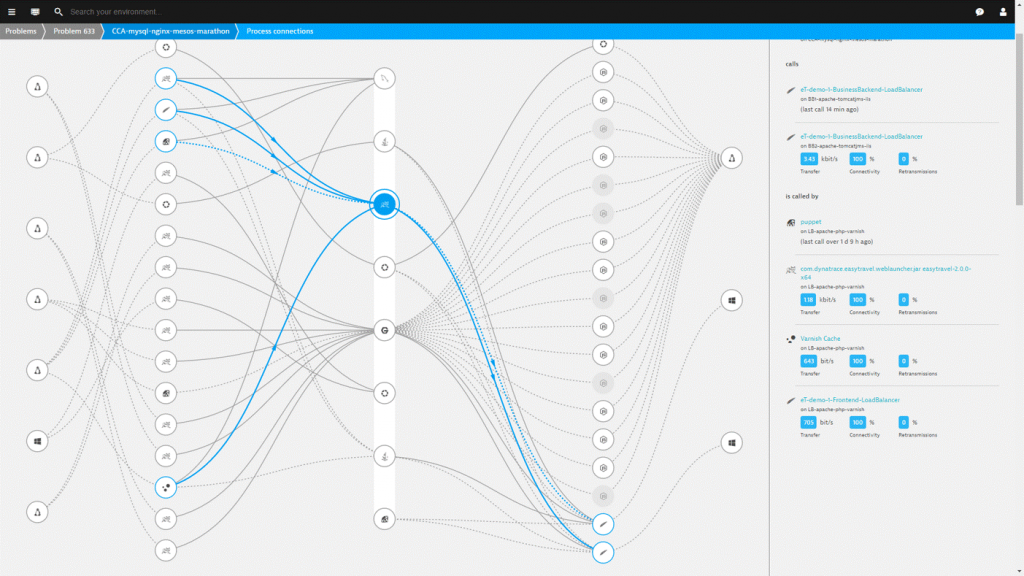
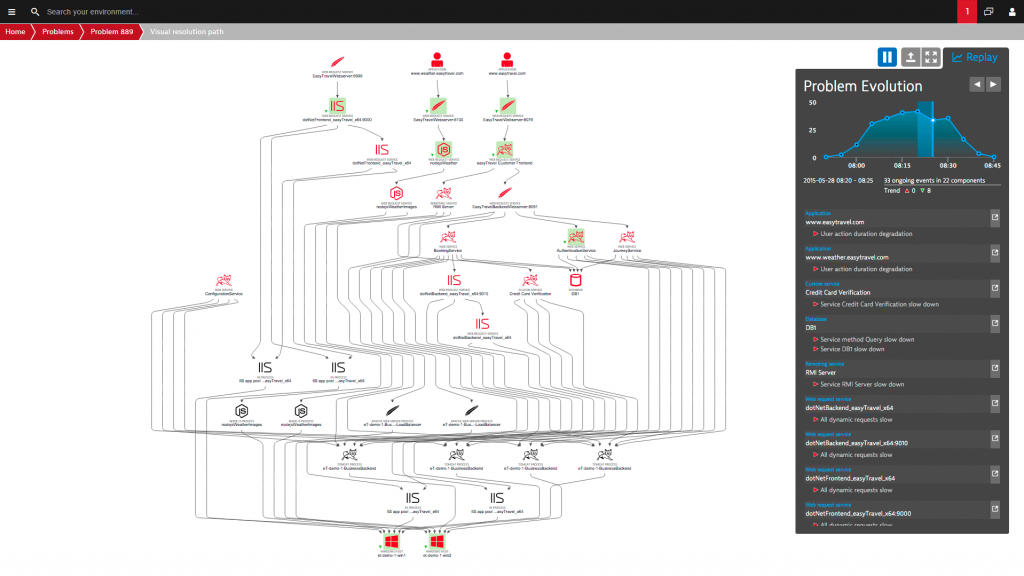
AI-Driven Root Cause Analysis and Remediation to address Alert Drowning
Instead of hundreds of individual alerts in a failing microservices environment, Dynatrace Artificial Intelligence automatically executess all the event correlation and causation for you. In case of a real problem that impacts your real users or SLAs you get notified via ChatOps (Slack, HipChat, Teams), analyze the root cause and evolution of the problem via VoiceOps (Alexa, Cortana) or the Web UI, and can even trigger auto-remediating actions based on all the collected technical evidence:
Sharing more thoughts …
If you want to hear more of my thoughts on these topics, you can watch my on-demand webinar on DevOps: Cultural and Tooling Tips from Around the World.
I am always looking forward to learning more about adopting best practices from small startup to large enterprise. So, if you see me in the hallways at an event or conference, or sitting next to you at a meetup, feel free to tap my shoulder and tell me what your DevOps experiences are!
Another way to get share information is through @grabnerandi or LinkedIn!.




Looking for answers?
Start a new discussion or ask for help in our Q&A forum.
Go to forum